前回の記事 では、Qwen3 の MLX 版と Ollama (GGUF) 版の速度比較を行いました。結論として、MLX 版の LLM のほうが速いということがわかりました。
その後も主に MLX-LM で LLM を使っているのですが特に不具合も無く、なんなら慣れてしまえばとてもヨイということがわかってきました。というわけで本記事でやり方を一通り共有します。現在 Ollama を使用中で MLX-LM はまだ触っていない、という方が対象になるかと思うので、所々で Ollama との比較を入れていきます。
フロントエンドとしては、ボクは Dify をメインで使っていますが、よりお手軽な Open WebUI での使い方にも触れます。
書いていたら大作になってしまったので、気になるところだけでも覗いてみてください。
↑前回の MLX-LM vs Ollama 的記事 なぜ MLX-LM を使うのか
MLX-LM を使う理由は、MLX は Apple が開発している機械学習フレームワークなので Apple ハードウェア (M1~M4 等の Apple シリコンシリーズ) に最適化されており、単純に LLM の実行速度が Ollama (GGUF モデル) より速いからです。前回の記事で調べてみてはっきりとわかりました (量子化の違いもあり性能差はあるのでしょうが、それすら MLX のほうが上という調査結果もあります)。
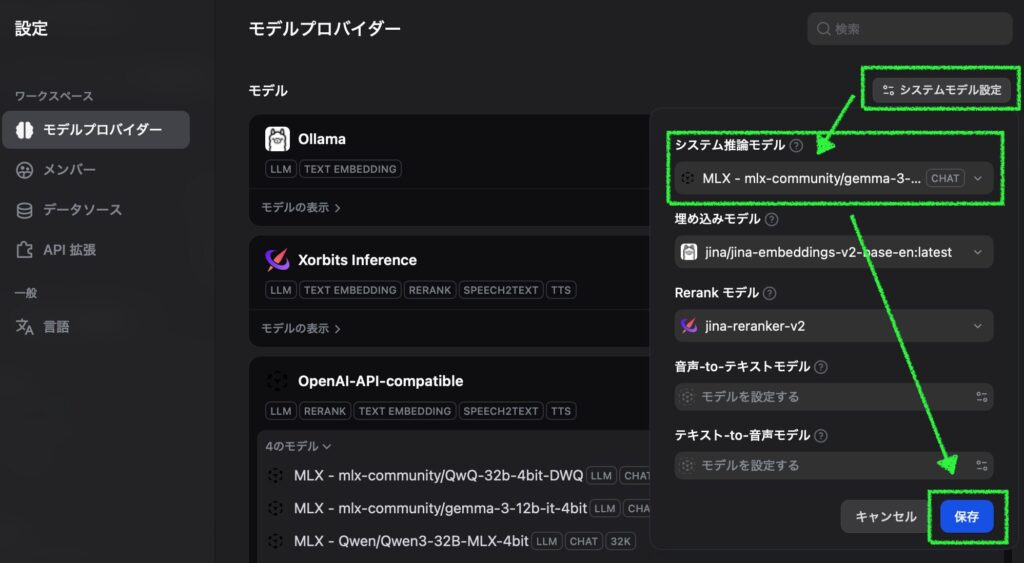
実は Dify で MLX-LM を使い始めた当初、システム推論モデルとして Ollama のモデルを使用していました。すると、最初のチャットの後サマリ (タイトル?) の生成に Ollama のモデルが使われ、メモリの使用量が高止まりするような状況が頻発しました。それで MLX-LM はまだ実用には向かないと勝手に思い込んでいたのですが、Dify のシステムモデル設定で推論モデルも MLX の小さなモデルに変更したところ、チャットサマリ生成後もメモリプレッシャーがキレイに下がることがわかりました。MLX-LM だけを使用することで無駄にメモリが占有される問題は解消です。
また、サーバの起動やモデルのダウンロードで必要な長めのコマンドも仮想環境専用のaliasを登録することで解消できて、運用の手間が大幅に下がったことも大きいです (使い慣れている Ollama ではまだ MLX のモデルが使えないので仕方なくなんとかした、とも言えますけど) サーバ自体の起動も速いので、一度落としてあげ直すのも苦痛じゃないです。
MLX で LLM を動かすだけなら LM Studio という選択肢もあります。モデルの検索からダウンロード、テキストのチャット、ビジョンモデルに画像を認識させる、OpenAPI コンパチの API サーバを立ち上げる、等など様々な機能が利用できます。が、全部盛り過ぎてアプリケーション自体が重いのと、モデルを読み込むとその分メモリを占有し続けるのが個人的には気に入らないです。ネット上では、ボクはあまり気にしていませんが、プロプライエタリ (クローズドソース) だからダメだ、なんて論調もありますね。逆に「自分は LM Studio が好き、LM Studio で MLX のモデルを使う」という方はこれ以上読む必要はありません。LM Studio は使わないという人向けの内容です。
MLX-LM モデルの量子化について
新しめの MLX-LM には Learned Quantization (学習済み量子化?) という機能が導入されています。これまでの、全体を画一的に 8-bit や 4-bit に量子化するのではなく、より効率的に量子化を行うことで、結果としてモデルのサイズを小さくしたり、性能の劣化を小さくしたり、推論速度を上げたり、ということができるようです。Hugging Face ではDWQ、AWQ、Dynamic等とモデル名に付いているものがこれらのテクニックを使って量子化されている事を示しています。詳細はこちら (公式):
https://github.com/ml-explore/mlx-lm/blob/main/mlx_lm/LEARNED_QUANTS.md
ボクも 32GB RAM の M2 max で google/gemma-3-12b-it の Dynamic-quant を数回チャレンジしてみたのですが、おそらくメモリ不足で macOS がクラッシュしてしまい、諦めました (量子化作業にはpip install datasetsが必要でした)。上の公式以外では詳細について書かれている記事などもほぼ見当たらず、今後に期待ですね。
モデルの選定
Mac の GPU に割り当てる VRAM 容量を増やし たり、モデルに最適な量子化が行われていたりしても、それらはより大きなパラメータサイズを使えるようになるほどの効果は期待しづらいです (32B を 70B にとか 4-bit を 8-bit に等はキツい)。なので、これまで Ollama で使っていたモデルの同レベルの量子化バージョンが、より速く低劣化で動き、より大きなコンテキスト長が使えるというのが MLX-LM モデルの大きなメリットになると思います。
モデルを選定するには、慣れないうちは LM Studio で MLX のみにチェックを入れて使えそう (Full GPU Offload Possible) なモデルを見つけて Model (例: deepseek/deepseek-r1-0528-qwen3-8b) をコピーし、後述するコマンドでダウンロード、というのが良いと思います。慣れてきたら Hugging Face で “mlx gemma-3” 等と検索するのが早くなると思います。
下の記事ではより詳細に自分の RAM (ユニファイドメモリ) のサイズに合わせたモデルの見つけ方を説明しています。(英語ページが開いてしまったら、右の「日本語」をクリックしてください)
今回は MLX-LM に変換・量子化されたモデルを対象とした記事ですが、そもそもの LLM の性能差などを調べるのは、各種リーダーボードを見るのが良いでしょう。ボクは最近もっぱら↓のサイトで性能差を見ています。
https://artificialanalysis.ai (オープン、クローズド、複数選んで比較できます。新しいモデルが追加されるのも早い)
試した環境
Mac Studio M2 Max 32GB GPU (24,576 GB を VRAM に割り当て済み。OS 標準以上の容量を GPU に割り振る方法はこちら )
macOS : Sequoia 15.5Python 仮想環境: pipenv version 2025.0.3 (なぜ pipenv なのか、みたいな話はこちら )
Python: 3.12.11 (特に意味は無し。brew install [email protected] でインストール)
MLX-LM: 0.25.2 (pip install mlx-lmでインストール)
Open WebUI: 0.6.15 (pip install open-webuiでインストール)
Dify: 1.4.2 (LAN にいる別の Mac mini M1 にインストール。やりかたはこちら )
Ollama: 0.9.2 preview (Ollama 新アプリのプレビュー版。比較用に。詳しくはこちら )
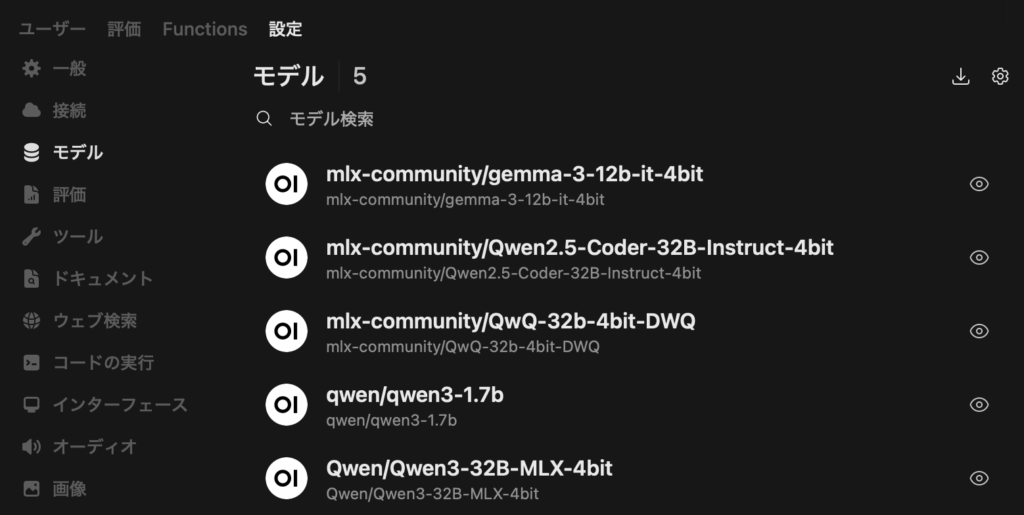
LLM: Qwen/Qwen3-32B-MLX-4bit (17.42 GB / メインで使う LLM)
LLM: mlx-community/gemma-3-12b-it-4bit (8.07 GB / Dify のシステム推論モデルとして使用)
RAM が 32GB より小さい場合は LLM も性能がそれなりのものしか使えないので、正直実用的なローカル LLM 環境を作るのはキツいと思います。48GB 以上あれば Dify 含めて全て同一 Mac で動かせると思います。
仮想環境を作る
Python の仮想環境は、最低限 MLX-LM 実行用に一つ必要です。Open WebUI を新たにpipで導入する場合には専用にもう一つ作ったほうが良いと思います。お好みの仮想環境ツール+上記pipコマンドで作ってください。
もし新規で Dify をインストールする場合は Docker が必要となりますので、公式 や過去記事 を参考に構築してください (CPU >= 2コア、RAM >=4GB の割り当てが必要)。
(蛇足) ボクはあまり人気が無いらしいpipenvを使ってます。仮想環境内だけで有効になるaliasを使って長くなりがちなコマンドを簡単に実行しています。特にこだわりや縛りの無い方はお試しあれ。(英語ページが開いてしまったら、右の「日本語」をクリックしてください)
pipenv内専用のaliasについてもう少し触れておくと、仮想環境のルートディレクトリに置いた.zshrc.localファイルに下記のように書き込んでおけば、pipenv shellで環境に入ったときだけmlxsvで MLX-LM の API サーバを実行でき、モデルのダウンロードはdownloadの後に Hugging Face のモデルを指定するだけで実行できるので便利です (例: download mlx-community/gemma-3-12b-it-4bit)。詳細は上記記事をご覧ください。
(2025/09/07 コマンドアップデート)
alias mlxsv = 'mlx_lm.server --host 0.0.0.0 --port 8585 --log-level DEBUG' alias download = 'HF_HUB_ENABLE_HF_TRANSFER=1 hf download' .zshrc.local MLX-LM 仮想環境でモデルをダウンロード&動作確認
mlx_lm.generateコマンドを使ったモデルのダウンロード方法をよく見ますが、やっているのはollama runコマンドでモデルをダウンロードしてチャット開始するのと近く、ダウンロード後にテキストの生成が行われます (チャットでは無く、生成のみ)。ollama pullのようにシンプルにモデルをダウンロードするだけであれば、Hugging Face のコマンドをインストールして使用するのが良いでしょう。というわけで、まずは MLX-LM 用に作った仮想環境に入ってから Huggng Face 関連コマンドをインストールします。
pip install -U huggingface_hub hf_transfer Zsh 次に、普通にやるより速いらしい以下の方法でモデルをダウンロードします (上記のaliasを設定済みであればdownload Qwen/Qwen3-32B-MLX-4bitで OK です)。モデルはお好みでどうぞ。(2025/09/07 コマンドアップデート)
HF_HUB_ENABLE_HF_TRANSFER = 1 hf download Qwen/Qwen3-32B-MLX-4bit Zsh 動作確認はmlx_lm.chatコマンドでターミナルから行えます。下記例では最大トークン数をデフォルトより増やしています (Qwen3 のような thinking/reasoning モデルだと考えているうちに最大トークンに達してしまう)。
mlx_lm.chat --model Qwen/Qwen3-32B-MLX-4bit --max-tokens 8192 Zsh MLX-LM と Ollama との CLI チャット機能比較: mlx_lm.chatコマンドはあまりイケてません。ollama runコマンドのようにチャットを始めてから設定を変更したりはできませんし、いくつか改行するつもりでエンターキーを叩くと無言のプロンプトが LLM に送られて生成が始まりますし、LLM のテキスト生成を止めようと Ctrl + C するとコマンド自体が停止します (ズコー)。よって、ollama runの様な使い勝手は期待してはいけません。
次のコマンドでは Dify のシステム推論モデルとして設定する mlx-community/gemma-3-12b-it-4bit もダウンロードしています。Dify を使わない方は不要です。ファイルサイズは 8.1GB なので、上で落とした Qwen/Qwen3-32B-MLX-4bit の半分以下の時間で完了すると思います。
HF_HUB_ENABLE_HF_TRANSFER = 1 hf download mlx-community/gemma-3-12b-it-4bit Zsh ダウンロードされたモデルを一覧表示するのは以下のコマンドです:
ところがこのコマンドでは最初にダウンロードしたQwenリポジトリのモデルは表示されません。mlx-communityリポジトリのモデルは表示されます。API サーバを実行すればブラウザからは確認できるので、その方法は後ほど説明します。また、モデル名を指定すれば使用することも可能です。
チャットで使うならこう:
mlx_lm.chat --model Qwen/Qwen3-32B-MLX-4bit Zsh 削除するならこう:
mlx_lm.manage --delete --pattern Qwen/Qwen3-32B-MLX-4bit Zsh モデルは/.cache/huggingface/hub/以下に保存されているため、ファインダーから削除しても問題ありません。
ところで先ほどのmlx_lm.manage --scanでモデルの実サイズは表示されるものの、他の情報は特に確認できません。Ollama では ollama show <modelname>でコンテキスト長や量子化方法等を確認できますが、代わりになる方法は MLX-LM にはありません。必要な場合は Hugging Face のモデルカードを確認するか、LM Studio がインストールしてあれば My Models で確認するか、といったところです。ただしコマンドでダウンロードしたモデルの名前は LM Studio では正しく表示できないので、ダウンロードしたタイミングなどで見分けましょう。モデルの詳細 (メタデータ) を確認する機能はぜひ MLX-LM に追加して欲しいところですよね (LM Studio は MLX-LM を内蔵しているので、同じ事ができると思うんですけど)。
OpenAI API コンパチのサーバを実行する
公式の実行方法 (↓ のリンク) をみるとモデル名を渡しているのでそのモデルしか使えないのかと思っていたのですが、サーバの起動時にモデル名を渡す必要はありません。起動後はクライアントで指定したモデルが利用できます。
https://github.com/ml-explore/mlx-lm/blob/main/mlx_lm/SERVER.md
上のaliasのとこにも書きましたが、ボクが MLX-LM の API サーバを実行するコマンドは以下の通りです。オプションがどれも不要であれば、mlx_lm.serverだけで大丈夫です。
mlx_lm.server --host 0.0 .0.0 --port 8585 --log-level DEBUG Zsh
--host 0.0.0.0 こうするとの他のホストからもアクセスできます (ボクは Dify が別の Mac で動いている ので必須)--port 8585 デフォルトの8080 Open WebUI のデフォルトと被るので変えています--log-level DEBUG プロンプトと速度 (tokens-per-sec = トークン/秒) やメモリの最大使用量が表示されます
コマンドを実行するとほどなく以下の様な画面になり、LLM が使用できるようになります。
% mlx_lm.server --host 0.0.0.0 --port 8585 --log-level DEBUG
UserWarningには、基本的なセキュリティチェックしか行っていないので本番環境での使用は推奨しない、と書かれています。閉じた環境で使う分には問題無いでしょう。
では簡単に、接続できるのかを試しておきましょう。ウェブブラウザで以下の URL を開くと、MLX-LM から利用できるモデルが表示されます。
http://localhost:8585/v1/models
表示例 (Qwen も見えてますね):
{"object": "list", "data": [{"id": "mlx-community/gemma-3-12b-it-4bit", "object": "model", "created": 1751104699}, {"id": "qwen/qwen3-1.7b", "object": "model", "created": 1751104699}, {"id": "Qwen/Qwen3-32B-MLX-4bit", "object": "model", "created": 1751104699}, {"id": "mlx-community/Qwen2.5-Coder-32B-Instruct-4bit", "object": "model", "created": 1751104699}, {"id": "mlx-community/QwQ-32b-4bit-DWQ", "object": "model", "created": 1751104699}]}
こうなれば、OpenAI API コンパチブルサーバに接続できるクライアントから MLX-LM の LLM を利用できるようになります。
サーバの停止とアップデート
アクティビティモニタでメモリメモリプレッシャーを見ていると、まれに黄色く高止まりすることがあります。そんなときは Ctrl + C で一度 MLX-LM サーバを止めて再度走らせるのが安心ですが、高止まりの原因が MLX-LM であれば次のチャットの後には平常に戻ることがほとんどです。他に GPU ヘビーなアプリを使っていなければ、雑に扱っても割と平気です。
アップデートに関しては Ollama のようなアイコンで知らせてくれたり、自動でダウンロードしてくれるような機能はありません。必要に応じてコマンドを叩く必要があります。
pip list | grep mlx # インストール済みバージョンの確認 pip install -U mlx-lm Zsh https://pypi.org/project/mlx-lm (pip パッケージの情報)
もしアップデート後に不具合が出たら、上のコマンドで表示されたインストール済みバージョンに戻しましょう。例えばバージョン 0.25.1 に戻すならこんな感じです:
pip install mlx-lm== 0.25 .1 Zsh Open WebUI から接続する
Open WebUI を実行する
別の Python 仮想環境に Open WebUI をインストールした場合は、以下のコマンドでクライアントを実行できます (公式 ではpipよりuvを強力に推していましたが、ボクは Open WebUI をメインで使わないのでなじみのあるpip使っちゃいました)。Docker で構築した人は飛ばしてください。
オプションで--host (デフォルト: 0.0.0.0)、--port (デフォルト: 8080) の指定も可能です。
(ボクはコマンドを忘れがちなので、.zshrc_localにalias sv='open-webui serve'と書いてきて、svで起動できるようにしています)
しばし待ち、ターミナルにロゴといくつかのINFOが表示されたらアクセスできるハズです (ロゴが収まりきらなかったのでコードブロックで貼り付けました)。
██████╗ ██████╗ ███████╗███╗ ██╗ ██╗ ██╗███████╗██████╗ ██╗ ██╗██╗ ██╔═══██╗██╔══██╗██╔════╝████╗ ██║ ██║ ██║██╔════╝██╔══██╗██║ ██║██║ ██║ ██║██████╔╝█████╗ ██╔██╗ ██║ ██║ █╗ ██║█████╗ ██████╔╝██║ ██║██║ ██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║ ██║███╗██║██╔══╝ ██╔══██╗██║ ██║██║ ╚██████╔╝██║ ███████╗██║ ╚████║ ╚███╔███╔╝███████╗██████╔╝╚██████╔╝██║ ╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝ ╚══╝╚══╝ ╚══════╝╚═════╝ ╚═════╝ ╚═╝ v0. 6 . 15 - building the best AI user interface. https: //github.com/open-webui/open-webui Fetching 30 files: 100 %|█████████████████████████████████████████████████████████████████████████████████████| 30 / 30 [ 00 : 00 < 00 : 00 , 7708 .23it/s] INFO : Started server process [ 84450 ] INFO : Waiting for application startup. 2025 - 06 - 28 19 : 08 : 50 . 198 | INFO | open_webui.utils.logger:start_logger: 140 - GLOBAL_LOG_LEVEL : INFO - {} 2025 - 06 - 28 19 : 08 : 50 . 198 | INFO | open_webui.main:lifespan: 514 - Installing external dependencies of functions and tools... - {} 2025 - 06 - 28 19 : 08 : 50 . 370 | INFO | open_webui.utils.plugin:install_frontmatter_requirements: 241 - No requirements found in frontmatter. - {} 以下の様な URL をブラウザで開きましょう (デフォルトでホストが0.0.0.0なので、自宅の Wi-Fi であれば iPhone 等から Mac の IP アドレスを指定してアクセスできます)。
http://localhost:8080
最初に管理者アカウントの作成があるんじゃないかと思いますので、終わらせてから進めてください。
OpenAI API として追加する
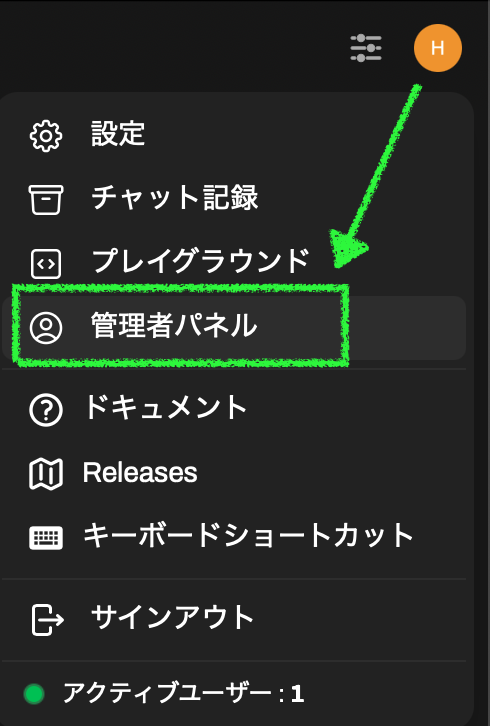
右上のアイコンから管理者パネルを開きます。
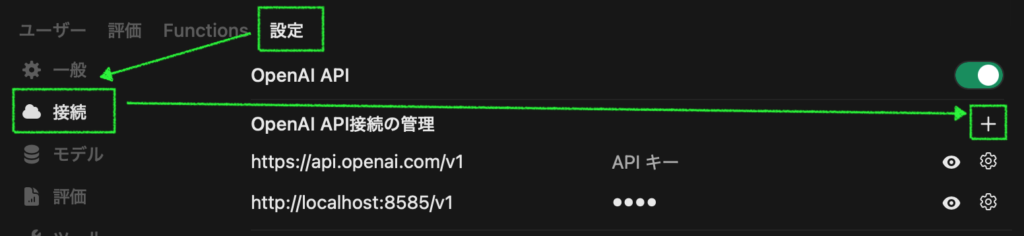
設定から接続を選び、OpenAI API接続の管理にあるプラスボタンをクリックします (下のスクリーンショットは設定済みの状態)。
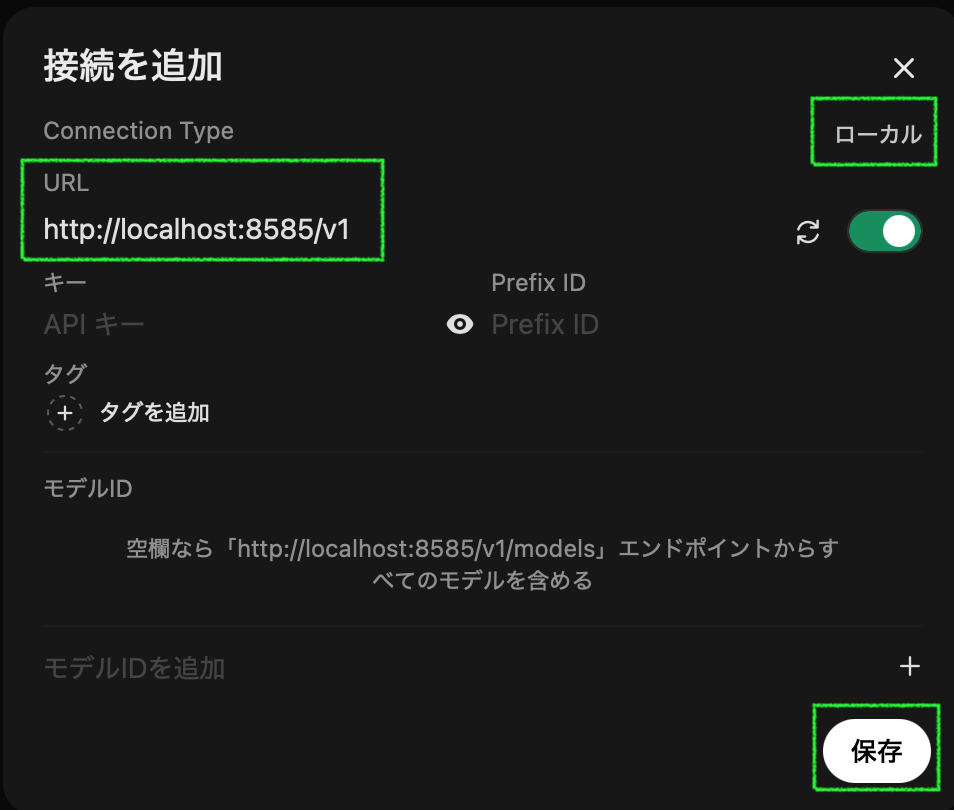
Connection Type の右の「外部」をクリックして「ローカル」に変更し、URL に今回の例では「http://localhost:8585/v1」を入力し、保存します。
接続の下の「モデル」をクリックすると、ダウンロード済みのモデルが表示されると思います。もし表示されなければ、一度 Open WebUI のターミナルでサーバを Ctrl + C で止めて、再度実行してみてください。
Alibaba の回し者ではないです ついでにやっておくべきオススメ設定
ここでモデルが見えれば新しいチャットの右にあるドロップダウンメニューから選んで使えるハズですが、その他いくつかやっておくべき設定を紹介します。
モデルの詳細設定をする
管理者パネル > 設定 > モデルで、モデル名をクリックするとデフォルトの設定を変更できます。システムプロンプト に「常に日本語で回答してください」と入れたり、高度なパラメータを表示して max_tokens を最大値にしておくと良いでしょう (デフォルトだと 128トークンしかない)。下にある資格のチェックボックスは、よくわからなければ全て外してしまいましょう。最後に「保存して更新」をクリックするのをお忘れ無く。
コンテキスト長は Ollama を Dify から使う場合などは注意して設定しないと大きな生成速度の低下を招きますが (参考記事 )、Open WebUI だと max_tokens や num_ctx (Ollama) をどれだけ大きくしても?影響ないみたいです。どうやっているのかは未確認。
余計な仕事をさせない
管理者パネル > 設定 > インターフェースで、Follow Up Generation とオートコンプリート生成をオフにして保存します。いらないでしょ?
チャットタイトルについて
上と同じインターフェース画面で、タイトル生成についての設定があります。この生成処理にも LLM が使われるので、全く不要ならオフにする事もできます。有効にしておく場合、Qwen3 ではここでも思考プロセスが動いてしまうため、タイトル生成プロンプトに/no_thinkとだけいれて保存しましょう。こうすると、何の工夫も無くチャットに最初に入力した文章そのままがタイトルになり、余計な GPU の使用を防げます (デフォルトのタイトル生成プロンプトを見ると対策をしようとしているみたいですが、現状はうまく機能していません)。
Safari ユーザは日本語確定のエンターでメッセージが送信されるのを防ぐ
別記事にその方法を書いています。この方法はどうやら localhost に対しては使えないようなので、Mac には固定 IP アドレスを振り、// @include http://192.168.1.100:8080/*の様な形で対象を指定する必要があります。
Dify から接続する
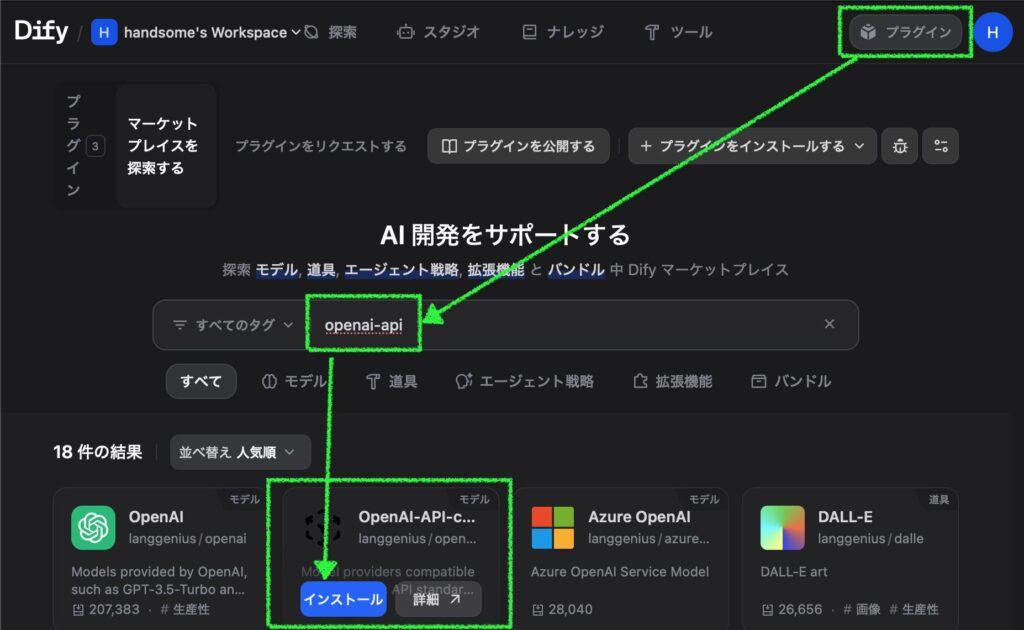
OpenAI-API-compatible を使えるようにする
Dify のバージョン 1以上で使うには、まず OpenAI-API-compatible をプラグインからインストールします。
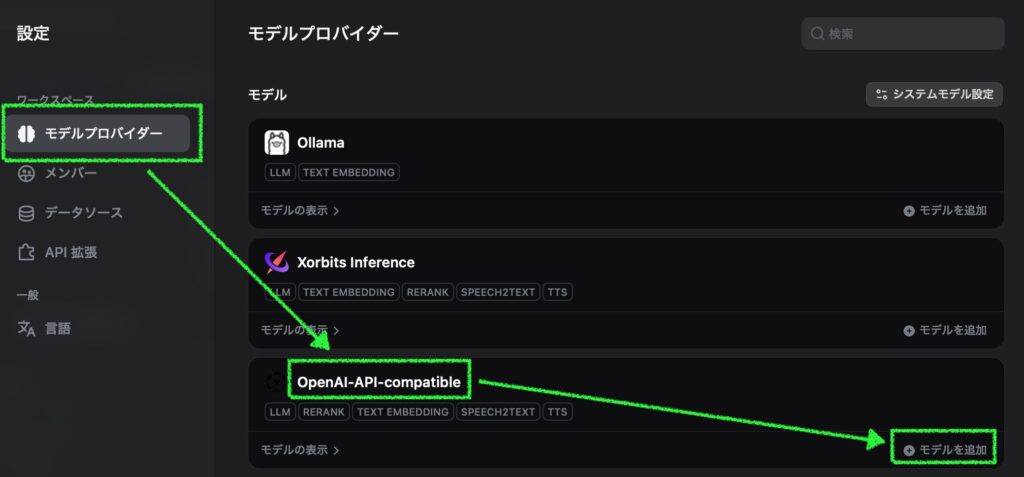
モデルを追加する
次に、右上の自分のアカウントアイコン > 設定 > モデルプロバイダーを開き、上で追加した OpenAI-API-compatible の「モデル追加」をクリックします。
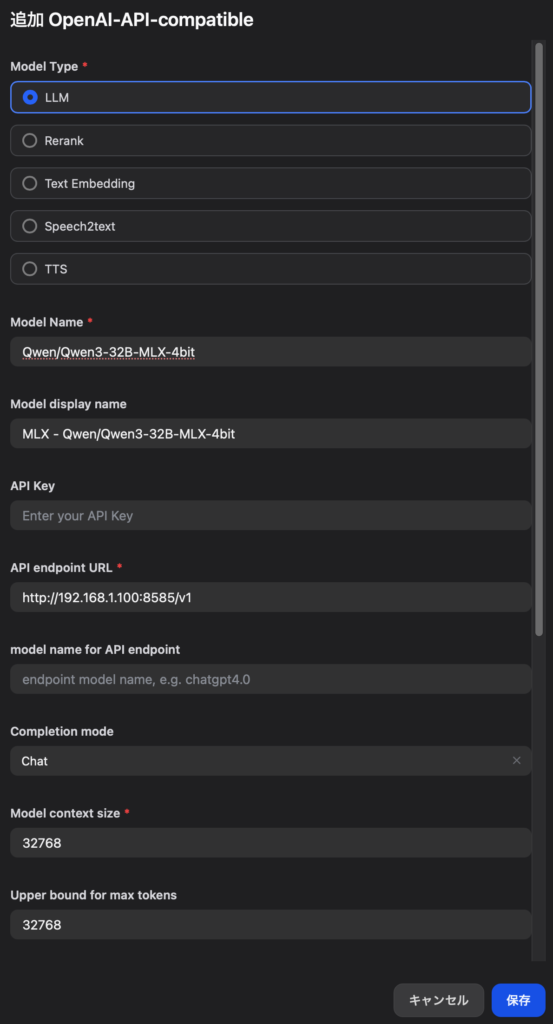
Qwen/Qwen3-32B-MLX-4bit を追加するなら、こんな感じです。
Model Name: Qwen/Qwen3-32B-MLX-4bit
Model display name: (自分にわかりやすいように。例: MLX – Qwen/Qwen3-32B-MLX-4bit)
API Key: 不要
API endpoint URL: http://localhost:8585/v1 とか、別ホストなら http://192.168.1.100:8585/v1 とか
Completion mode: Chat
Model context size: 32768
Upper bound for max tokens: 32768
その他もろもろ: Not Support またはよしなに
Delimiter for streaming results: \n\n
チャットのタイトルを生成するモデルを選ぶ
また、Dify ではチャットタイトルを作るのはシステム推論モデル固定なため、小さめで thinking/reasoning ではない MLX-LM のモデルを設定しておきます。ここでは先ほどダウンロードしておいた Gemma 3 を上同様の要領で OpenAI-API-compatible モデルとして追加した後、指定しています (Model context size は 40960)。
あとはそれなりに
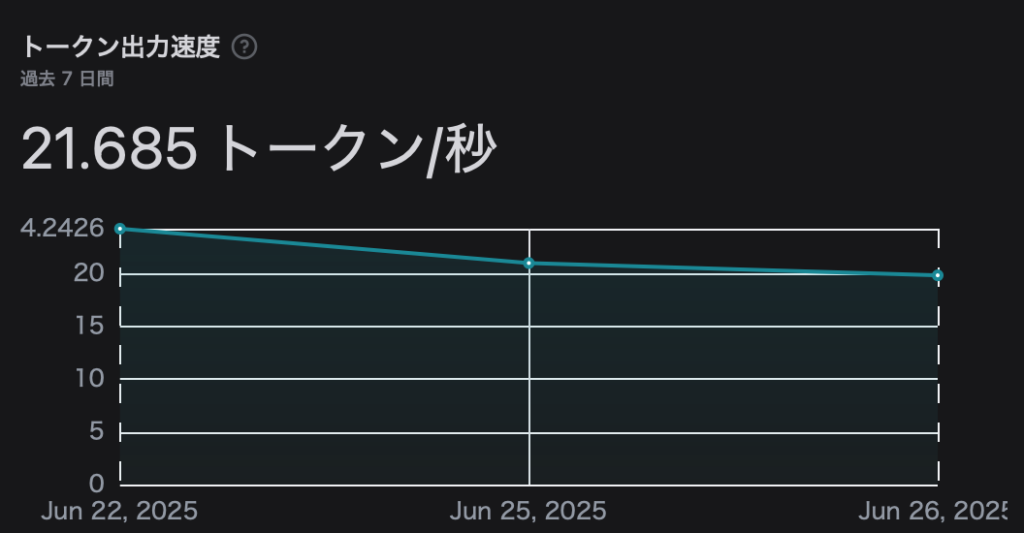
ここまでできたら、後は作ったアプリのモデルとして使用してみましょう。数字を鵜呑みにして良いのかわりませんが、いくつかチャットを行った後でアプリの「監視」メニューを見てみると、MLX-LM モデルのトークン出力速度が Ollama モデルより速いことが確認できます。
最後に
長々と書きましたが、使うほどに速さを実感しています。Ollama や LM Studio のようなユーザーフレンドリーさはありませんが、CLI での扱い方に慣れてしまえば MLX をサポートしない Ollama には戻れなくなると思います。ボクはディスク容量削減のため、Ollama からほとんどのモデルを削除してしまいました。
今回記事を書きながら Open WebUI をじっくり使ってみました。チャットだけなら十分ですね。タイトルの自動生成キャンセル技は速度を稼げるので地味に便利です。OpenAI API 接続だと tokens-per-sec が表示されないのは残念ですけど。RAG や MCP の利用もできるようなので、もっと使い込んでみようと思っています。
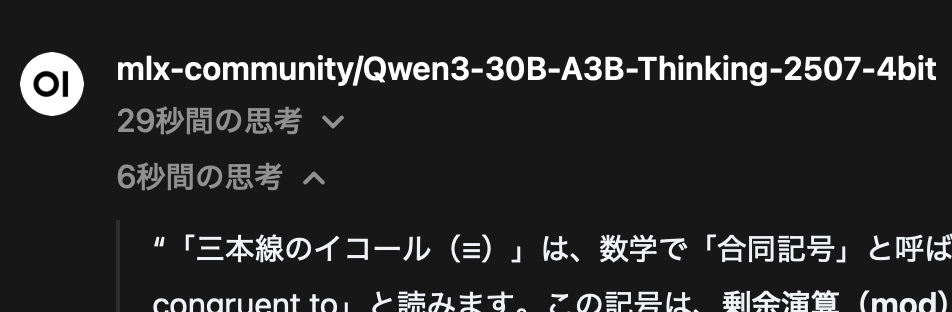
あとはやっぱり Qwen3 の性能の高さですよね。フロントエンド側でのサポートも進んでいて、QwQ だと丸見えになる思考が非表示になるのも地味にうれしいところです。政治的な話や中国にまつわる話を避ければおかしなところは感じないですし、最終的な回答に中国語が混ざる事も無く、当面はこれ一本でよさそうだと思っています。
Image by Stable Diffusion (Mochi Diffusion)
「リンゴTシャツを着てラマに乗る女性」いいんじゃないっすかコレ?もう一つステップを上げると破綻したので、これがベスト。
Date:
Model:
Size:
Include in Image:
Exclude from Image:
Seed:
Steps:
Guidance Scale:
Scheduler:
ML Compute Unit: