

普段あまり使わない Open WebUI をいじっていたら、普通に gpt-oss の思考部分を隠せるとわかりました。さらに、2ラウンド以降のチャットも問題無く動きますね。まだサポートされていないと思っていたなんてお恥ずかしい。いやまったく、おハズです。せっかくなのでやり方共有します。これ以上おハズな人が増えないように。
しかし同様の方法は Dify + MLX-LM では使えません (よね?)。なので、Dify 用には MLX-LM API サーバの魔改造で対応します。
(2026/02/02 追記) 魔改造はもう不要!多分どんな環境でも動きそうな gpt-oss 専用の汎用プロキシサーバを書きました ↓
Contents
Open WebUI で gpt-oss の思考部分を隠す正攻法
簡単な話なので、ささっと行きましょう。
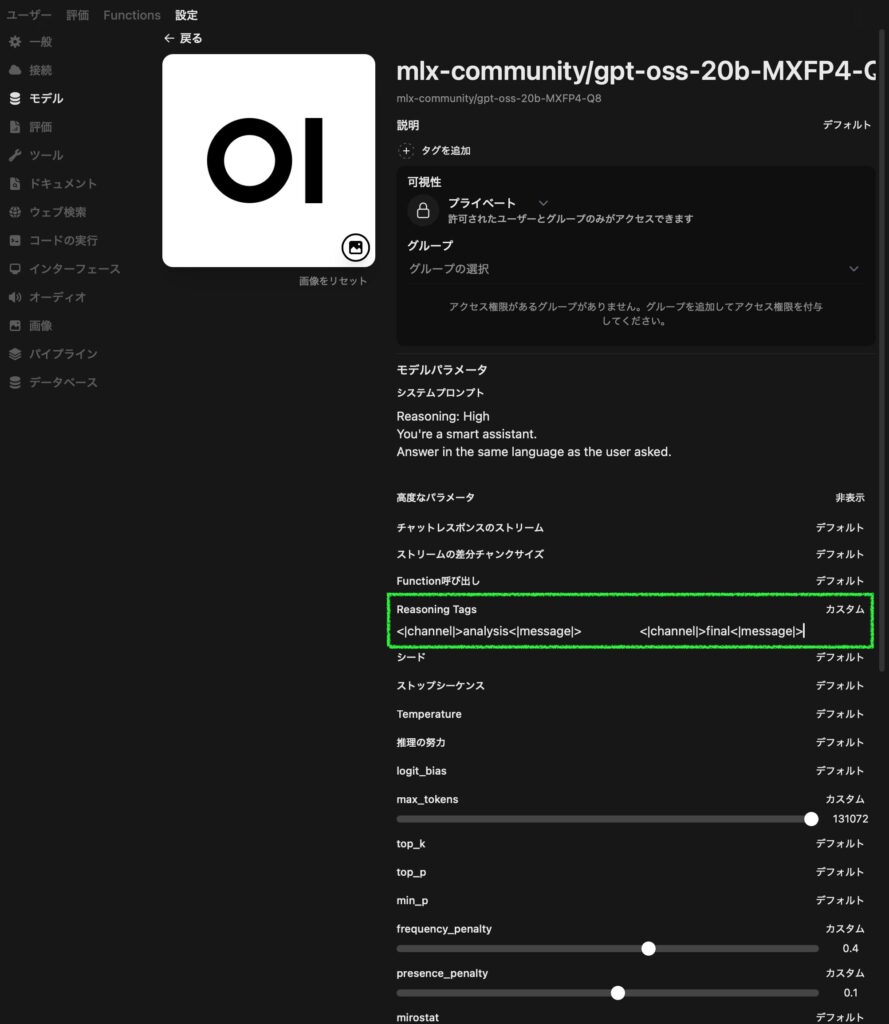
(1) 右上のユーザアイコン → 管理者パネル → 設定 → モデル → gpt-oss のモデル名または右にある鉛筆アイコンをクリック
(2) 高度なパラメータの右の「表示」→ Reasoning Tags の「デフォルト」をクリックして「カスタム」にし、以下の内容を入力:
Start Tag: <|channel|>analysis<|message|>
End Tag: <|end|><|start|>assistant<|channel|>final<|message|>
(3) 一番下にスクロールして「保存して更新」
以下のスクリーンショットの様になっていれば OK です。
本件に直接関係ないですが、スクリーンショットでは他に、MLX の強みでコンテキスト長を最大にし (max_tokens:131072)、同じ言葉がリピートする問題を抑えるための設定 (frequency_penalty:0.4と presence_penalty:0.1) をしています←最適解が見つからず、試行錯誤中です。システムプロンプトのReasoning: Highは効かないですね (できました!↓)。同様に「推論の努力」をhighにしてもlowにしても gpt-oss に効いているのかはよくわかりません。
(2025/09/15 追記) 新たなる魔改造を持って MLX-LM でReasoning: Highを効かせることに成功しました → gpt-oss の Reasoning レベル変更を MLX-LM でもできるようにする魔改造
思考中の様子:
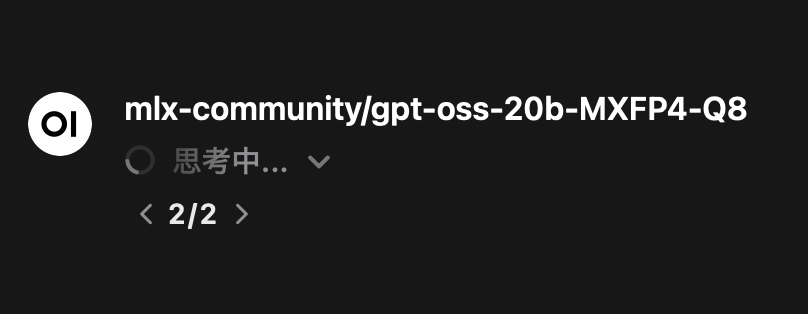
下向き v をクリックすると思考の様子が展開されます。完了すると思考にかかった時間が表示されます:
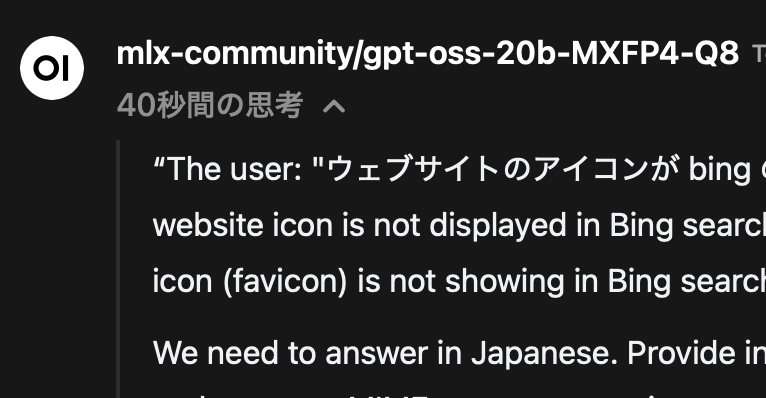
こうすると思考部分は LLM に送られなくなるようで、2ラウンド以降のチャットも問題無くできます。Open WebUI すばらしい (イマサラ)!Dify にも欲しいな、この設定。
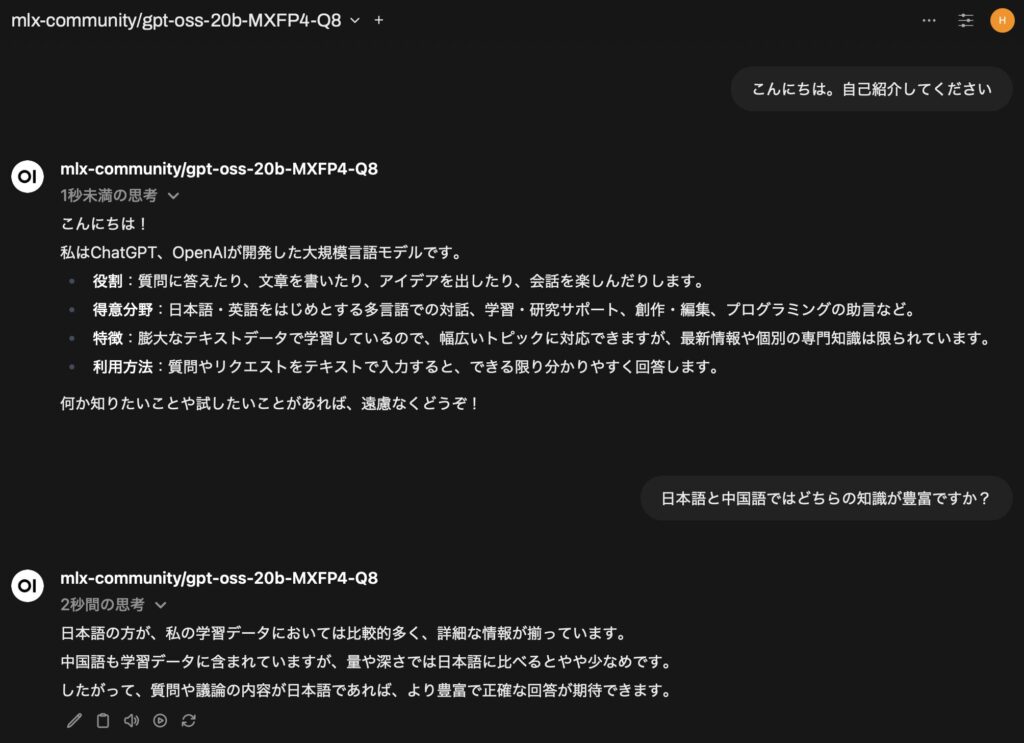
MLX-LM を API サーバとして Open WebUI から使う方法はこちらの記事にまとめています。
Dify から MLX-LM API 経由の gpt-oss は本当に使えないのか確認
Dify の OpenAI-API-compatible プラグインの version 0.0.20 でテスト済みです。もしかしたら新しいバージョンではそもそも gpt-oss に対応済みの可能性もあるため、更新履歴を見てみましょう。0.0.21 と 0.0.22 が出てました。
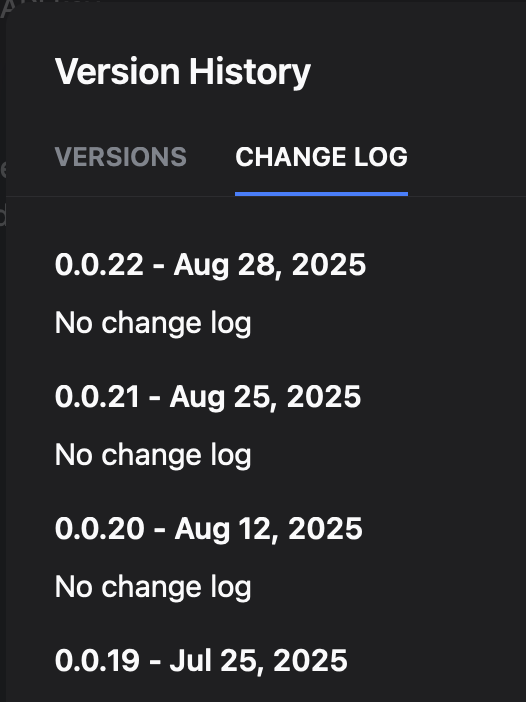
何が変更されたのかわかりませんが、ともあれ問題が発生しても古いバージョンがインストールできそうなので、最新の 0.0.22 にしてみます。しかしモデルの追加・利用のそれぞれで設定可能な項目は以前と変わりませんでした。
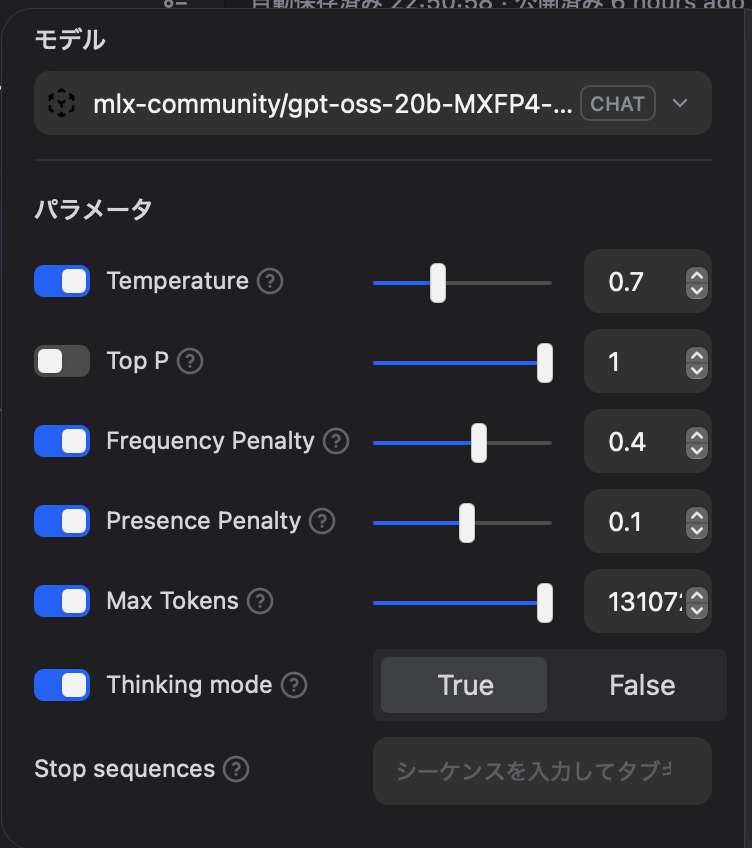
プレビューでチャットしてみると思考部分は丸見えで 2ラウンド以降のチャットはエラー発生。ここも以前と変わらず。

はい、というわけで、魔改造の出番ですね。へっへっへ
Dify から MLX-LM API 経由の gpt-oss を使う魔改造
※ 動作確認済みのバージョンはMLX-LM: 0.27.0です。
本ブログでは何度もやっている、mlx-lm の server.py の改造ですが、今回はけっこうやっちゃってます。オリジナルのスクリプトは必ずバックアップしてからすすめてください。
前回記事からの変更内容は、言ってしまえば簡単で、<|channel|>analysis<|message|>から<|channel|>final<|message|>までを<details></details>で囲っているだけです。
サーバ側で思考部分を受け取っても廃棄する改造を行った前回記事はこちら:
★ スクリプト全てを見るにはここをクリック ★ (1194行あります)
# Copyright © 2023-2024 Apple Inc.
import argparse
import json
import logging
import platform
import socket
import time
import uuid
import warnings
from dataclasses import dataclass, field
from http.server import BaseHTTPRequestHandler, HTTPServer
from pathlib import Path
from typing import (
Any,
Dict,
List,
Literal,
NamedTuple,
Optional,
Sequence,
Tuple,
Union,
)
import mlx.core as mx
from huggingface_hub import scan_cache_dir
from ._version import __version__
from .generate import stream_generate
from .models.cache import can_trim_prompt_cache, make_prompt_cache, trim_prompt_cache
from .sample_utils import make_logits_processors, make_sampler
from .utils import common_prefix_len, load
def get_system_fingerprint():
gpu_arch = mx.metal.device_info()["architecture"] if mx.metal.is_available() else ""
return f"{__version__}-{mx.__version__}-{platform.platform()}-{gpu_arch}"
class StopCondition(NamedTuple):
stop_met: bool
trim_length: int
def stopping_criteria(
tokens: List[int],
stop_id_sequences: List[List[int]],
eos_token_id: Union[int, None],
) -> StopCondition:
"""
Determines whether the token generation should stop based on predefined
conditions.
Args:
tokens (List[int]): The current sequence of generated tokens.
stop_id_sequences (List[List[[int]]): A list of integer lists, each
representing a sequence of token IDs. If the end of the `tokens`
list matches any of these sequences, the generation should stop.
eos_token_id (Union[int, None]): The token ID that represents the
end-of-sequence. If the last token in `tokens` matches this, the
generation should stop.
Returns:
StopCondition: A named tuple indicating whether the stop condition has
been met (`stop_met`) and how many tokens should be trimmed from the
end if it has (`trim_length`).
"""
if tokens and tokens[-1] == eos_token_id:
return StopCondition(stop_met=True, trim_length=0)
for stop_ids in stop_id_sequences:
if len(tokens) >= len(stop_ids):
if tokens[-len(stop_ids) :] == stop_ids:
return StopCondition(stop_met=True, trim_length=len(stop_ids))
return StopCondition(stop_met=False, trim_length=0)
def sequence_overlap(s1: Sequence, s2: Sequence) -> bool:
"""
Checks if a suffix of s1 has overlap with a prefix of s2
Args:
s1 (Sequence): The first sequence
s2 (Sequence): The second sequence
Returns:
bool: If the two sequences have overlap
"""
max_overlap = min(len(s1), len(s2))
return any(s1[-i:] == s2[:i] for i in range(1, max_overlap + 1))
def convert_chat(messages: List[dict], role_mapping: Optional[dict] = None):
default_role_mapping = {
"system_prompt": (
"A chat between a curious user and an artificial intelligence "
"assistant. The assistant follows the given rules no matter what."
),
"system": "ASSISTANT's RULE: ",
"user": "USER: ",
"assistant": "ASSISTANT: ",
"stop": "\n",
}
role_mapping = role_mapping if role_mapping is not None else default_role_mapping
prompt = ""
for line in messages:
role_prefix = role_mapping.get(line["role"], "")
stop = role_mapping.get("stop", "")
content = line.get("content", "")
prompt += f"{role_prefix}{content}{stop}"
prompt += role_mapping.get("assistant", "")
return prompt.rstrip()
def process_message_content(messages):
"""
Convert message content to a format suitable for `apply_chat_template`.
The function operates on messages in place. It converts the 'content' field
to a string instead of a list of text fragments.
Args:
message_list (list): A list of dictionaries, where each dictionary may
have a 'content' key containing a list of dictionaries with 'type' and
'text' keys.
Raises:
ValueError: If the 'content' type is not supported or if 'text' is missing.
"""
for message in messages:
content = message["content"]
if isinstance(content, list):
text_fragments = [
fragment["text"] for fragment in content if fragment["type"] == "text"
]
if len(text_fragments) != len(content):
raise ValueError("Only 'text' content type is supported.")
message["content"] = "".join(text_fragments)
elif content is None:
message["content"] = ""
@dataclass
class PromptCache:
cache: List[Any] = field(default_factory=list)
model_key: Tuple[str, Optional[str]] = ("", None, None)
tokens: List[int] = field(default_factory=list)
class ModelProvider:
def __init__(self, cli_args: argparse.Namespace):
"""Load models on demand and persist them across the whole process."""
self.cli_args = cli_args
self.model_key = None
self.model = None
self.tokenizer = None
self.draft_model = None
# Preload the default model if it is provided
self.default_model_map = {}
if self.cli_args.model is not None:
self.default_model_map[self.cli_args.model] = "default_model"
self.load(self.cli_args.model, draft_model_path="default_model")
def _validate_model_path(self, model_path: str):
model_path = Path(model_path)
if model_path.exists() and not model_path.is_relative_to(Path.cwd()):
raise RuntimeError(
"Local models must be relative to the current working dir."
)
# Added in adapter_path to load dynamically
def load(self, model_path, adapter_path=None, draft_model_path=None):
model_path, adapter_path, draft_model_path = map(
lambda s: s.lower() if s else None,
(model_path, adapter_path, draft_model_path),
)
model_path = self.default_model_map.get(model_path, model_path)
if self.model_key == (model_path, adapter_path, draft_model_path):
return self.model, self.tokenizer
# Remove the old model if it exists.
self.model = None
self.tokenizer = None
self.model_key = None
self.draft_model = None
# Building tokenizer_config
tokenizer_config = {
"trust_remote_code": True if self.cli_args.trust_remote_code else None
}
if self.cli_args.chat_template:
tokenizer_config["chat_template"] = self.cli_args.chat_template
if model_path == "default_model":
if self.cli_args.model is None:
raise ValueError(
"A model path has to be given as a CLI "
"argument or in the HTTP request"
)
adapter_path = adapter_path or self.cli_args.adapter_path
model, tokenizer = load(
self.cli_args.model,
adapter_path=adapter_path,
tokenizer_config=tokenizer_config,
)
else:
self._validate_model_path(model_path)
model, tokenizer = load(
model_path, adapter_path=adapter_path, tokenizer_config=tokenizer_config
)
if self.cli_args.use_default_chat_template:
if tokenizer.chat_template is None:
tokenizer.chat_template = tokenizer.default_chat_template
self.model_key = (model_path, adapter_path, draft_model_path)
self.model = model
self.tokenizer = tokenizer
def validate_draft_tokenizer(draft_tokenizer):
# Check if tokenizers are compatible
if draft_tokenizer.vocab_size != tokenizer.vocab_size:
logging.warning(
"Draft model tokenizer does not match model tokenizer. "
"Speculative decoding may not work as expected."
)
# Load draft model if specified
if (
draft_model_path == "default_model"
and self.cli_args.draft_model is not None
):
self.draft_model, draft_tokenizer = load(self.cli_args.draft_model)
validate_draft_tokenizer(draft_tokenizer)
elif draft_model_path is not None and draft_model_path != "default_model":
self._validate_model_path(draft_model_path)
self.draft_model, draft_tokenizer = load(draft_model_path)
validate_draft_tokenizer(draft_tokenizer)
return self.model, self.tokenizer
class APIHandler(BaseHTTPRequestHandler):
def __init__(
self,
model_provider: ModelProvider,
*args,
prompt_cache: Optional[PromptCache] = None,
system_fingerprint: Optional[str] = None,
**kwargs,
):
"""
Create static request specific metadata
"""
self.created = int(time.time())
self.model_provider = model_provider
self.prompt_cache = prompt_cache or PromptCache()
self.system_fingerprint = system_fingerprint or get_system_fingerprint()
super().__init__(*args, **kwargs)
def _set_cors_headers(self):
self.send_header("Access-Control-Allow-Origin", "*")
self.send_header("Access-Control-Allow-Methods", "*")
self.send_header("Access-Control-Allow-Headers", "*")
def _set_completion_headers(self, status_code: int = 200):
self.send_response(status_code)
self.send_header("Content-type", "application/json")
self._set_cors_headers()
def _set_stream_headers(self, status_code: int = 200):
self.send_response(status_code)
self.send_header("Content-type", "text/event-stream")
self.send_header("Cache-Control", "no-cache")
self._set_cors_headers()
def do_OPTIONS(self):
self._set_completion_headers(204)
self.end_headers()
def do_POST(self):
"""
Respond to a POST request from a client.
"""
endpoints = {
"/v1/completions": self.handle_text_completions,
"/v1/chat/completions": self.handle_chat_completions,
"/chat/completions": self.handle_chat_completions,
}
if self.path not in endpoints:
self._set_completion_headers(404)
self.end_headers()
self.wfile.write(b"Not Found")
return
# Fetch and parse request body
content_length = int(self.headers["Content-Length"])
raw_body = self.rfile.read(content_length)
try:
self.body = json.loads(raw_body.decode())
except json.JSONDecodeError as e:
logging.error(f"JSONDecodeError: {e} - Raw body: {raw_body.decode()}")
# Set appropriate headers based on streaming requirement
if self.stream:
self._set_stream_headers(400)
self.wfile.write(
f"data: {json.dumps({'error': f'Invalid JSON in request body: {e}'})}\n\n".encode()
)
else:
self._set_completion_headers(400)
self.wfile.write(
json.dumps({"error": f"Invalid JSON in request body: {e}"}).encode()
)
return
indent = "\t" # Backslashes can't be inside of f-strings
logging.debug(f"Incoming Request Body: {json.dumps(self.body, indent=indent)}")
assert isinstance(
self.body, dict
), f"Request should be dict, but got {type(self.body)}"
# Extract request parameters from the body
self.stream = self.body.get("stream", False)
self.stream_options = self.body.get("stream_options", None)
self.requested_model = self.body.get("model", "default_model")
self.requested_draft_model = self.body.get("draft_model", "default_model")
self.num_draft_tokens = self.body.get(
"num_draft_tokens", self.model_provider.cli_args.num_draft_tokens
)
self.adapter = self.body.get("adapters", None)
self.max_tokens = self.body.get("max_completion_tokens", None)
if self.max_tokens is None:
self.max_tokens = self.body.get(
"max_tokens", self.model_provider.cli_args.max_tokens
)
self.temperature = self.body.get(
"temperature", self.model_provider.cli_args.temp
)
self.top_p = self.body.get("top_p", self.model_provider.cli_args.top_p)
self.top_k = self.body.get("top_k", self.model_provider.cli_args.top_k)
self.min_p = self.body.get("min_p", self.model_provider.cli_args.min_p)
self.repetition_penalty = self.body.get("repetition_penalty", 1.0)
self.repetition_context_size = self.body.get("repetition_context_size", 20)
self.xtc_probability = self.body.get("xtc_probability", 0.0)
self.xtc_threshold = self.body.get("xtc_threshold", 0.0)
self.logit_bias = self.body.get("logit_bias", None)
self.logprobs = self.body.get("logprobs", -1)
self.validate_model_parameters()
# Load the model if needed
try:
self.model, self.tokenizer = self.model_provider.load(
self.requested_model,
self.adapter,
self.requested_draft_model,
)
except:
self._set_completion_headers(404)
self.end_headers()
self.wfile.write(b"Not Found")
return
# Get stop id sequences, if provided
stop_words = self.body.get("stop")
stop_words = stop_words or []
stop_words = [stop_words] if isinstance(stop_words, str) else stop_words
stop_id_sequences = [
self.tokenizer.encode(stop_word, add_special_tokens=False)
for stop_word in stop_words
]
# Send header type
(
self._set_stream_headers(200)
if self.stream
else self._set_completion_headers(200)
)
# Call endpoint specific method
prompt = endpoints[self.path]()
self.handle_completion(prompt, stop_id_sequences)
def validate_model_parameters(self):
"""
Validate the model parameters passed in the request for the correct types and values.
"""
if not isinstance(self.stream, bool):
raise ValueError("stream must be a boolean")
if not isinstance(self.max_tokens, int) or self.max_tokens < 0:
raise ValueError("max_tokens must be a non-negative integer")
if not isinstance(self.temperature, (float, int)) or self.temperature < 0:
raise ValueError("temperature must be a non-negative float")
if not isinstance(self.top_p, (float, int)) or self.top_p < 0 or self.top_p > 1:
raise ValueError("top_p must be a float between 0 and 1")
if not isinstance(self.top_k, int) or self.top_k < 0:
raise ValueError("top_k must be a non-negative integer")
if not isinstance(self.min_p, (float, int)) or self.min_p < 0 or self.min_p > 1:
raise ValueError("min_p must be a float between 0 and 1")
if not isinstance(self.num_draft_tokens, int) or self.num_draft_tokens < 0:
raise ValueError("num_draft_tokens must be a non-negative integer")
if (
not isinstance(self.repetition_penalty, (float, int))
or self.repetition_penalty < 0
):
raise ValueError("repetition_penalty must be a non-negative float")
if self.logprobs != -1 and not (0 < self.logprobs <= 10):
raise ValueError(
f"logprobs must be between 1 and 10 but got {self.logprobs:,}"
)
if (
not isinstance(self.repetition_context_size, int)
or self.repetition_context_size < 0
):
raise ValueError("repetition_context_size must be a non-negative integer")
if self.logit_bias is not None:
if not isinstance(self.logit_bias, dict):
raise ValueError("logit_bias must be a dict of int to float")
try:
self.logit_bias = {int(k): v for k, v in self.logit_bias.items()}
except ValueError:
raise ValueError("logit_bias must be a dict of int to float")
if not (
isinstance(self.xtc_probability, float)
and 0.00 <= self.xtc_probability <= 1.00
):
raise ValueError(f"xtc_probability must be a float between 0.00 and 1.00")
if not (
isinstance(self.xtc_threshold, float) and 0.00 <= self.xtc_threshold <= 0.50
):
raise ValueError(f"xtc_threshold must be a float between 0.00 and 0.5")
if not isinstance(self.requested_model, str):
raise ValueError("model must be a string")
if self.adapter is not None and not isinstance(self.adapter, str):
raise ValueError("adapter must be a string")
def generate_response(
self,
text: str,
finish_reason: Union[Literal["length", "stop"], None],
prompt_token_count: Optional[int] = None,
completion_token_count: Optional[int] = None,
token_logprobs: Optional[List[float]] = None,
top_tokens: Optional[List[Dict[int, float]]] = None,
tokens: Optional[List[int]] = None,
tool_calls: Optional[List[str]] = None,
) -> dict:
"""
Generate a single response packet based on response type (stream or
not), completion type and parameters.
Args:
text (str): Text generated by model
finish_reason (Union[Literal["length", "stop"], None]): The reason the
response is being sent: "length", "stop" or `None`.
prompt_token_count (Optional[int]): The number of tokens in the prompt,
used to populate the "usage" field (not used when stream).
completion_token_count (Optional[int]): The number of tokens in the
response, used to populate the "usage" field (not used when stream).
token_logprobs (Optional[List[float]]): The log probabilities per token,
in token order.
top_tokens (Optional[List[Dict[int, float]]]): List of dictionaries mapping
tokens to logprobs for the top N tokens at each token position.
tokens (Optional[List[int]]): List of tokens to return with logprobs structure
tool_calls (Optional[List[str]]): List of tool calls.
Returns:
dict: A dictionary containing the response, in the same format as
OpenAI's API.
"""
token_logprobs = token_logprobs or []
top_logprobs = top_tokens or []
tool_calls = tool_calls or []
def parse_function(tool_text):
tool_call = json.loads(tool_text.strip())
return {
"function": {
"name": tool_call.get("name", None),
"arguments": json.dumps(tool_call.get("arguments", "")),
},
"type": "function",
"id": None,
}
# Static response
response = {
"id": self.request_id,
"system_fingerprint": self.system_fingerprint,
"object": self.object_type,
"model": self.requested_model,
"created": self.created,
"choices": [
{
"index": 0,
"finish_reason": finish_reason,
},
],
}
if token_logprobs or top_logprobs or tokens:
response["choices"][0]["logprobs"] = {
"token_logprobs": token_logprobs,
"top_logprobs": top_logprobs,
"tokens": tokens,
}
if not self.stream:
if not (
isinstance(prompt_token_count, int)
and isinstance(completion_token_count, int)
):
raise ValueError(
"Response type is complete, but token counts not provided"
)
response["usage"] = {
"prompt_tokens": prompt_token_count,
"completion_tokens": completion_token_count,
"total_tokens": prompt_token_count + completion_token_count,
}
choice = response["choices"][0]
# Add dynamic response
if self.object_type.startswith("chat.completion"):
key_name = "delta" if self.stream else "message"
choice[key_name] = {
"role": "assistant",
"content": text,
"tool_calls": [parse_function(tool_text) for tool_text in tool_calls],
}
elif self.object_type == "text_completion":
choice.update(text=text)
else:
raise ValueError(f"Unsupported response type: {self.object_type}")
return response
def reset_prompt_cache(self, prompt):
"""Resets the prompt cache and associated state.
Args:
prompt (List[int]): The tokenized new prompt which will populate the
reset cache.
"""
logging.debug(f"*** Resetting cache. ***")
self.prompt_cache.model_key = self.model_provider.model_key
self.prompt_cache.cache = make_prompt_cache(self.model_provider.model)
if self.model_provider.draft_model is not None:
self.prompt_cache.cache += make_prompt_cache(
self.model_provider.draft_model
)
self.prompt_cache.tokens = list(prompt) # Cache the new prompt fully
def get_prompt_cache(self, prompt):
"""
Determines the portion of the prompt that needs processing by comparing
it to the cached prompt and attempting to reuse the common prefix.
This function updates the internal prompt cache state (tokens and model cache)
based on the comparison. If a common prefix exists, it attempts to trim
the model cache (if supported) to match the common prefix length, avoiding
recomputation.
Args:
prompt (List[int]): The tokenized new prompt.
Returns:
List[int]: The suffix of the prompt that actually needs to be processed
by the model. This will be the full prompt if the cache is
reset or cannot be effectively used.
"""
cache_len = len(self.prompt_cache.tokens)
prompt_len = len(prompt)
com_prefix_len = common_prefix_len(self.prompt_cache.tokens, prompt)
# Leave at least one token in the prompt
com_prefix_len = min(com_prefix_len, len(prompt) - 1)
# Condition 1: Model changed or no common prefix at all. Reset cache.
if (
self.prompt_cache.model_key != self.model_provider.model_key
or com_prefix_len == 0
):
self.reset_prompt_cache(prompt)
# Condition 2: Common prefix exists and matches cache length. Process suffix.
elif com_prefix_len == cache_len:
logging.debug(
f"*** Cache is prefix of prompt (cache_len: {cache_len}, prompt_len: {prompt_len}). Processing suffix. ***"
)
prompt = prompt[com_prefix_len:]
self.prompt_cache.tokens.extend(prompt)
# Condition 3: Common prefix exists but is shorter than cache length. Attempt trim.
elif com_prefix_len < cache_len:
logging.debug(
f"*** Common prefix ({com_prefix_len}) shorter than cache ({cache_len}). Attempting trim. ***"
)
if can_trim_prompt_cache(self.prompt_cache.cache):
num_to_trim = cache_len - com_prefix_len
logging.debug(f" Trimming {num_to_trim} tokens from cache.")
trim_prompt_cache(self.prompt_cache.cache, num_to_trim)
self.prompt_cache.tokens = self.prompt_cache.tokens[:com_prefix_len]
prompt = prompt[com_prefix_len:]
self.prompt_cache.tokens.extend(prompt)
else:
logging.debug(f" Cache cannot be trimmed. Resetting cache.")
self.reset_prompt_cache(prompt)
# This case should logically not be reached if com_prefix_len <= cache_len
else:
logging.error(
f"Unexpected cache state: com_prefix_len ({com_prefix_len}) > cache_len ({cache_len}). Resetting cache."
)
self.reset_prompt_cache(prompt)
logging.debug(f"Returning {len(prompt)} tokens for processing.")
return prompt
def handle_completion(
self,
prompt: List[int],
stop_id_sequences: List[List[int]],
):
"""
Generate a response to a prompt and send it to the client in a single batch.
Args:
prompt (List[int]): The tokenized prompt.
stop_id_sequences (List[List[int]]): A list of stop words passed
to the stopping_criteria function
"""
tokens = []
finish_reason = "length"
stop_sequence_suffix = None
if self.stream:
self.end_headers()
logging.debug(f"Starting stream:")
else:
logging.debug(f"Starting completion:")
token_logprobs = []
top_tokens = []
prompt = self.get_prompt_cache(prompt)
text = ""
tic = time.perf_counter()
sampler = make_sampler(
self.temperature,
top_p=self.top_p,
top_k=self.top_k,
min_p=self.min_p,
xtc_probability=self.xtc_probability,
xtc_threshold=self.xtc_threshold,
xtc_special_tokens=[
self.tokenizer.eos_token_id,
self.tokenizer.encode("\n"),
],
)
logits_processors = make_logits_processors(
self.logit_bias,
self.repetition_penalty,
self.repetition_context_size,
)
tool_calls = []
tool_text = ""
in_tool_call = False
segment = ""
# --- ▼▼▼ ここから追加 ▼▼▼ ---
# レスポンス形式を整形するための状態管理変数を初期化
gemma_buffer = ""
# 状態: INITIAL -> BUFFERING -> AWAITING_FINAL -> STREAMING
gemma_state = "INITIAL"
# --- ▲▲▲ ここまで追加 ▲▲▲ ---
# Create keepalive callback to send SSE comments during long prompt processing
def keepalive_callback(processed_tokens, total_tokens):
logging.info(
f"Prompt processing progress: {processed_tokens}/{total_tokens}"
)
if self.stream:
try:
# Send SSE comment for keepalive - invisible to clients but keeps connection alive
self.wfile.write(
f": keepalive {processed_tokens}/{total_tokens}\n\n".encode()
)
self.wfile.flush()
except (BrokenPipeError, ConnectionResetError, OSError):
# Client disconnected, ignore
pass
for gen_response in stream_generate(
model=self.model,
tokenizer=self.tokenizer,
prompt=prompt,
max_tokens=self.max_tokens,
sampler=sampler,
logits_processors=logits_processors,
prompt_cache=self.prompt_cache.cache,
draft_model=self.model_provider.draft_model,
num_draft_tokens=self.num_draft_tokens,
prompt_progress_callback=keepalive_callback,
):
logging.debug(gen_response.text)
if (
self.tokenizer.has_tool_calling
and gen_response.text == self.tokenizer.tool_call_start
):
in_tool_call = True
elif in_tool_call:
if gen_response.text == self.tokenizer.tool_call_end:
tool_calls.append(tool_text)
tool_text = ""
in_tool_call = False
else:
tool_text += gen_response.text
else:
# --- ▼▼▼ ここから変更 ▼▼▼ ---
# ストリーミングが有効、かつツールコール中でない場合に整形処理を実行
if self.stream and not in_tool_call:
gemma_buffer += gen_response.text
segment_to_send = ""
# 状態: 初期状態。レスポンス形式を判定する
if gemma_state == "INITIAL":
if "<|channel|>" in gemma_buffer:
gemma_state = "BUFFERING"
elif len(gemma_buffer) > 11: # len("<|channel|>")
gemma_state = "STREAMING"
# 状態: バッファリング中。analysisシーケンスを探す
if gemma_state == "BUFFERING":
analysis_seq = "<|channel|>analysis<|message|>"
if analysis_seq in gemma_buffer:
segment_to_send = gemma_buffer.replace(analysis_seq, f"<details>{analysis_seq}")
gemma_buffer = ""
gemma_state = "AWAITING_FINAL"
# 状態: finalシーケンスを待機中
if gemma_state == "AWAITING_FINAL":
final_seq = "<|channel|>final<|message|>"
if final_seq in gemma_buffer:
segment_to_send += gemma_buffer.replace(final_seq, f"{final_seq}</details> ")
gemma_buffer = ""
gemma_state = "STREAMING"
else:
# シーケンスがトークン境界で分割される可能性を考慮し、
# バッファの末尾(シーケンス長-1)文字を残して送信
safe_flush_len = len(gemma_buffer) - (len(final_seq) - 1)
if safe_flush_len > 0:
segment_to_send += gemma_buffer[:safe_flush_len]
gemma_buffer = gemma_buffer[safe_flush_len:]
# 状態: 通常ストリーミング。バッファをすべて送信
if gemma_state == "STREAMING":
segment_to_send += gemma_buffer
gemma_buffer = ""
# 処理したテキストを送信セグメントと全体テキストに追加
segment += segment_to_send
text += segment_to_send
else:
# ストリーミングでない場合やツールコール中は元の動作
text += gen_response.text
segment += gen_response.text
# --- ▲▲▲ ここまで変更 ▲▲▲ ---
token = gen_response.token
logprobs = gen_response.logprobs
tokens.append(token)
self.prompt_cache.tokens.append(token)
if self.logprobs > 0:
sorted_indices = mx.argpartition(-logprobs, kth=self.logprobs - 1)
top_indices = sorted_indices[: self.logprobs]
top_logprobs = logprobs[top_indices]
top_token_info = zip(top_indices.tolist(), top_logprobs.tolist())
top_tokens.append(tuple(top_token_info))
token_logprobs.append(logprobs[token].item())
stop_condition = stopping_criteria(
tokens, stop_id_sequences, self.tokenizer.eos_token_id
)
if stop_condition.stop_met:
finish_reason = "stop"
if stop_condition.trim_length:
stop_sequence_suffix = self.tokenizer.decode(
tokens[-stop_condition.trim_length :]
)
text = text[: -len(stop_sequence_suffix)]
segment = ""
break
if self.stream and not in_tool_call:
# If the end of tokens overlaps with a stop sequence, generate new
# tokens until we know if the stop sequence is hit or not
if any(
(
sequence_overlap(tokens, sequence)
for sequence in stop_id_sequences
)
):
continue
elif segment or tool_calls:
response = self.generate_response(
segment, None, tool_calls=tool_calls
)
self.wfile.write(f"data: {json.dumps(response)}\n\n".encode())
self.wfile.flush()
segment = ""
tool_calls = []
# --- ▼▼▼ ここから追加 ▼▼▼ ---
# ループ終了後、バッファにデータが残っていれば最後のセグメントに追加
if gemma_buffer:
segment += gemma_buffer
gemma_buffer = ""
# --- ▲▲▲ ここまで追加 ▲▲▲ ---
if gen_response.finish_reason is not None:
finish_reason = gen_response.finish_reason
logging.debug(f"Prompt: {gen_response.prompt_tps:.3f} tokens-per-sec")
logging.debug(f"Generation: {gen_response.generation_tps:.3f} tokens-per-sec")
logging.debug(f"Peak memory: {gen_response.peak_memory:.3f} GB")
if self.stream:
response = self.generate_response(
segment, finish_reason, tool_calls=tool_calls
)
self.wfile.write(f"data: {json.dumps(response)}\n\n".encode())
self.wfile.flush()
if self.stream_options is not None and self.stream_options["include_usage"]:
original_prompt_length = (
len(self.prompt_cache.tokens) - len(tokens) + len(prompt)
)
response = self.completion_usage_response(
original_prompt_length, len(tokens)
)
self.wfile.write(f"data: {json.dumps(response)}\n\n".encode())
self.wfile.flush()
self.wfile.write("data: [DONE]\n\n".encode())
self.wfile.flush()
else:
response = self.generate_response(
text,
finish_reason,
len(prompt),
len(tokens),
token_logprobs=token_logprobs,
top_tokens=top_tokens,
tokens=tokens,
tool_calls=tool_calls,
)
response_json = json.dumps(response).encode()
indent = "\t" # Backslashes can't be inside of f-strings
logging.debug(f"Outgoing Response: {json.dumps(response, indent=indent)}")
# Send an additional Content-Length header when it is known
self.send_header("Content-Length", str(len(response_json)))
self.end_headers()
self.wfile.write(response_json)
self.wfile.flush()
def completion_usage_response(
self,
prompt_token_count: Optional[int] = None,
completion_token_count: Optional[int] = None,
):
response = {
"id": self.request_id,
"system_fingerprint": self.system_fingerprint,
"object": "chat.completion",
"model": self.requested_model,
"created": self.created,
"choices": [],
"usage": {
"prompt_tokens": prompt_token_count,
"completion_tokens": completion_token_count,
"total_tokens": prompt_token_count + completion_token_count,
},
}
return response
def handle_chat_completions(self) -> List[int]:
"""
Handle a chat completion request.
Returns:
mx.array: A mx.array of the tokenized prompt from the request body
"""
body = self.body
assert "messages" in body, "Request did not contain messages"
# Determine response type
self.request_id = f"chatcmpl-{uuid.uuid4()}"
self.object_type = "chat.completion.chunk" if self.stream else "chat.completion"
if self.tokenizer.chat_template:
messages = body["messages"]
# --- Changes from here ---
# Modify message based on the `mlx-lm` chat template.
for message in messages:
if message["role"] == "assistant":
content = message.get("content", "")
if "<|channel|>analysis<|message|>" in content and "<|channel|>final<|message|>" in content:
try:
analysis_start_tag = "<|channel|>analysis<|message|>"
analysis_end_tag = "<|end|>"
final_start_tag = "<|channel|>final<|message|>"
analysis_start = content.find(analysis_start_tag) + len(analysis_start_tag)
analysis_end = content.find(analysis_end_tag)
final_start = content.find(final_start_tag) + len(final_start_tag)
analysis = content[analysis_start:analysis_end].strip()
final = content[final_start:].strip()
message["content"] = final
message["thinking"] = analysis
except Exception as e:
logging.error(f"Failed to parse assistant message with analysis/final tags: {e}")
# If parsing fails, leave the content and empty thinking
message["thinking"] = ""
# --- to here ---
process_message_content(messages)
# Moved response_format before `apply_chat_template`
if body.get("response_format", {}).get("type") == "json_object":
if self.tokenizer.chat_template is None:
raise ValueError("JSON response format requested, but tokenizer has no chat template. Consider using `--use-default-chat-template`")
messages.append({"role": "user", "content": self.tokenizer.json_schema_prompt})
prompt = self.tokenizer.apply_chat_template(
messages,
body.get("tools") or None,
add_generation_prompt=True,
**self.model_provider.cli_args.chat_template_args,
)
else:
prompt = convert_chat(body["messages"], body.get("role_mapping"))
prompt = self.tokenizer.encode(prompt)
return prompt
def handle_text_completions(self) -> List[int]:
"""
Handle a text completion request.
Returns:
mx.array: A mx.array of the tokenized prompt from the request body
"""
# Determine response type
self.request_id = f"cmpl-{uuid.uuid4()}"
self.object_type = "text_completion"
assert "prompt" in self.body, "Request did not contain a prompt"
return self.tokenizer.encode(self.body["prompt"])
def do_GET(self):
"""
Respond to a GET request from a client.
"""
if self.path.startswith("/v1/models"):
self.handle_models_request()
elif self.path == "/health":
self.handle_health_check()
else:
self._set_completion_headers(404)
self.end_headers()
self.wfile.write(b"Not Found")
def handle_health_check(self):
"""
Handle a GET request for the /health endpoint.
"""
self._set_completion_headers(200)
self.end_headers()
self.wfile.write('{"status": "ok"}'.encode())
self.wfile.flush()
def handle_models_request(self):
"""
Handle a GET request for the /v1/models endpoint.
"""
self._set_completion_headers(200)
self.end_headers()
files = ["config.json", "model.safetensors.index.json", "tokenizer_config.json"]
parts = self.path.split("/")
filter_repo_id = None
if len(parts) > 3:
filter_repo_id = "/".join(parts[3:])
def probably_mlx_lm(repo):
if repo.repo_type != "model":
return False
if "main" not in repo.refs:
return False
if filter_repo_id is not None and repo.repo_id != filter_repo_id:
return False
file_names = {f.file_path.name for f in repo.refs["main"].files}
return all(f in file_names for f in files)
# Scan the cache directory for downloaded mlx models
hf_cache_info = scan_cache_dir()
downloaded_models = [
repo for repo in hf_cache_info.repos if probably_mlx_lm(repo)
]
# Create a list of available models
models = [
{
"id": repo.repo_id,
"object": "model",
"created": self.created,
}
for repo in downloaded_models
]
response = {"object": "list", "data": models}
response_json = json.dumps(response).encode()
self.wfile.write(response_json)
self.wfile.flush()
def run(
host: str,
port: int,
model_provider: ModelProvider,
server_class=HTTPServer,
handler_class=APIHandler,
):
server_address = (host, port)
prompt_cache = PromptCache()
infos = socket.getaddrinfo(
*server_address, type=socket.SOCK_STREAM, flags=socket.AI_PASSIVE
)
server_class.address_family, _, _, _, server_address = next(iter(infos))
httpd = server_class(
server_address,
lambda *args, **kwargs: handler_class(
model_provider,
prompt_cache=prompt_cache,
system_fingerprint=get_system_fingerprint(),
*args,
**kwargs,
),
)
warnings.warn(
"mlx_lm.server is not recommended for production as "
"it only implements basic security checks."
)
logging.info(f"Starting httpd at {host} on port {port}...")
httpd.serve_forever()
def main():
parser = argparse.ArgumentParser(description="MLX Http Server.")
parser.add_argument(
"--model",
type=str,
help="The path to the MLX model weights, tokenizer, and config",
)
parser.add_argument(
"--adapter-path",
type=str,
help="Optional path for the trained adapter weights and config.",
)
parser.add_argument(
"--host",
type=str,
default="127.0.0.1",
help="Host for the HTTP server (default: 127.0.0.1)",
)
parser.add_argument(
"--port",
type=int,
default=8080,
help="Port for the HTTP server (default: 8080)",
)
parser.add_argument(
"--draft-model",
type=str,
help="A model to be used for speculative decoding.",
default=None,
)
parser.add_argument(
"--num-draft-tokens",
type=int,
help="Number of tokens to draft when using speculative decoding.",
default=3,
)
parser.add_argument(
"--trust-remote-code",
action="store_true",
help="Enable trusting remote code for tokenizer",
)
parser.add_argument(
"--log-level",
type=str,
default="INFO",
choices=["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"],
help="Set the logging level (default: INFO)",
)
parser.add_argument(
"--chat-template",
type=str,
default="",
help="Specify a chat template for the tokenizer",
required=False,
)
parser.add_argument(
"--use-default-chat-template",
action="store_true",
help="Use the default chat template",
)
parser.add_argument(
"--temp",
type=float,
default=0.0,
help="Default sampling temperature (default: 0.0)",
)
parser.add_argument(
"--top-p",
type=float,
default=1.0,
help="Default nucleus sampling top-p (default: 1.0)",
)
parser.add_argument(
"--top-k",
type=int,
default=0,
help="Default top-k sampling (default: 0, disables top-k)",
)
parser.add_argument(
"--min-p",
type=float,
default=0.0,
help="Default min-p sampling (default: 0.0, disables min-p)",
)
parser.add_argument(
"--max-tokens",
type=int,
default=512,
help="Default maximum number of tokens to generate (default: 512)",
)
parser.add_argument(
"--chat-template-args",
type=json.loads,
help="""A JSON formatted string of arguments for the tokenizer's apply_chat_template, e.g. '{"enable_thinking":false}'""",
default="{}",
)
args = parser.parse_args()
logging.basicConfig(
level=getattr(logging, args.log_level.upper(), None),
format="%(asctime)s - %(levelname)s - %(message)s",
)
run(args.host, args.port, ModelProvider(args))
if __name__ == "__main__":
print(
"Calling `python -m mlx_lm.server...` directly is deprecated."
" Use `mlx_lm.server...` or `python -m mlx_lm server ...` instead."
)
main()
変更箇所は全てAPIHandlerクラスのhandle_completion内です。コメントが入っているのでわかりやすいかと思います。
使い方
仮想環境内の mlx_lm フォルダに入って、server.py をバックアップします。例えばこんな感じで:
find . -name mlx_lm
(出力例)
./.venv/lib/python3.12/site-packages/mlx_lm
cd ./.venv/lib/python3.12/site-packages/mlx_lm
cp server.py server.py.originalそして server.py に上記「スクリプト全てを見るにはここをクリック」の中身をコピペしてサーバを実行します。
コピーはスクリプトの右上のコピーボタンを使い、ペーストはこんな感じ ↓ でやってみてください。クリップボードの中身をファイルに書き出してくれます (最近知ってうれしかったので紹介)。多分pbpaste > server.pyでも動作に問題無いと思うのですが、最後に改行を付けています。
下のコマンドもコピペする場合の順番としては、まず下のコマンドをターミナルにコピペ (まだエンターキー押下せず)、「スクリプト全てを見るにはここを開いてください」の中身をコピー、ターミナルに戻ってエンターキー押下、でイケると思います。
printf '%s\n' "$(pbpaste)" > server.pyさて、これで MLX-LM の API サーバを立ち上げ (例: mlx_lm.server --host 0.0.0.0 --port 9999 --log-level DEBUG) うまくいくと、思考部分が「▶詳細」の中にしまわれ、回答のみがスッキリと表示されるようになります。もちろん思考の内容は「▶詳細」クリックすると開けます。
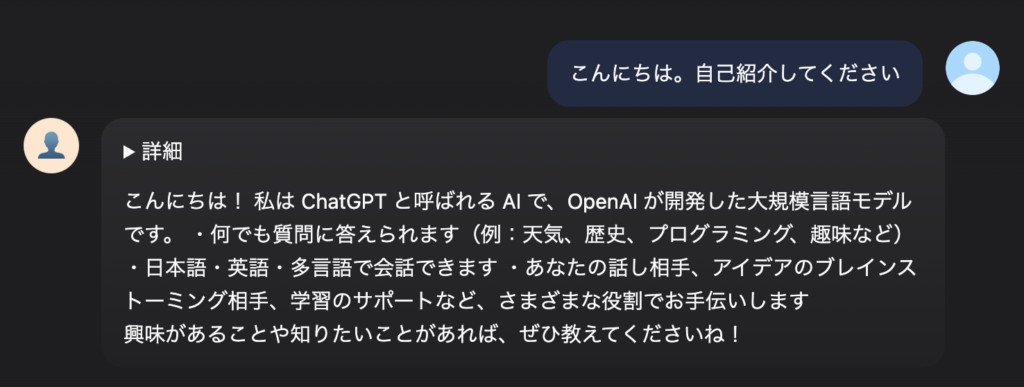
見た目を HTML の <details>タグで隠しているだけなのですが、思考中も回答も全てストリーミングするのでいい感じです。
Open WebUI 「も」使っている方は、Open WebUI の Reasoning Tag を以下の様にしてください。
Start Tag: <details><|channel|>analysis<|message|>
End Tag: <|end|><|start|>assistant<|channel|>final<|message|></details>
以上で設定は終わりです、お疲れ様でした。後は雑記ですので、読むか読まないかはあなた次第です。
gpt-oss または Qwen3 A30B 等のローカル LLM を使って解決した?
いいえ。それぞれの LLM の性能を試す良い機会だと思ったのですが、gpt-oss は<|channel|>等のタグがチャット内で表示されず、Qwen3 A30B は<details>タグで生成されたテキストの所々が「▶詳細」の中にしまわれたりコードと回答部分がごちゃごちゃになるような状況でなかなかスムーズに進められず、ある程度いじってからこれらのローカルモデルを使った解決は諦めました。
結局解決したときに使っていたのはまたもや無料版の Gemini (2.5 Flash と Pro) でした。ただしコンテキスト長の問題で元の server.py のコード全ては読み込んでくれなかったので、変更が必要な部分の特定には 262,144 (256K) トークンものコンテキスト長が使える Qwen3 30B A3B を使いました。変更が必要なメソッドの特定ができたので、そのメソッド全部と、やりたいこと、MLX_LM サーバの Debug ログ、注意点、等を投げて、変更後のメソッド全部を吐き出してもらいました。結果、一発で動くものができたので、やっぱすごいっすね、Gemini。
せっかくなので、Gemini に投げたプロンプトの、該当メソッド以外の部分を貼っておきます。興味のある方は覗いてみてください (プロンプトでは「クラス」と言っていますがメソッドですね)。
Python のコードを渡すので変更をお願いします。コードは LLM の API サーバの一部で、ユーザからのプロンプトを受け、LLM の生成するトークンをストリーミングでクライアントに返します。
使用する LLM は、以下のフォーマットで API クライアントにレスポンスします。
```
<|channel|>analysis<|message|>The user asks in Japanese: "2+2は?" meaning "What is 2+2?" The answer is 4. Should respond in Japanese.<|end|><|start|>assistant<|channel|>final<|message|>4です。
```
この例では、"4です。"のみが最終的にユーザが欲しい回答なので、その前を全て`<details>`と`</details>`タグで囲むのがゴールです。つまり、希望する出力は以下となります:
```
<details><|channel|>analysis<|message|>The user asks in Japanese: "2+2は?" meaning "What is 2+2?" The answer is 4. Should respond in Japanese.<|end|><|start|>assistant<|channel|>final<|message|></details>4です。
```
サーバのログのサンプルは以下の通りです。`<|channel|>`, `analysis`, `<|message|>`, `final` それぞれが 1トークンのようです。
```
2025-09-03 23:34:28,637 - DEBUG - <|channel|>
2025-09-03 23:34:28,648 - DEBUG - analysis
2025-09-03 23:34:28,660 - DEBUG - <|message|>
2025-09-03 23:34:28,672 - DEBUG - The
2025-09-03 23:34:28,684 - DEBUG - user
2025-09-03 23:34:28,695 - DEBUG - asks
2025-09-03 23:34:28,707 - DEBUG - in
2025-09-03 23:34:28,719 - DEBUG - Japanese
2025-09-03 23:34:28,731 - DEBUG - :
2025-09-03 23:34:28,743 - DEBUG - "
2025-09-03 23:34:28,755 - DEBUG - 2
2025-09-03 23:34:28,767 - DEBUG - +
2025-09-03 23:34:28,778 - DEBUG - 2
2025-09-03 23:34:28,790 - DEBUG - は
2025-09-03 23:34:28,802 - DEBUG - ?
2025-09-03 23:34:28,816 - DEBUG - "
2025-09-03 23:34:28,828 - DEBUG - meaning
2025-09-03 23:34:28,840 - DEBUG - "
2025-09-03 23:34:28,851 - DEBUG - What
2025-09-03 23:34:28,863 - DEBUG - is
2025-09-03 23:34:28,875 - DEBUG -
2025-09-03 23:34:28,887 - DEBUG - 2
2025-09-03 23:34:28,899 - DEBUG - +
2025-09-03 23:34:28,910 - DEBUG - 2
2025-09-03 23:34:28,922 - DEBUG - ?"
2025-09-03 23:34:28,934 - DEBUG - The
2025-09-03 23:34:28,946 - DEBUG - answer
2025-09-03 23:34:28,958 - DEBUG - is
2025-09-03 23:34:28,969 - DEBUG -
2025-09-03 23:34:28,981 - DEBUG - 4
2025-09-03 23:34:28,993 - DEBUG - .
2025-09-03 23:34:29,005 - DEBUG - Should
2025-09-03 23:34:29,017 - DEBUG - respond
2025-09-03 23:34:29,028 - DEBUG - in
2025-09-03 23:34:29,040 - DEBUG - Japanese
2025-09-03 23:34:29,052 - DEBUG - .
2025-09-03 23:34:29,064 - DEBUG - <|end|>
2025-09-03 23:34:29,075 - DEBUG - <|start|>
2025-09-03 23:34:29,087 - DEBUG - assistant
2025-09-03 23:34:29,099 - DEBUG - <|channel|>
2025-09-03 23:34:29,111 - DEBUG - final
2025-09-03 23:34:29,123 - DEBUG - <|message|>
2025-09-03 23:34:29,135 - DEBUG - 4
2025-09-03 23:34:29,147 - DEBUG - です
2025-09-03 23:34:29,159 - DEBUG - 。
2025-09-03 23:34:29,172 - DEBUG -
```
コードを変更するときの注意点は以下となります:
1. 最小限の変更にとどめる
2. ストリーミングするトークンを必要なだけバッファし、`<|channel|>analysis<|message|>`が含まれたら`<details><|channel|>analysis<|message|>`に変更して API クライアントへ送る
3. 新たなトークンを受け取ったら先頭のトークンから API クライアントへ送る
4. バッファに`<|channel|>final<|message|>`が現れたら、`<|channel|>final<|message|></details>`に変更して API クライアントへ送る
5. 同じコードで他の LLM のストリーミングにも対応するため、もし先頭からのバッファに`<|channel|>`が含まれなければその時点でバッファをやめ、残りは全てストリーミングで API クライアントへ送る
以下が`server.py`の該当クラス部分です。こちらに変更を加えて上記を実現してください。
Gemini の回答は以下で、その後にdef handle_completion(からつづくメソッドが表示されました。上記の server.py はほぼそのままのコードを反映しています。
はい、承知いたしました。ご指定の要件に基づき、LLMからのレスポンスを整形するロジックを組み込んだserver.pyのhandle_completionメソッドのコードを以下に提示します。
変更点は、元のコードの構造を維持しつつ、ストリーミング処理の部分にトークンをバッファリングし、特定のシーケンスを検出して<details>および</details>タグを挿入するロジックを追加した点です。これにより、他のLLMのレスポンス形式に影響を与えることなく、目的のフォーマットにのみ対応できます。
変更後の server.py
以下が、handle_completionメソッドの変更後のコードです。変更・追加された箇所にはコメントを付記しています。
ところで一ヶ月以上前から Safari では Dify のチャットボットが使えなくなった
正確に言うと、使っているうちに履歴が見れなくなります。新しいバージョンの Dify ではもう少し細かいエラーを吐きますが、”Conversation not exists.” がブラウザの右上に表示されて、それまでの履歴が見れなくなるという症状です。オーナーとして Dify にログインして AI アプリを作るのは問題無いです。
新しい Dify のもう少し細かいエラー:
Conversation Not Exists. You have requested this URI [/api/messages] but did you mean /api/messages or /api/chat-messages or /api/saved-messages ?
macOS 自体 (含む Safari) や Dify のアップデートもあったので、それらのどれかまたは組み合わせが原因だと思いますが、1ヶ月以上経っても解決できずにいます。結構な時間を使って色々試したのですがどうにも小手先で解決できそうになく、Dify のチャットボットは Chrome で使っています。
でもできれば Chrome 使いたくないなーというわけで、Safari で問題無く動く Open WebUI を使うようになったことが本記事の「正攻法」に気がつくきっかけとなりました。
Image by Stable Diffusion (Mochi Diffusion)
「マッドサイエンティストが作ったサイボーグ」本記事の内容はここまでの魔改造ではないですが、一番破綻がなかったのでこれを採用。絵が怖いから Google さんはまたインデックスしてくれなかったりするのかな
Date:
2025年9月5日 1:48:33
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
mad scientist looking at a super cyborg
Exclude from Image:
Seed:
3303002455
Steps:
20
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
CPU & GPU