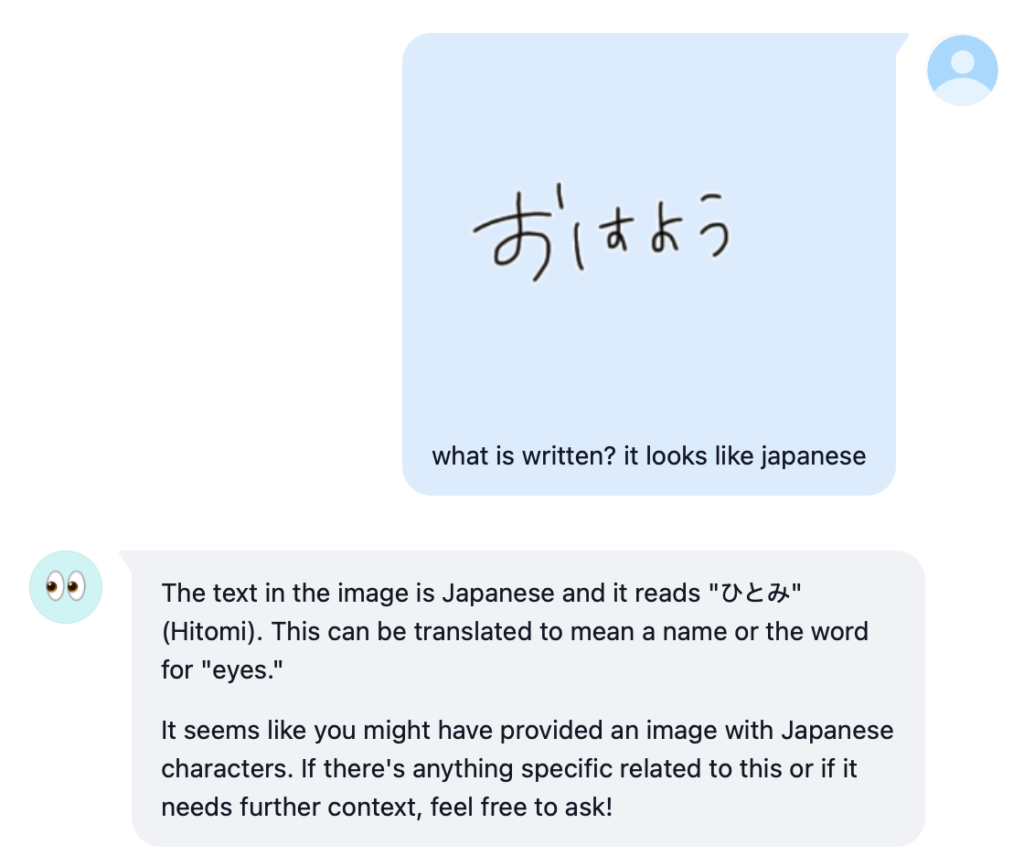
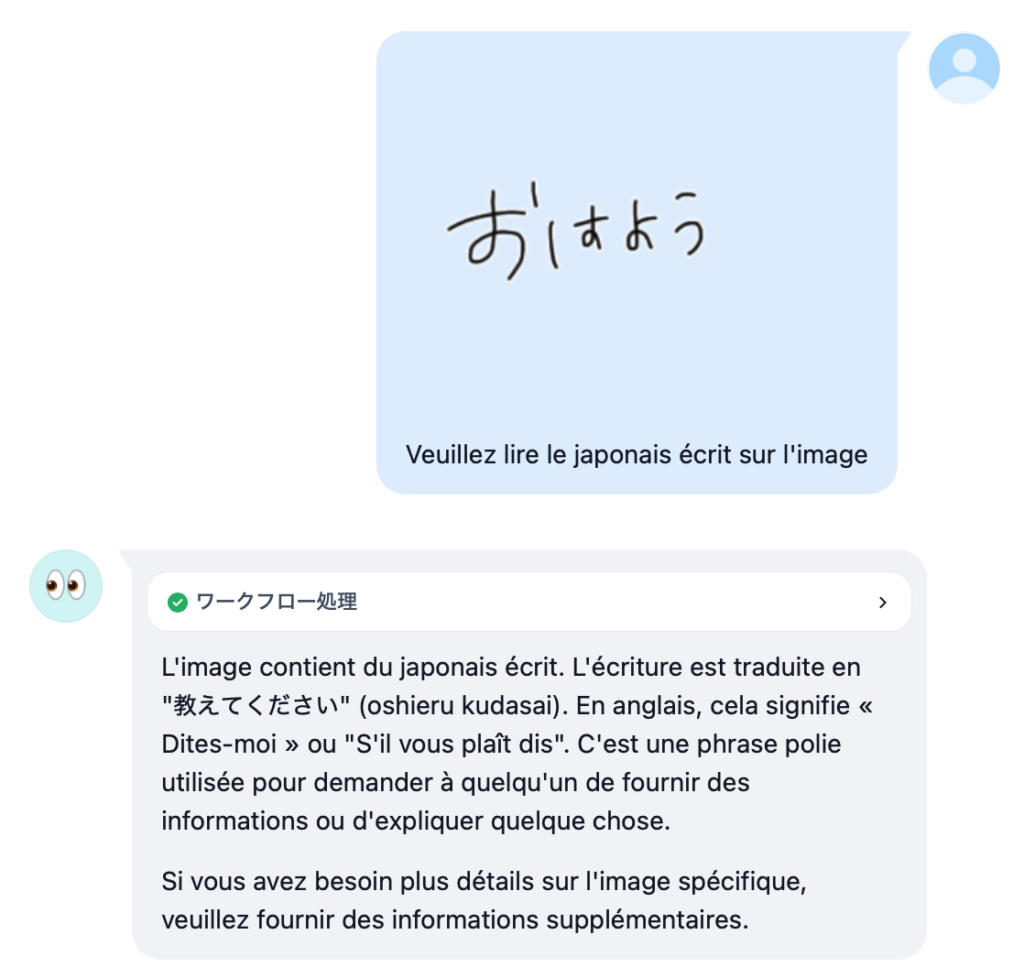
前回 Pixtral (Mistral 社のビジョンモデル) の日本語コミュニケーション能力と画像認識の性能の高さに感動しつつも、画像の中の日本語は読めないことを知り傷心したボク。Ollama のバージョンアップで正式に利用できるようになった Meta 社の画像認識モデルである Llama3.2 Vision 11B こそが本命であるはずだ!と早速試したんですが、あまりのぱっとしなさに記事にすることもありませんでした。ローカルで「使える」オープンモデル・ウェイトのビジョンモデルの登場はまだ先なのか、または画像内の日本語が認識できる LLM なんて 32GB RAM の Mac には一生やってこないのか、っていうか OCR したいなら普通に macOS 標準のプレビューでいいじゃんか、ということなのか。なんて思っていたら、普通にありました。とっくに出てました。しかもボクが最近何かとメインで使っている Alibaba 社の Qwen ファミリーに。そう、Qwen2-VL です。
(Qwen2.5-VL の登場と共に Qwen2-VL のウェブサイトが消えたようなので、Qwen2.5-VL のリンクを貼っておきます)
https://github.com/QwenLM/Qwen2.5-VL

簡単に使うなら、やはり LM Studio 単体で
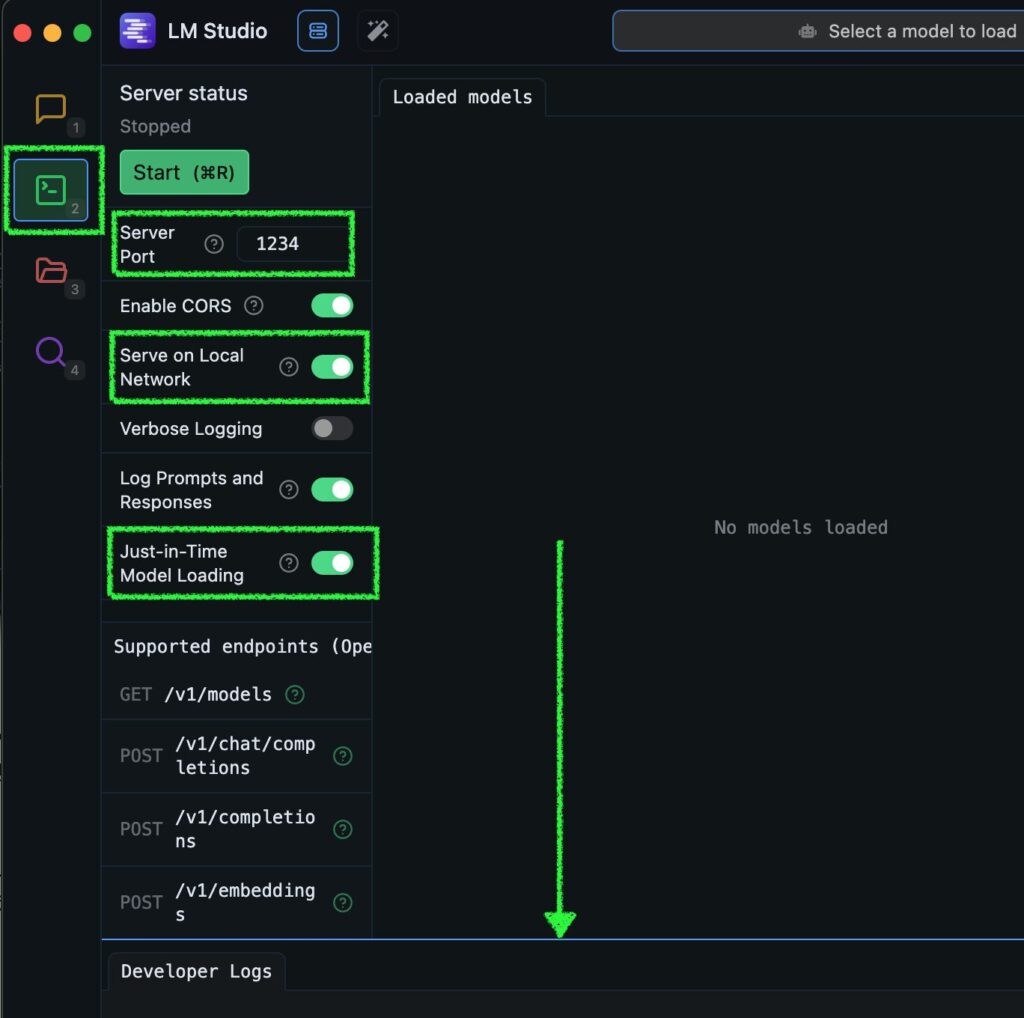
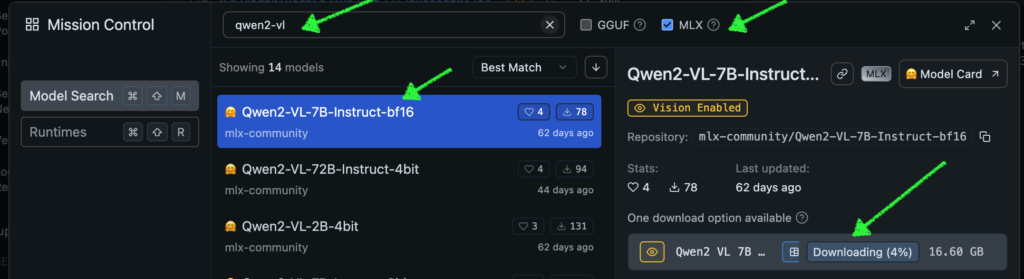
LM Studio の虫眼鏡アイコンで “qwen2-vl” と打ち込み、横のチェックボックスで MLX を選べば mlx-community にて変換された MLX 版の Qwen2-VL がずらずら出てきます。一番大きい 7B-Instruct-bf16 でも 16.60 GB なので、32GB RAM の Mac でも問題無く動きそうですが、そこはビジョンモデル、テキストオンリーのモデルと違ってメモリを喰います。BF16 はたまに CPU を使ったり頻繁にハルシネーションをおこしたりするヤンチャ坊主なので、オススメは 7B-Instruct-8bit です。というわけで、LM Studio で動けばそれでヨシ、という方はこれ以降読まなくて大丈夫です。ステキなビジョンモデルライフをエンジョイください。
Ollama では動かない
さて、普段はローカル LLM のモデルプロバイダとして使っている Ollama をなぜ使わないのかということを説明します。Ollama はバックエンドに llama.cpp を使っていますが、llama.cpp は (今のところ) ビジョンモデルに対応していません。Llama3.2 Vision は、Ollama の開発者が llama.cpp に依存せずに 頑張ってどうにか動くようにした (?) らしいです。が、Llama3.2 Vision 11B のパフォーマンスが 32GB RAM の M2 Max ではイマイチでして、ボクはすぐに使うのやめちゃいました。英語だけで OK の方は良いのかもしれないですね。
Safetensors は MPS で動かすこともできる
↓の Zenn に投稿された金のニワトリさんの記事に、MPS でサンプルコードを動かす方法が紹介されています。Llama3.2 Vision にガッカリしていたときに試したので、えらく感動しました。Mac の GPU で素のビジョンモデル Qwen2-VL が動いていたので。
https://zenn.dev/robustonian/articles/qwen2_vl_mac
さて、API で利用するにはどうするか?
macOS で Qwen2-VL を動かすには、元の Safetensors 版か、MXL 版のどちらか、ということがわかったわけですが、やっぱり Dify から使いたくなってしまいます (よね?)。本家の GitHub にあるワンライナーの API サーバ起動方法は vllm という Python のライブラリを使用しており、残念ながら Mac 未対応です。他の方法を探ると、言語モデルの MLX 用なら割といろんな API サーバライブラリがあるのですが、ビジョンモデルに対応したものとなるとかなり絞られました。さらにそこから実際に Qwen2-VL を使おうとすると、そもそも Dify に登録できなかったり、無理矢理登録できても例外しか発生しないという悲しい状況が 2週間ほど続きました。
同じように MLX のビジョンモデルである Pixtral は LM Studio が API サーバとなり Dify から使えるのに、Qwen2-VL を OpenAI コンパチモデルとして登録しようとすると、最初の ping (モデルが本当につながるかどうかのテスト) に画像が含まれないために Qwen2-VL がエラーを返してきて登録ができません。あらゆる方法を自分なりにいろいろと試しては失敗し、を繰り返していたある日、突然でたらめな組み合わせで動き始めました。詳細は以下に続きます。
成功した構成とバージョン
LM Studio または Dify の新しいバージョンではバグが潰されてこの方法が使えなくなるか、はたまた正式にサポートされて普通に動くようになるかわかりませんが、とりあえず ↓ の構成&バージョンで動作が確認できています。
- Dify: 0.11.2 (0.11.1 でも動いた実績あり)
- LM Studio: 0.3.5 (Build 2)
- Pixtral: mlx-community/pixtral-12b-8bit
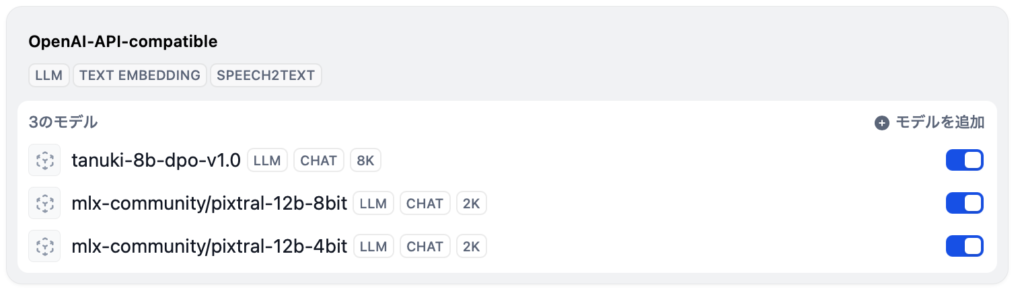
- Qwen2-VL-7B: mlx-community/Qwen2-VL-7B-Instruct-8bit (FastMXL でダウンロードしたモデル)
- Qwen2-VL-2B: mlx-community/Qwen2-VL-2B-Instruct-4bit (LM Studio でダウンロードしたモデル)
- macOS: Sequoia 15.1.1 (上記アプリが動けば、多分何でも大丈夫)
Dify から LM Studio の Qwen2-VL を使う方法
やり方は、ほぼ前回の記事と同じです。異なっているのは、LM Studio には Qwen2-VL をロードしておくだけです。Dify のアプリで使うモデルは mlx-community/pixtral-12b-4bit のままで構いません。というか、上記バージョンでは Dify に LM Studio 上の Qwen2-VL を登録できないので、Dify は Pixtral を呼び出しているつもり、LM Studio は読み込み済みの Qwen2-VL を使って推論をする、という状況になります。本来 LM Studio は指定されたモデルを読み込むはずなので、バグだと思いますが、これで動きます。
実行サンプル
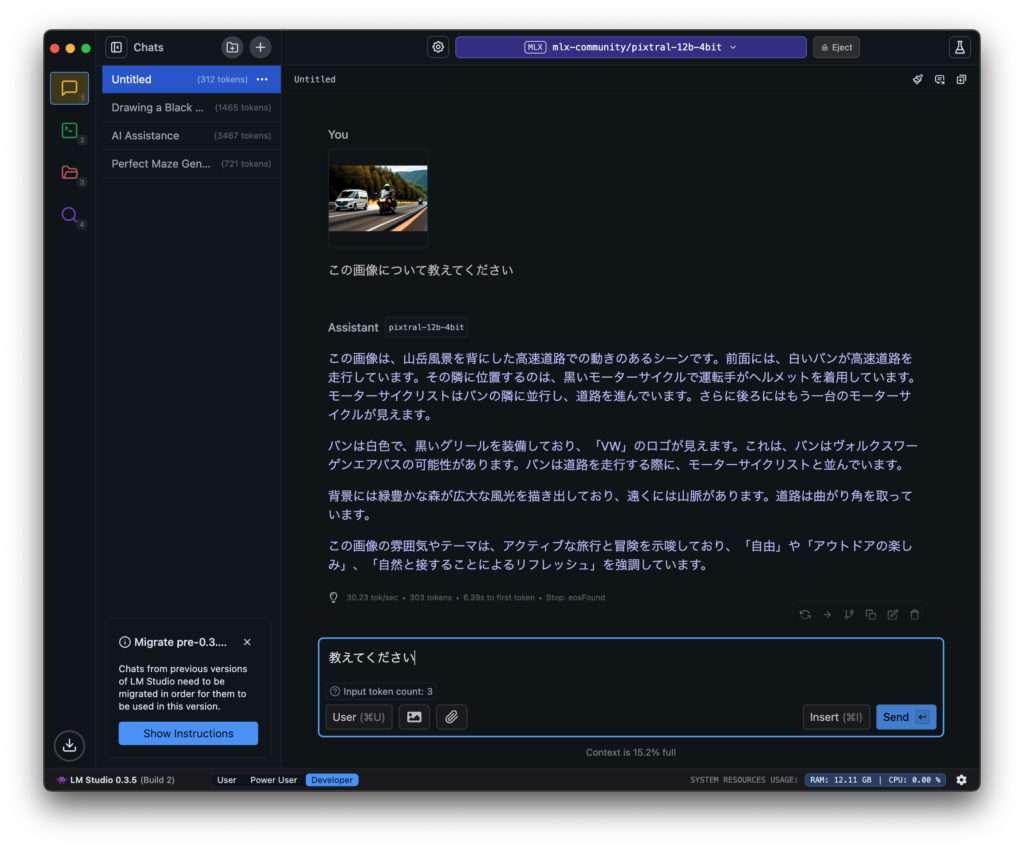
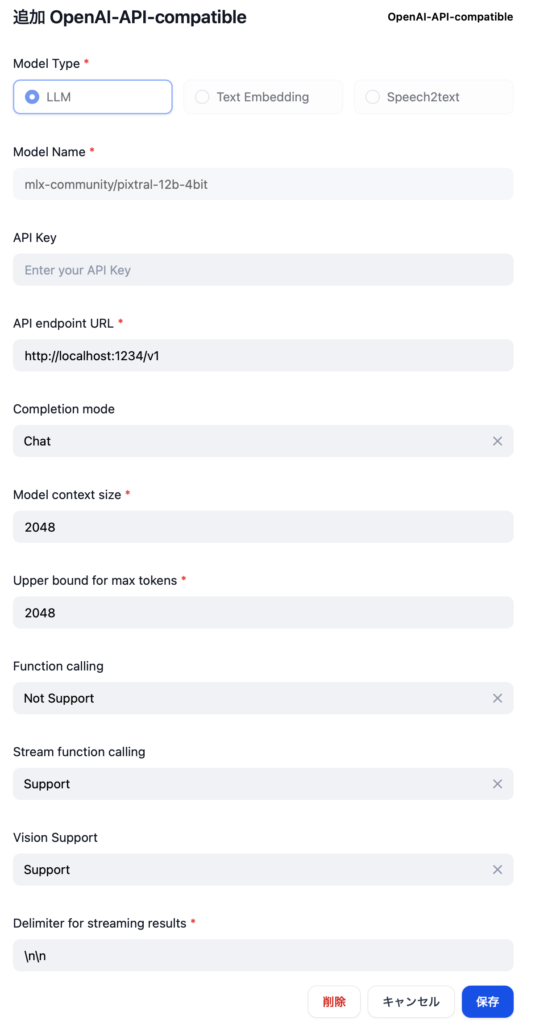
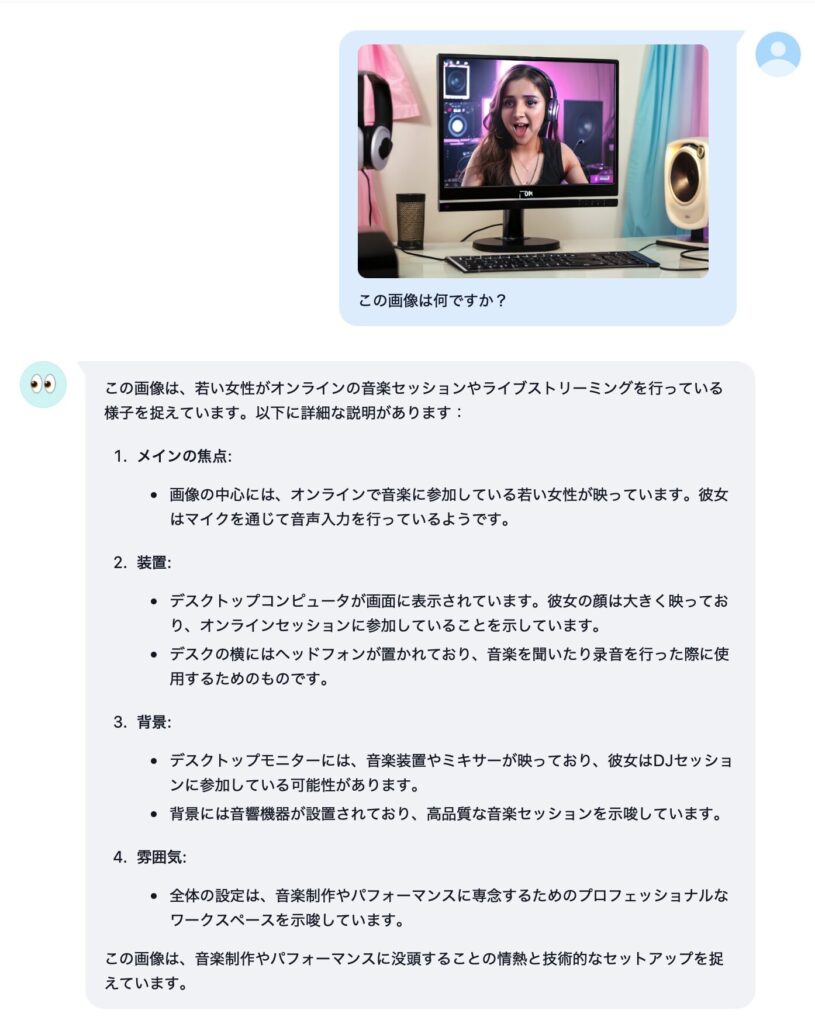
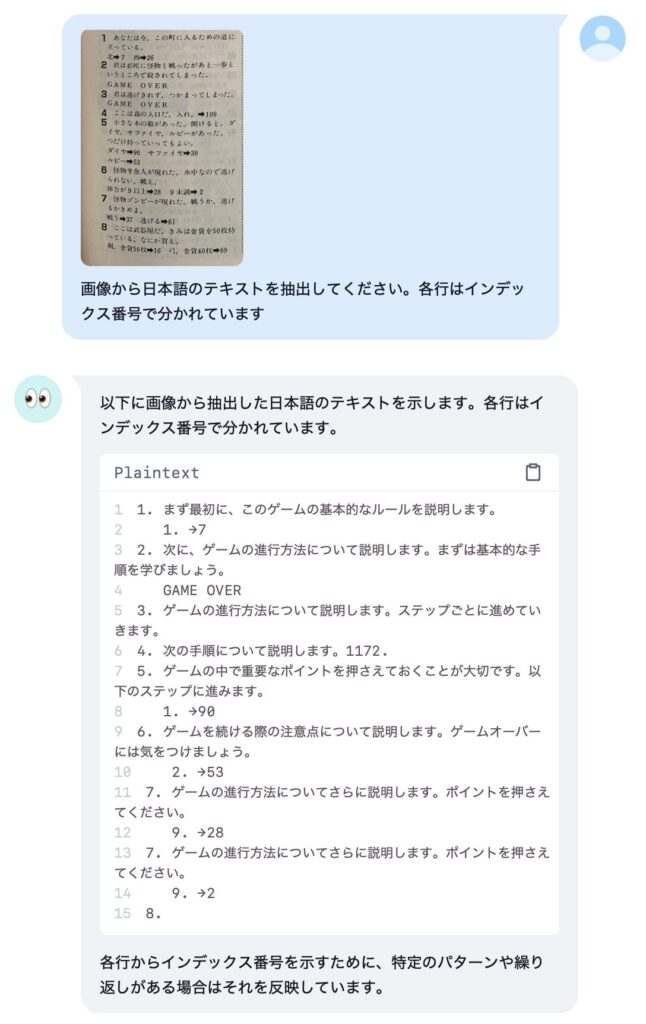
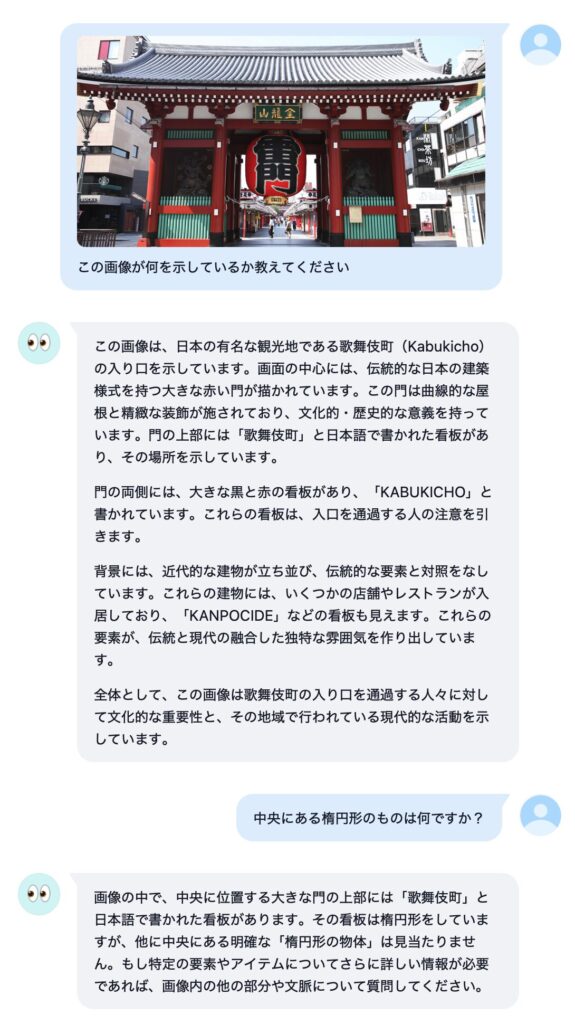
いくつか参考となりそうな画像を貼っておきます。
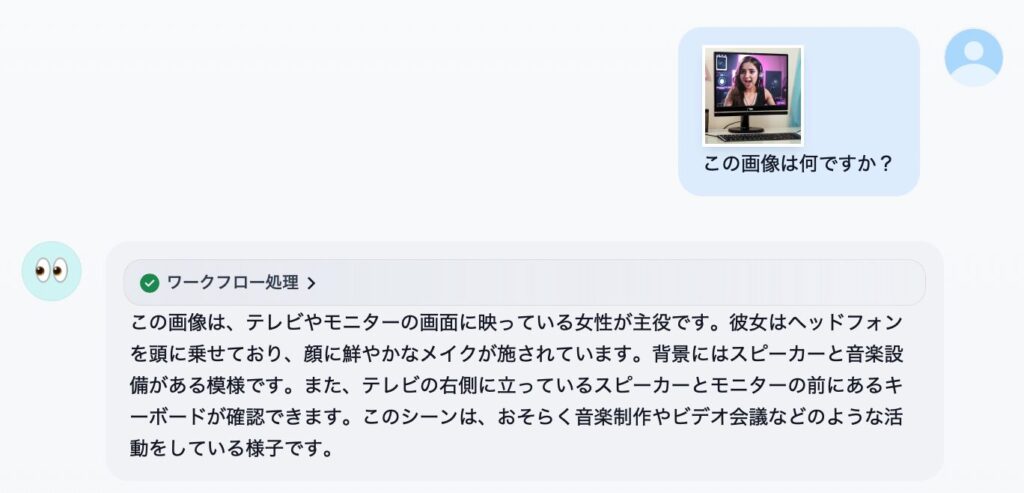
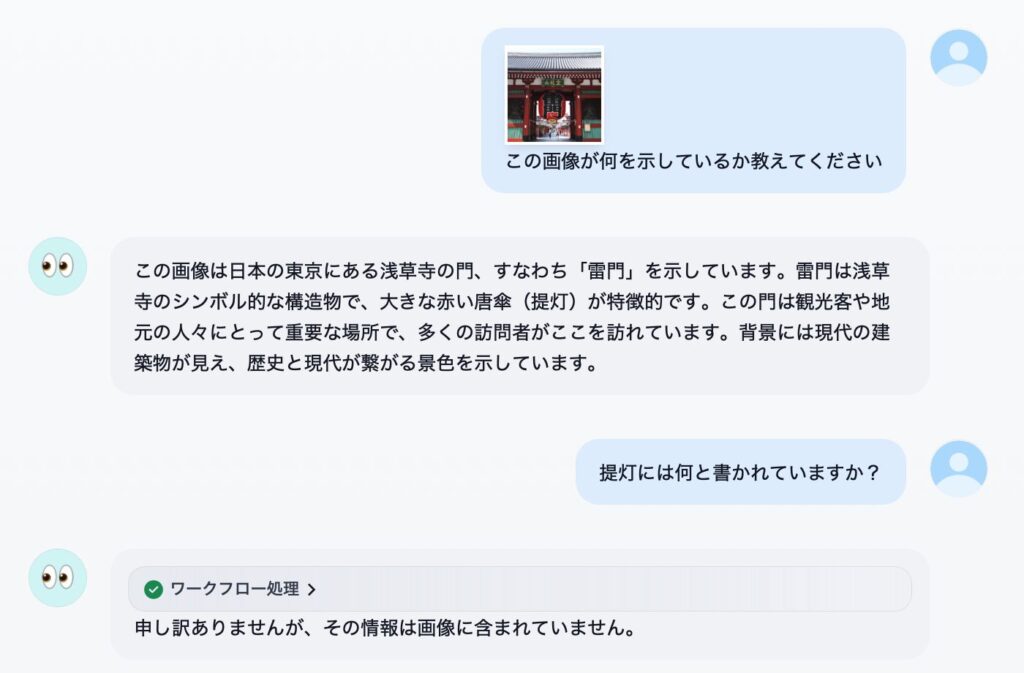
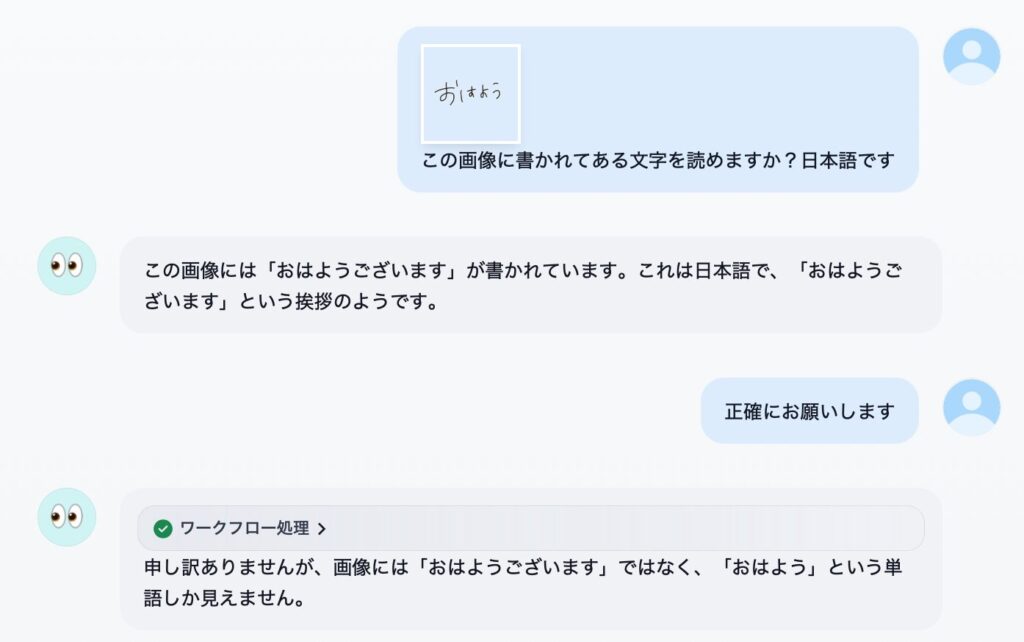
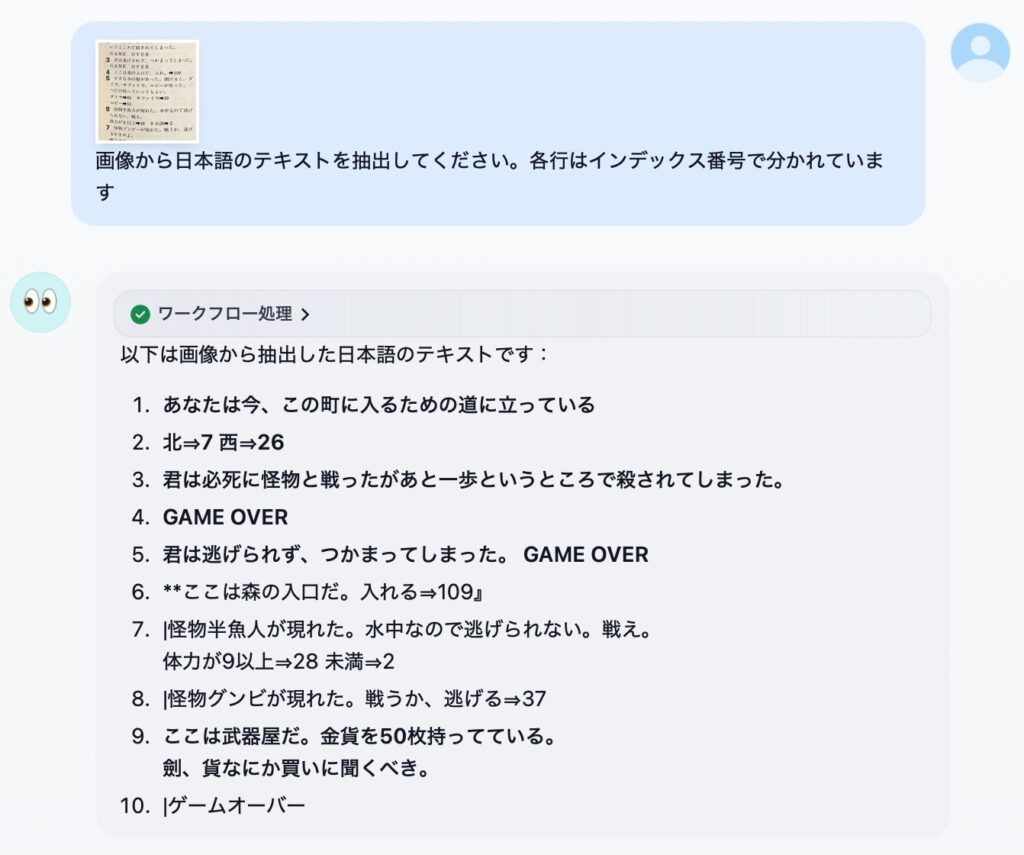
感想
性能的には、画像認識の精度や知識は Llama3.2 Vision モデルよりは良いけど、Pixtral ほどじゃ無いです。日本語 OCR メインの用途なら macOS のクイックルックやプレビューの方が相当優れています。というわけでやはり、期待したほどでは無いな、というのが正直な感想です。大量の RAM を積んでいる方が 72B のモデルを動かすと、また違う感想になるかもしれません。ビジョンモデルの使いどころも定まっていないボクにとっては、「普通には動かせないものを動かす」というハッカー的欲求を満たせたのでとりあえず満足、という感じですかね。
ところで最近のローカル LLM はほとんど Qwen2.5 シリーズしか使ってません。日本語チャットは qwen2.5:14b-instruct-q8_0 (15GB) もしくは qwen2.5:32b-instruct-q4_K_M (19GB)、コーディングは qwen2.5-coder:14b-instruct-q8_0 (15GB) もしくは qwen2.5-coder:32b-instruct-q4_K_M (19GB) です。速度や大きなコンテキスト長を扱いたいとき (注) は 15GB サイズのモデル、精度が欲しいときは 19GB のモデルを使っています。欧米のモデルよりも日本語が得意というのもありますが、各種リーダーボード (日本語オープン、日本語総合、コーディング) でも Qwen シリーズは高評価ですので、未体験の方はゼヒ。
ついでにですが、最近リリースされた推論 (reasoning) 重視モデルの QwQ-31B-Preview も普通に Ollama でダウンロードして使えます。32GB RAM の M2 Max での生成速度は速くない (7.5 TPS 程) ですが、性能というか、考え方の方向性がこれまでとかなり違い、ヤバいです。次元が違う感じ。
(注: 大きなサイズのモデルだとコンテキスト長が大きいと遅くなる場合があります。詳しくはこちらの記事をご覧ください)
最後に、ビジョンモデルの活用法を一つ思いつきました。大量の素材用写真が無造作にフォルダに入っているみたいな状況があれば、それぞれの写真の特徴を macOS の「情報を見る」のコメント欄に書き込んでくれるスクリプトなんてよさそうですね。Spotlight で検索できるようになるし。Qwen2-VL はビデオの読み込みもできるらしいので、整理に困っている大量の画像・映像を持っている人は良いかもですね。
Image by Stable Diffusion (Mochi Diffusion)
Pixtral の記事のトップ絵に対抗した内容で、登場人物を alibaba にし、場所を Alibaba Cloud 社があるらしい中国の Yu Hang にしてみました。きっと本当はこんな町並みでは無いのでしょうが、ボクの想像と概ね近いものを選びました。
Date:
2024年11月27日 23:59:11
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
masterpiece, intricate, realistic, sharp focus, photograph, alibaba walking in Yu Hang, china
Exclude from Image:
Seed:
1426778725
Steps:
20
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
CPU & GPU