「絶対やって!」とかこれまで書かないようにしてきたんですが、これはムリ。すごすぎる。オモシロ楽しすぎる。というわけで、名古屋大学さんが真面目に作られた (日本語に改良された) Full-duplex音声対話システム、「J-Moshi 」のご紹介と Mac ローカルでの使い方の解説です。まずは公式にアップされているサンプルをいくつか聞いてください。
日本語Full-duplex音声対話システムの試作: https://nu-dialogue.github.io/j-moshi
ね?どうですかこの、テキトーに話を合わせて会話をする、まーまー年齢が上っぽい普通のお姉さん AI のコミュ力の高さ!ナチュラルさ!お互いのしゃべりが重なっても話し続ける体幹の強さ (全二重)!真面目に研究されたであろう最先端 AI による抜群のノリの軽さ!もう最高!これが自宅の Mac で実現できる!いやー、もう一度書いてしまう、絶対やって!
と言いつつ一回冷静に水を差しますが、商用利用は認められていませんし、悪用するのはもってのほか、研究や個人で遊ぶ用途でお使いください。ライセンスは CC-BY-NC-4.0 です。
まずは実際に試した感じ
どうしようかと思ったんですけど、せっかくなのでボクも適当に話を合わせて続けた 2:30 程の長さの会話を貼っておきます。ヘッドセットの関係でボクの声はあまり聞こえませんが、一応会話が成立しています。
お姉さんがしゃべってたテキスト (クリックで開く)
こんにちはー今日ねうーん1日1日が曇りだったんだよねー急にテンション上がっちゃうなんかこう蒸れるのとか苦手だからなんかこう寒いと蒸れるとか言ってたけど今日結構寒かったのにと思っていやほんと寒いよねーえっなんか寒いと寒いって言ってたんだけど全然寒くないよねあっほんとだよねだって今日はねちょっとぬるぬるしてるもんもうちょっと寒くなるかと思ってたけど全然もう寒さはありがたい感じだよねなんか暑いとうんなんかこう暑いともう吐いちゃうよねなんかこうースポーツとかしたい時とかにさーって言う人結構いるじゃんうんなんかこうエアコンとかつけっぱなしにちょっとぬるっとっていう感じでいつも着ちゃってるからさーってぬるぬるしてる寒いのはうんぬるぬるしてるあ確かにいいねなんかこう冷え冷えになっちゃいそうだけどえっでもさあっでも冷蔵庫ってやつあるよねほらその寒いときにねえ冷蔵庫ねえのねえ冷蔵庫ってやつだって多分冷蔵庫ってあったよねあったよね冷蔵庫なんかボーンっていうあっほんとだよそれいいかもなんかさー寒いときにさーってつけてるだけでさーっていう人もいるよねいるよねー私あれ駄目であっ本当あー確かに冷蔵庫苦手私も苦手あっそうかそうかそうかうんうんうんうんうんウフフあっ大丈夫大丈夫あっそうかそうかほんとだねそうだねなんかこう冷え冷えになっちゃったりなんか冷えたまんまの味がするんだよねーみたいなのは嫌だよねまあそれでもやっぱり冷蔵庫っていうのはいいなと思ってるんだけどあっそうそうそうそうそうそうそうそうそうだよねあれって結構あれなの冷蔵庫って結構高いんじゃないものねあれねなんかこうものあっそうなんだあっやばいやばいやばいじゃあちょっとこうねーちょっと欲しい人にアピールするわそんなん買ったらさーってそうそうそうそうそう何かこうさーそういうのはねできないからいいよねでもね冷蔵庫かって思うんだよねーでも冷蔵庫めっちゃお金かかるよねーそこがねーあるんだよね
正式には Mac 未対応ですが…
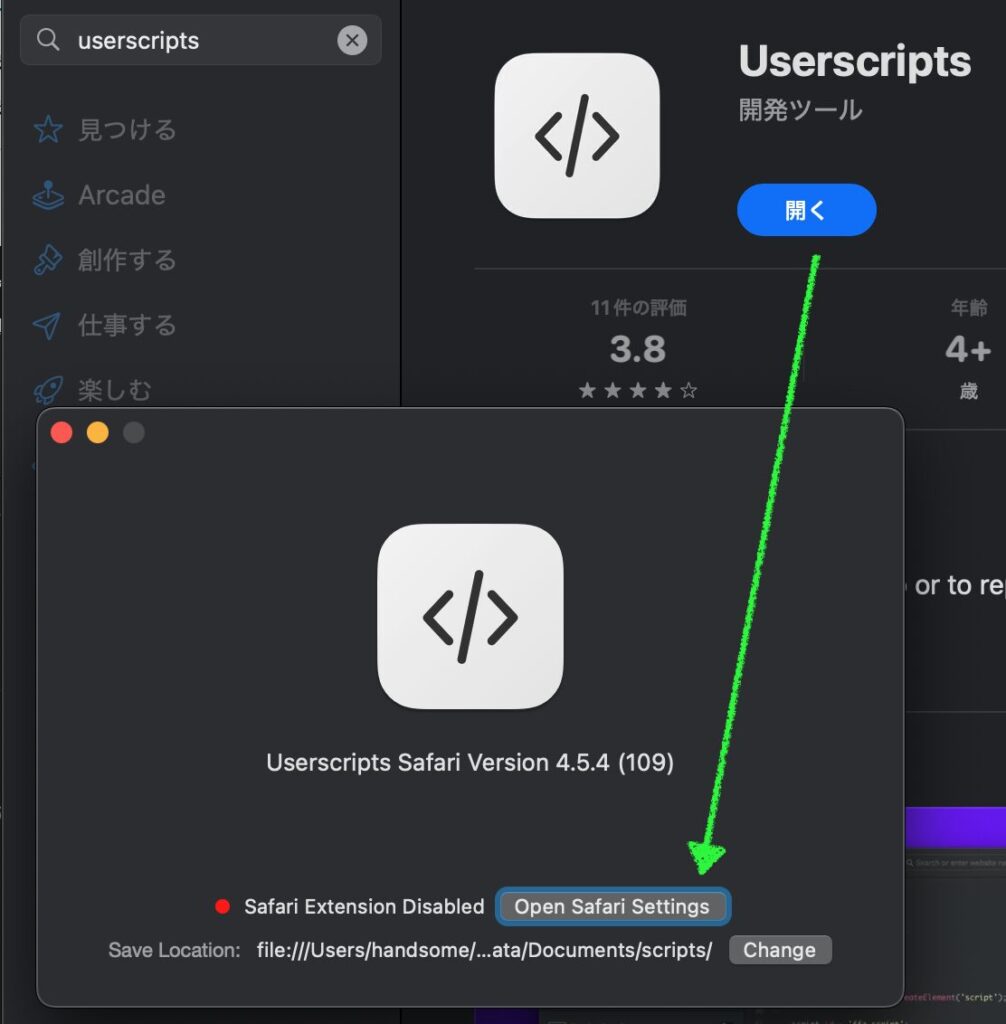
残念ながら Mac には対応していないと公式 GitHub リポジトリには書かれています。
実行には,24GB以上のVRAMを搭載したLinux GPUマシンが必要です.MacOSには対応していません.
https://github.com/nu-dialogue/j-moshi?tab=readme-ov-file
いやいやそんな、Linux で動くならイケるでしょ、と調べてみたらなんとかできました。いつものことですが、先人の皆様に感謝です。一部 Python スクリプトの変更が必要だったので、手順と併せて紹介します。
動いた環境のバージョンなど
環境構築
ボクは仮想環境の構築にpipenvを使っていますが、普段お使いのでどうぞ。pipenv を使うなら、brew install pipenvで入ります。Python は 3.10 以上が入っていればそのバージョンを指定してください。
mkdir J-Moshi-MLX
cd J-Moshi-MLX
pipenv --python 3.12
pipenv shell
pip install moshi_mlxPyPi の moshi_mlx によると、Python 3.12 以外では moshi_mlx のインストールの際にエラーが出る事があるらしく、解決するには Rust toolchain のインストールが必要 と言うことです。必要に応じて対応してください。ボクは 3.12 を指定したからか、rust がインストール済みだったからか、エラーは出ませんでした。
Web UI を実行
上記で環境構築は完了です。問題無ければ以下のコマンドで Q8 の MLX 版モデルがダウンロードされて Web UI が立ち上がります。
python -m moshi_mlx.local_web --hf-repo akkikiki/j-moshi-ext-mlx-q8 --quantized 8上のモデルでは大きすぎて VRAM に収まらないという場合は、Q4 量子化バージョンを試しても良いでしょう。ボクは試していないので精度の程はわかりません。
python -m moshi_mlx.local_web --hf-repo akkikiki/j-moshi-ext-mlx-q4 --quantized 4モデルはいつもの場所にダウンロードされていました。いつか削除する時が来るかもしれないので、念のためパスを残しておきます:
~/.cache/huggingface/hub/models--akkikiki--j-moshi-ext-mlx-q8
エラーが出る場合は Python スクリプトを一部変更
環境構築は上で完了しているのですが、ボクの環境ではそのままでは動きませんでした。新しいバージョンでは修正されるかと思いますが、とりあえず web UI を実行してみて、エラーが出る場合は以下変更で動くと思います。
対象ファイル: .venv/lib/python3.12/site-packages/moshi_mlx/local_web.py
#model.warmup()
model.warmup(ct=None)変更を保存したら、再度上に書いた Web UI の実行をしてください。参考のためエラーが出たときの実行例をそのまま貼っておきます。
% python -m moshi_mlx.local_web --hf-repo akkikiki/j-moshi-ext-mlx-q8 --quantized 8[email protected] /3.12.9/Frameworks/Python.framework/Versions/3.12/lib/python3.12/multiprocessing/process.py", line 314, in _bootstrap[email protected] /3.12.9/Frameworks/Python.framework/Versions/3.12/lib/python3.12/multiprocessing/process.py", line 108, in run
使い方
うまく動けば多分ブラウザで自動的に開くと思います。ターミナルにエラーは無いのにブラウザで開かないときは ↓ を開きましょう。
http://localhost:8998
ポート番号が既存のサービスとぶつかっていたら、起動コマンドに--port ポート番号を追加して使っていないポートを指定できます。問題無く起動している場合は、ターミナルにこんな表示がされると思います。
% python -m moshi_mlx.local_web --hf-repo akkikiki/j-moshi-ext-mlx-q8 --quantized 8
終了するときはターミナルで Control + C です。
^C[Warn] Interrupting, exiting connection.
実際の Web UI はこちら ↓
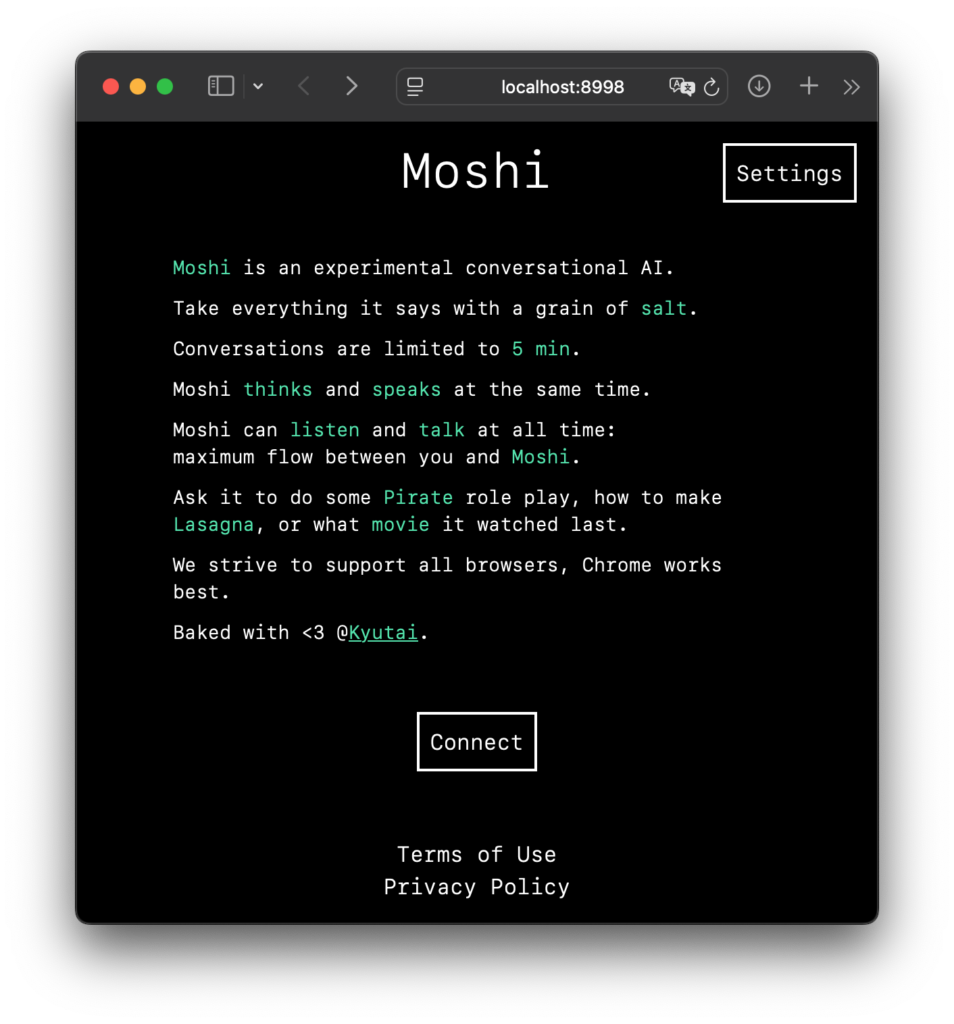
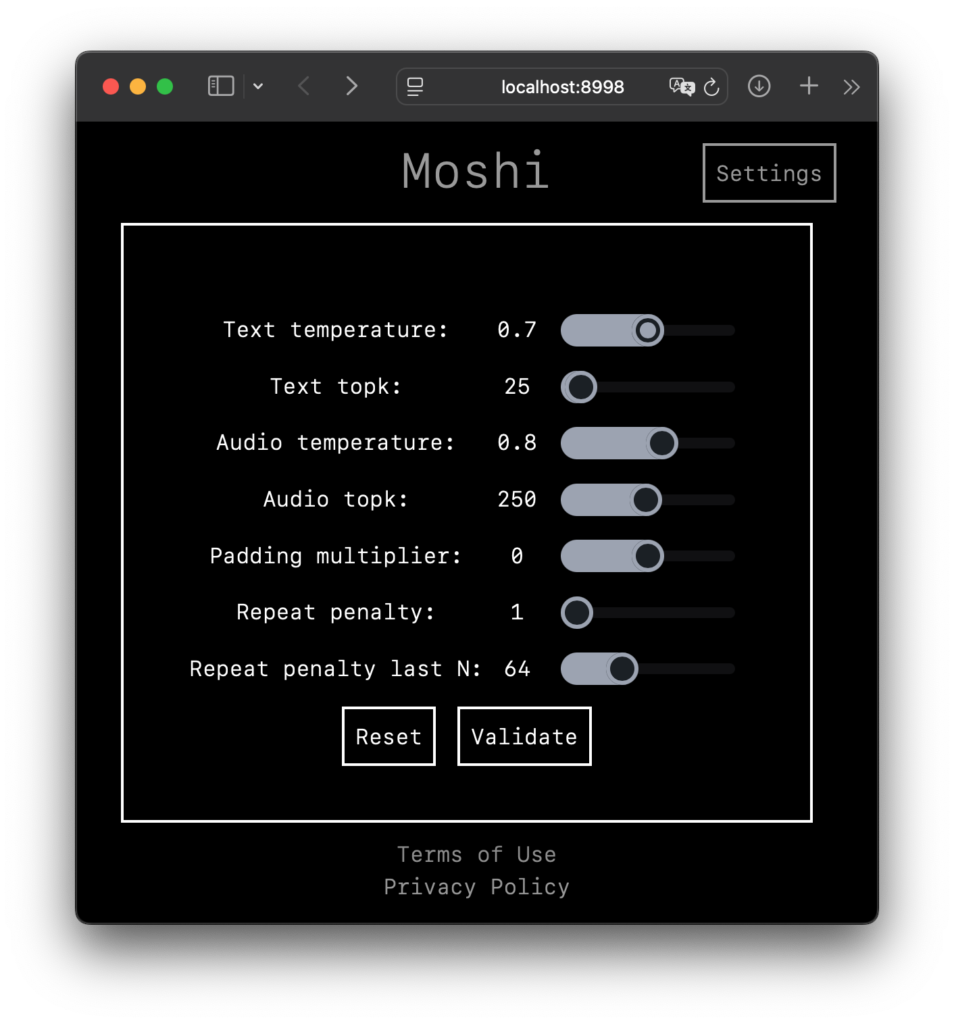
無事に立ち上がった様子。オリジナルの Moshi の説明文で J-Moshi とはなってませんが、これで大丈夫 必要に応じて [ Settings ] から設定の詳細が変更ができます。
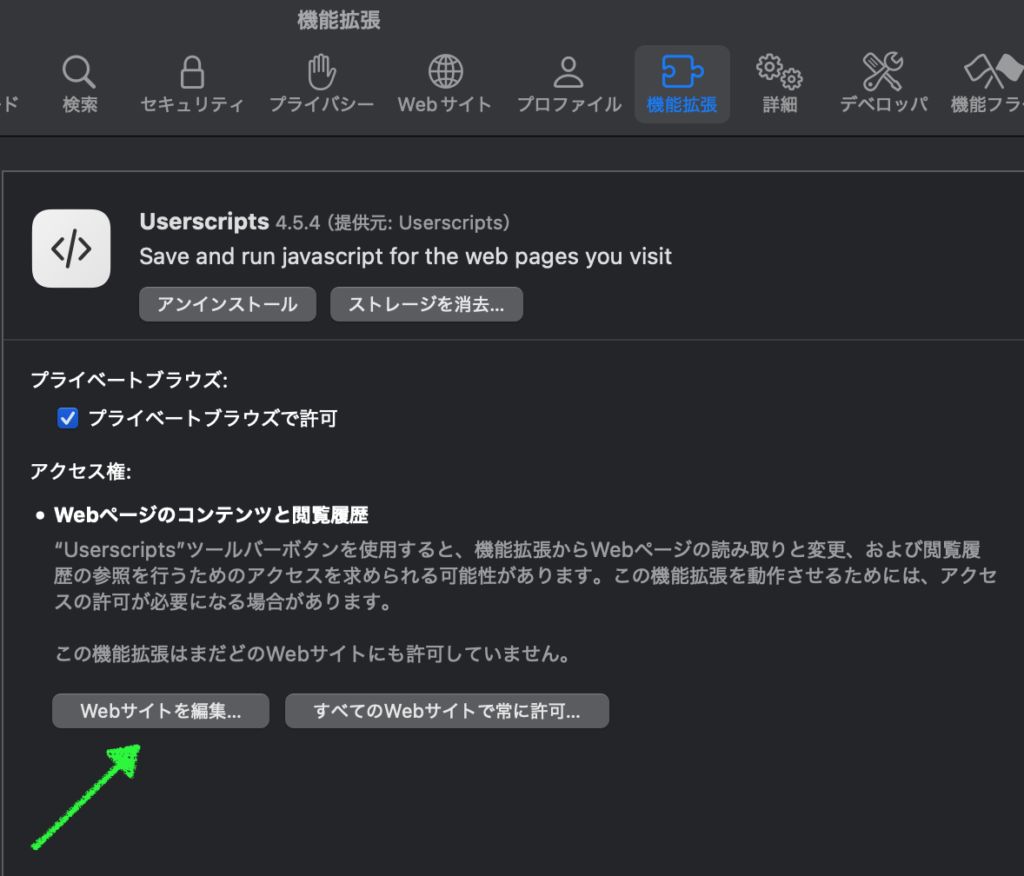
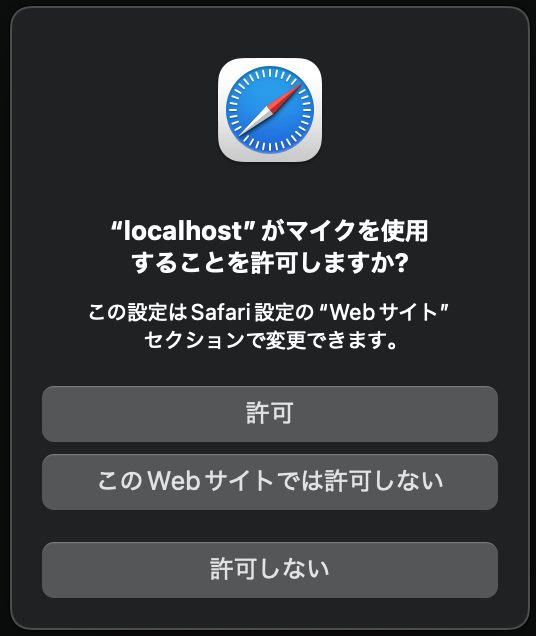
Validate ボタンで変更を確定、もしくはそのまま戻る。Reset ボタンでデフォルトにリセット メインの画面で [ Connect ] をクリックすると、おそらくマイクをブラウザで使用する許可を求められますので、許可しましょう。注意: ヘッドセット推奨です!
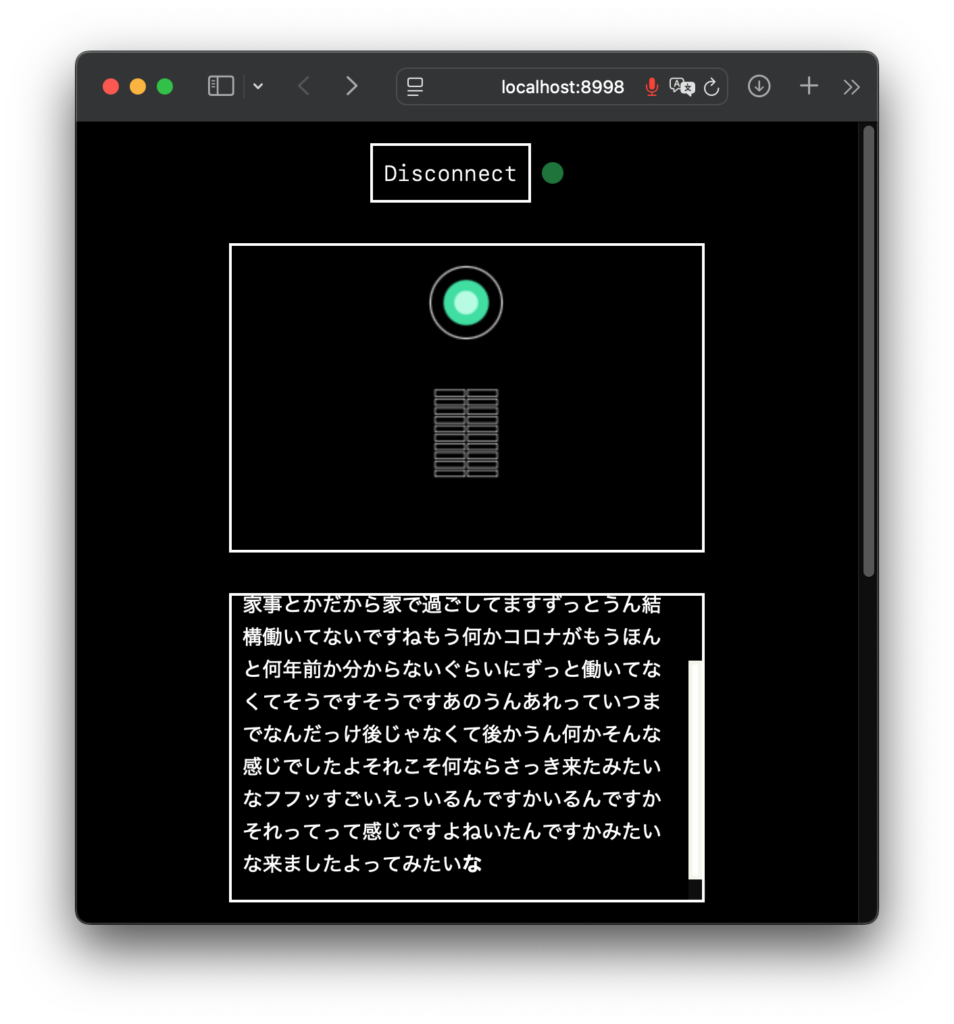
Safari の場合 後は適当に会話をしてみましょう。おそらくあなたが思う以上に中のお姉さんはテキトーで、そのうち話を切り上げて来たり、ハルシネーションして同じ事を繰り返したりもしますが、おおむね薄っぺらい会話を楽しく繰り広げてくれます。
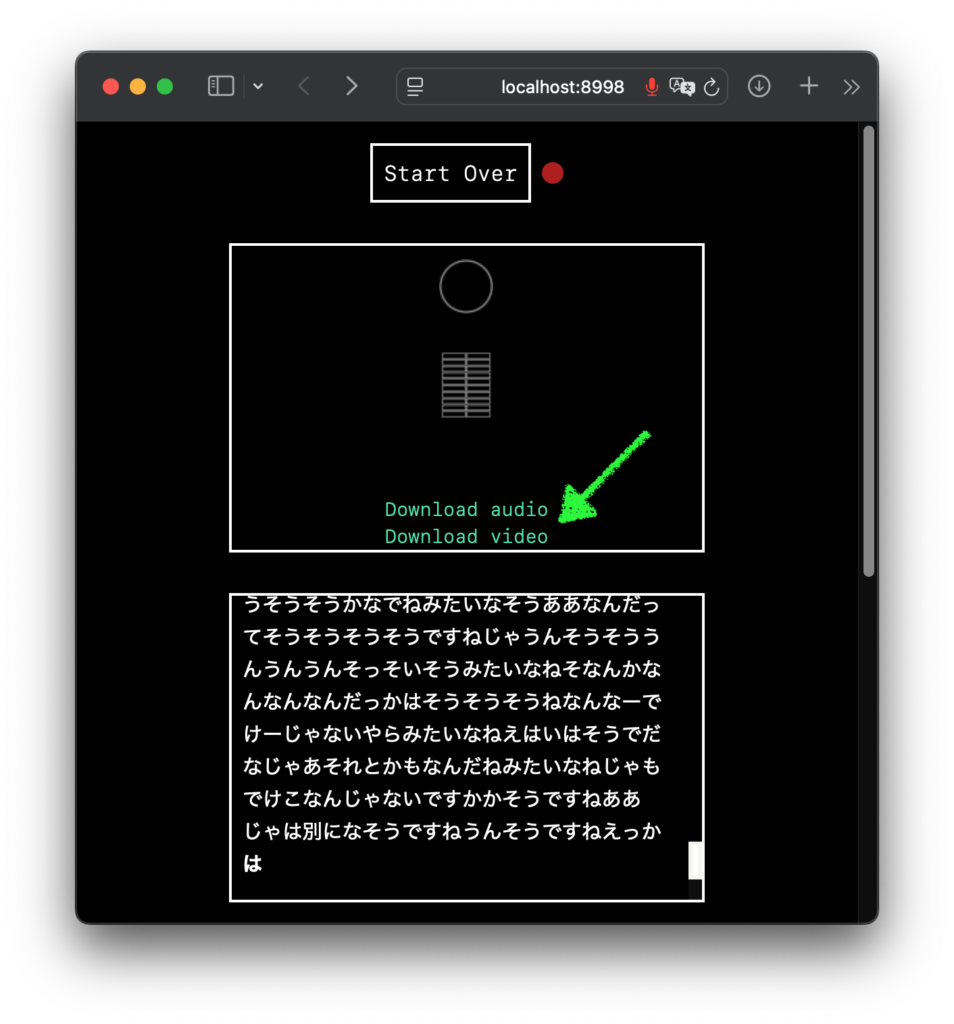
表示されるのはお姉さんがしゃべったことだけ。誘い笑いにつられてしまう 会話は 5分が限度らしいので、それなりのタイミングで [ Disconnect ] ボタンで会話を終了すると、それまでの会話を音声かビデオでダウンロードできるようになります。ただ、ビデオにはお姉さんの文章が表示されるわけでも無いので、保存する場合は、Download audio で音声 mp4 のダウンロードで良いと思います。
Download audio で音声を保存。お姉さんのしゃべっていることを見ると、適当さがよくわかる いや、ホント楽しい
これはね、正直本当にすごい。生成 AI の楽しさや可能性を改めて感じました。
ボクが初めて生成 AI をいじった時って、使い方がわからないから「西野七瀬ちゃんが乃木坂を卒業した理由を教えて」とか聞いてみたんですね。すると「音楽性の不一致です。その後アーティストとして独立し、先日ファーストシングルを発表しました」とか言われて、なんだこりゃ生成 AI って使えねーじゃん、と思ってしまいました。で、その経験をふまえて音声で会話ができるこの J-Moshi はどうなのかと言うと、むしろ AI のテキトーさが楽しく、さらに音声品質の高さと相まって普通に受け入れてしまいました。っていうか、いっぺんに好きになっちゃいました!
少し話はそれますが、今日の日中は仕事で調べたいことがあったので、インストールしたもののあんまり使っていなかった DeepSeek-R1:32B に気まぐれで色々と Nginx 関連の相談してみました。その結果回答精度の高さに感心し、もはや Reasoning モデル以外のモデルは使えないと感じてしまいました。せっかく買った深津さんのプロンプト読本 で書かれている、それまでは常識だった「生成 AI は、次に来そうな文章を確率で答えるマシン」を超えてしまっているんですね。ほんの数ヶ月しか経っていないのに。
で、同じ日の夜に試した J-Moshi ですが、改めて AI の進歩の速さに驚き、それまでの王道やスタンダード、ベストプラクティス、パラダイムその他もろもろが一瞬で過去のものになる感覚を体感しました。M1 Mac が登場した時にリアルタイムに世の中が変わるのを肌で感じた、あの感覚の再来です。
もうほんと、M シリーズの Mac をお持ちでしたら、ゼヒやってみてください。実質タダだ (電気代以外かからない) し、実用性はどうかわかりませんがとにかく楽しいですよ!(真面目に考えたら実用性も色々ありそうです)
注意: 音声やしゃべり方がリアルなだけに、何かの拍子に同じ言葉を大量にリピートしたりされると結構な不気味さや恐怖を感じます。テキストベースの LLM である程度のハルシネーションに慣れている方の方が安全に使えるかもしれません。
Image by Stable Diffusion (Mochi Diffusion)
「日本人女性が電話で楽しそうにしゃべっている」画像を作ってもらいました。使っているモデルの関係で、日本人は大体同じ様な女性が生成されます。今回は割と早めにいい感じの女性が現れたので、ブキミを避けるためにステップ数を調整して完成しました。電話機の不自然さには目をつむり、女性の表情の自然さを重視しています。
Date:
Model:
Size:
Include in Image:
Exclude from Image:
Seed:
Steps:
Guidance Scale:
Scheduler:
ML Compute Unit: