

最近のオープンソース・オープンウェイトの LLM のパフォーマンスは本当にすごくて、コーディング補助なら DeepSeek Coder V2 Lite Instruct (16B)、日本語と英語のチャットや翻訳なら Llama 3.1 Instruct (8B) で十分です。Ollama をターミナルアプリから実行してチャットすると、その内容と回答スピードには本当に驚かされますね。インターネットが止まっても当分生きていける感じがします。
ところが、Dify や Visual Studio Code 用 LLM 拡張機能 Continue から Ollama の同じモデルを API で使用すると、使い物にならないくらい遅いという状況が発生しました。今回はその解決方法を紹介します。あなたの問題の原因は別のところにあるかもしれませんが、簡単に確認・修正できるので、まずは本記事の【結論】の内容を試してみることをオススメします。
Contents
確認できた環境
OS やアプリのバージョン
macOS: 14.5
Ollama: 0.3.8
Dify: 0.6.15
Visual Studio Code - Insiders: 1.93.0-insider
Continue: 0.8.47LLM とサイズ
| モデル名 | モデルサイズ | コンテキストサイズ | Ollama ダウンロードコマンド |
| llama3.1:8b-instruct-fp16 | 16 GB | 131072 | ollama pull llama3.1:8b-instruct-fp16 |
| deepseek-coder-v2:16b-lite-instruct-q8_0 | 16 GB | 163840 | ollama run deepseek-coder-v2:16b-lite-instruct-q8_0 |
| deepseek-coder-v2:16b-lite-instruct-q6_K | 14 GB | 163840 | ollama pull deepseek-coder-v2:16b-lite-instruct-q6_K |
【結論】コンテキストサイズを見直そう
API 経由で Ollama のモデルを利用する側のアプリ、例えば Dify で設定する「Size of context window」を十分に小さくすることで解決します。モデル自体が対応しているから、とか、将来のためになるべく多くのトークンを処理できるキャパにしておきたいから、という理由で大きな数字を割り振るのはやめましょう。デフォルト値 (2048) または 4096 程度に変更し、短い文章のチャットでテストしてみてください。本来のスピードに近いパフォーマンスが出れば、ビンゴです。
コンテキストサイズとは: 英語では context size、他にコンテキストウィンドウ (context window)、コンテキスト長 (context length)、とも呼ばれる値で、LLM が一度のやりとりで処理できるトークン数の合計です。トークン数とは、日本語ならほぼ文字数、英語ならほぼ単語数とイコールです。上の表の Llama 3.1 を見ると 131072 となっていますので、単純に LLM への入力と生成されるテキストが同じ量であると想定すると入力に使えるのは半分なので、Llama 3.1 は約 6万5千文字の日本語の文章を入力に使用できる、そのキャパシティがあるということです。
コンテキストサイズを変更するところ
Dify
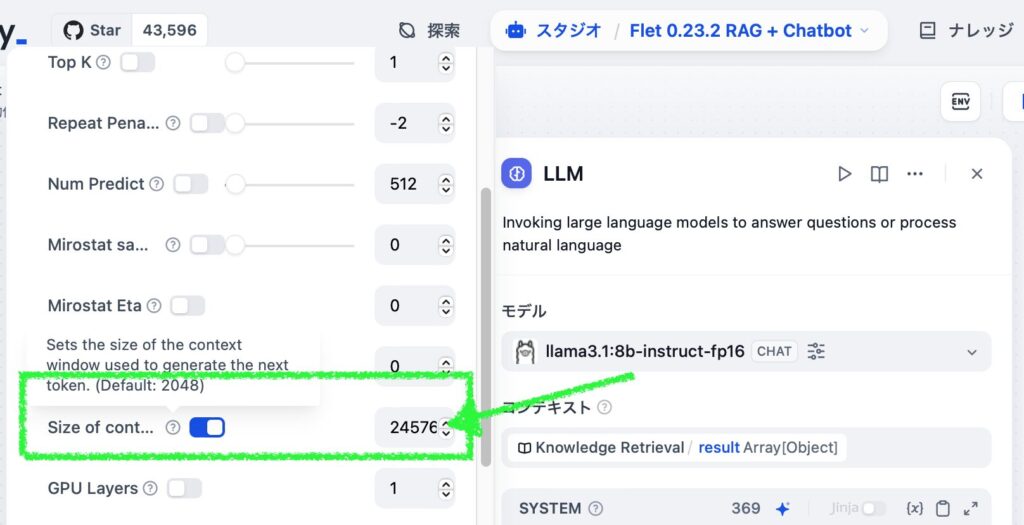
スタジオのアプリ内にある LLM ブロックを開き、モデル名をクリックすると細かい設定が行えます。下にスクロールすると Size of cont… (Size of content window) があるので、そこのチェックを外すか、「4096」を入力します。
Continue (VS Code 用拡張機能)
コンフィグファイル config.json の LLM の設定内、contextLength と maxTokens それぞれを 4096 と 2048 に変更します (maxTokensは LLMで生成されるトークンの最大値なので、半分にしています)。コンフィグファイルは Continue ペインのギアアイコンから開けます。
{
"title": "Chat: llama3.1:8b-instruct-fp16",
"provider": "ollama",
"model": "llama3.1:8b-instruct-fp16",
"apiBase": "http://localhost:11434",
"contextLength": 4096,
"completionOptions": {
"temperature": 0.5,
"top_p": "0.5",
"top_k": "40",
"maxTokens": 2048,
"keepAlive": 3600
}
}LLM のコンテキストサイズを調べる
一番簡単なのは、Ollama のコマンドollama show <modelname>を使う方法です。context length として表示されます。実行例:
% ollama show llama3.1:8b-instruct-fp16
Model
arch llama
parameters 8.0B
quantization F16
context length 131072
embedding length 4096
Parameters
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024アプリケーションにモデルを追加する時のコンテキストサイズ指定
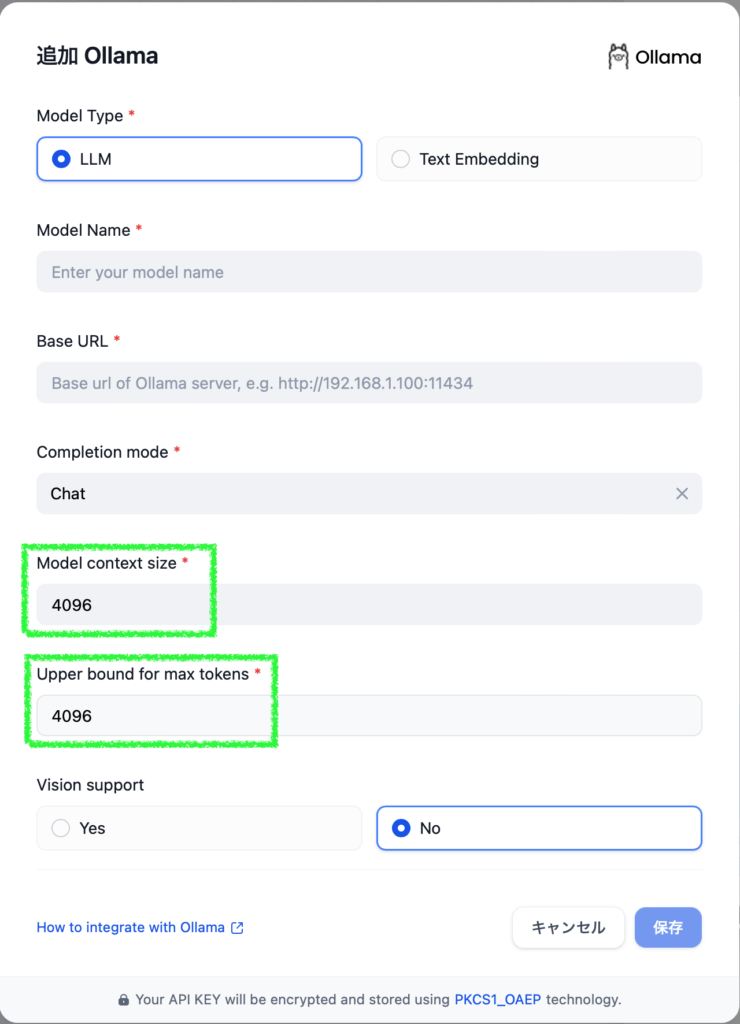
Dify のモデルプロバイダー Ollama
Dify に Ollama の LLM を追加する際、デフォルトで 4096 になっているところを上書きすることで、モデルのキャパシティ (Model context size) と生成されるトークンの上限 (Uper bound for max tokens) を設定できます。ただ上限をここでかけてしまうと作った AI アプリ側で不具合が出たときにデバッグしづらいので、追加の際にはどちらもモデルのコンテキストサイズ (context length の値) を入れておくのが良いと思います。そして、AI アプリ側の Size of content window で後述するほどよいコンテキストサイズを指定しましょう。
Continue の “models”
Continue の場合、設定内容はモデルを選択したときに使われるので、titleにコンテキストサイズに関する説明 (Fastest Max Size とか 4096 とか) を入れて、同じモデルで複数の異なったコンテキストサイズの設定を用意しておいても良いかもしれません。以下は、ボクが実際に 32GB RAM の M2 Max で試して Llama 3.1 (8B) の高速動作が確認できた値を入れてあります。Dify とは異なり、maxTokensはcontextLengthと同じ値だとエラーになるため、半分にします。
{
"title": "Chat: llama3.1:8b-instruct-fp16 (Fastest Max Size)",
"provider": "ollama",
"model": "llama3.1:8b-instruct-fp16",
"apiBase": "http://localhost:11434",
"contextLength": 24576,
"completionOptions": {
"temperature": 0.5,
"top_p": "0.5",
"top_k": "40",
"maxTokens": 12288,
"keepAlive": 3600
}
}LLM の処理が重いとき、何が起こっているか (状況からの想定)
ollama runで使用すると速いのに他のアプリから Ollama サーバ経由で使用すると重いのは、上記の通りコンテキストサイズが大きいことが原因のひとつです。実際に LLM が動作しているときに、ollama psコマンドを叩いてみましょう。以下は実行例ですが、上がモデルのコンテキストサイズ最大値を設定して反応が重い時、下がサイズを小さくして反応が速い時の出力です。SIZEとPROCESSORの下に書かれている内容に注目してください。
% ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b-instruct-fp16 a8f4d8643bb2 49 GB 54%/46% CPU/GPU 59 minutes from now
% ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b-instruct-fp16 a8f4d8643bb2 17 GB 100% GPU 4 minutes from now重い時のSIZEは実モデルのサイズ (16 GB) よりもかなり大きい 49 GB となり、処理は CPU で 54%、GPU で 46% 行っています。ウラを取っていませんが、Ollama は実際に処理しているトークン数にかかわらず API で大きなコンテキストサイズを受け取ると、LLM のサイズ自体を大きく処理するようです。そのため、GPU の VRAM サイズを超えたモデルを動かしていると認識されるので (ユニファイドメモリの Mac ではほぼ意味がないですが) CPU とその配下の RAM も動員し、場合によってスワップも使用して処理するのでとてつもなく遅くなる、のであろうと考えています。そういう仕様なのだろうと。
ほどよいコンテキストサイズの値を見つける
さて、状況証拠からおおよその理由がわかったので、対策を取ります。4096トークンでまかなえるのであればそれで構いませんが、可能な限り大きなトークンを処理したいですよね。Ollama の仕様を見つけられれば良かったのですが諦め、手作業コンテキストサイズを 4096 の倍数で増減させながらチャットを繰り返し、PROCESSOR 100% GPUになる値を見つけ出しました。それが、24576 (4096*6) です。Llama 3.1 8B の F16 と DeepSeek-Corder-V2-Lite-Instruct の Q6_K なら 100% GPU で動きます。32 GB 以外のユニファイドメモリの方は、同様の方法で見つけ出してください。使った感じ、CPU 10%、GPU 90% くらいでも十分な速度が得られましたが、4096 の倍数以外の数字を使うと文字化けが発生したので、そこはご注意ください (DeepSeek-Corder-V2-Lite-Instruct の Q8_0 が該当)。また、Dify で同じコンテキストサイズを使った場合、Continue よりもSIZEが小さくなります。欲張ればもう少し増やせるかもしれませんので、必要に応じて試す価値はありそうです。時間はかかっても良いので長文を処理したい、原文を分割したくない、なんてケースでは、LLM の持つキャパを最大限使うという選択肢もアリだと思います。
(追記) 後日書いた記事 ↓ で、より多くの RAM 容量を GPU に使わせる方法を説明しています。上の方法で 100% GPU で動くコンテキスト値がわかったら、下の方法で VRAM を増やし、1024 トークンずつ増やすことで極限まで大きいトークン数を扱うことができるようになります。場合によっては大きいモデル、量子化モデルも使えますのでお試しください。
Ollama、疑ってごめんね (読まなくて良い話)
Ollama 自体で動かしたら速いのに、API 経由で使うととてつもなく遅くなるんだから、Ollama のバグに違いない!サーバの処理がおかしいんだ!と決めつけて調べていたのですが、Windows 版で GPU を使ってくれないという Issue のやりとりにあった「context size を 4096 にして試したまえ」というアドバイスにハッとし、実際に試してみるとウソのように解決しました。Ollama さん、盛大に疑ってごめんなさい。
一番大きいモデルサイズは DeepSeek-Corder-V2 で 236B、Llama 3.1 にもなると 405B と完全なる貴族仕様で、利用可能なコンテキストサイズはそのまま小さな庶民サイズのモデルにも適用されています。もしかしたら将来的に Ollama サーバでは違う処理がされるのかもしれませんが、 少なくとも 2024年の晩夏現在、一般庶民 (レベルの RAM 容量) で快適に LLM を使うには、コンテキストサイズを自分で調整する必要がある、ということを学びました。
Image by Stable Diffusion (Mochi Diffusion)
小さなバイクが、ゴージャスなバンだかキャンピングカーだかピックアップトラックだかを抜き去る画像が欲しかったんですけど、バイク vs バイクだったり、逆車線で単純にすれ違っただけだったり、バンが見切れてたり、ただただバイクがかっこよく走ってるだけだったり、と非常に苦戦!疾走感が無いですが、小さい方が速い感を出せてるこれにキメタ!
Date:
2024年9月1日 2:57:00
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
A high-speed motorcycle overtaking a luxurious van
Exclude from Image:
Seed:
2448773039
Steps:
20
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
All