

OpenAI の音声文字起こし AI である Whisper を試したところ、その性能の高さに非常に興奮しました。無料なうえローカルで完結し、M1 mac mini 16GB RAM なら音声ファイル自体の 90% 位の時間でかなり使える文字起こしをしてくれます。すごい時代です。で、精度を高める方法を調べていろいろ試したものの、やはり 100% にはなりません。だったら逆に、人間がテキストを簡単に修正ができるアプリがあれば良いだろうとの発想から、音声を聞きながら Whisper が書き出した文章を編集できるアプリ、その名も『字幕極楽丸』を Flet で作りました。今回はとりあえずアプリの紹介として、使い方やインストール方法を説明します。コードの内容に関しては別記事にするつもりですが、(適当な英語の) コメントを入れてあるので、気になる方は GitHub を覗いてみてください。
Contents
アプリの紹介
Whisper 等の文字起こし (speech-to-text) ツールで書き出した字幕ファイルを、音声ファイルと同期しながら再生し、必要に応じてテキストを編集できるというのがこのアプリです (と言っても、現状は 。←解決済み。また、いくつか既知の不具合もあるため、一応の完成型といういう状態で公開してます)。英名は全くひねらず『Speech + Subtitles Player』、略して SPSP (または、SPS Player)。和名は『字幕極楽丸』です。はい、ファミカセ『地獄極楽丸』インスパイアー系の命名となっています (名前だけ)。ま、どうでも良い話ですね。ロゴにはカッコイイフリーフォント (フロップデザインさんの、源界明朝) を使わせていただきました。ありがとうございます。flet build macos コマンドで実行ファイルとして書き出すと Numpy の読み込みができないためにクラッシュします
アプリの使い方
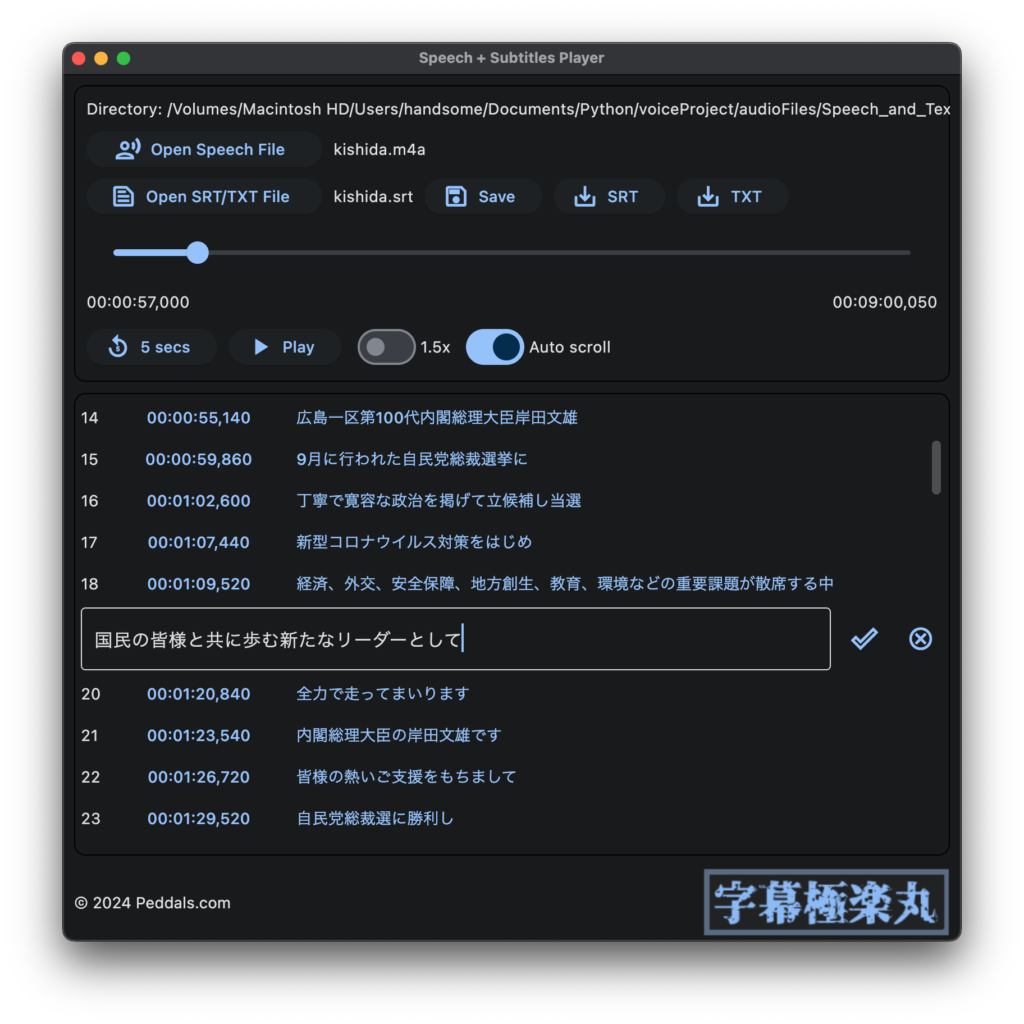
(実行方法は下記「アプリの実行方法」参照) Open Speech File ボタンで音声ファイルを読み込むと、同名の字幕ファイル (拡張子 .srt) もしくはテキスト (拡張子 .txt) が同じフォルダにあれば自動的に読み込み、タイムスタンプと字幕テキストを表示します。Play ボタンで音声を再生し、テキストは音声に合わせてスクロールします。タイムスタンプをクリックすると、そこへ頭出しします。テキスト部分をクリックすると修正が行えます。編集内容は Save ボタンで同一ファイルに上書きし、SRT と TXT ボタンはそれぞれ別ファイルとして書き出します。1.5x と Auto scroll のスイッチはそれぞれ、1.5 倍速再生、音声に合わせたテキストの自動スクロールをオン・オフできます (自動スクロールはタイムスタンプのある SRT 形式のみ可能)。現在既知の問題として、Open/Export as のボタンをクリックするとダイアログが開かず、アプリ全体が動作しなくなることが確認できています。編集を行っている際には頻繁に Save をクリックするようにしてください。
TXT で書き出した場合はタイムスタンプが含まれない文章のみのため、アプリ内でのオートスクロールができませんが、議事録やレポートなど本アプリ以外の様々な用途に利用できます。SRT は字幕フォーマットとしてよく使われる形式 (Wikipedia) で、音声の元データが映像であれば、DaVinci Resolve (フリーでも利用できる映像編集アプリ) 等で字幕データとして動画に取り込めます。
アプリの対象ユーザ/ユースケース
映像に字幕を埋め込みたい方が主な対象ユーザになると思います。また、Whisper 含め文字起こし AI の精度の検証を行うエンジニアや、コールセンタで通話内容をレポートにまとめるオペレータと言った方々には有用だと思います。他には、ミーティングの議事録を AI に出力させてから清書をするとか、外国語の学習にも便利に使ってもらえるでしょう (精度の違いを無視すれば、Whisper ではかなりの数の言語がサポートされています: Supported languages)。
アプリの実行方法
アプリアプリ言ってますが、現状ダブルクリックで開くアプリケーションとして書き出せないため、下記方法でコマンドラインからの実行が推奨です。無事アプリにビルドできたので、別記事にしました。テストおよびビルドは macOS のみで行っています。大きな違いは無いはずですが、Windows や Linux の方は、すみませんがよしなにお願いします。コードは GitHub に置いてあります。
https://github.com/tokyohandsome/Speech-plus-Subtitles-Player
コードをクローンし、Python の仮想環境を作り、Flet と Numpy をインストール
Python は 3.8 以降であれば大丈夫のハズです (制作環境の Python は 3.11.7)。以下例では仮想環境の作成に pipenv を使用していますが、何でもかまいません。
git clone https://github.com/tokyohandsome/Speech-plus-Subtitles-Player.git
cd Speech-plus-Subtitles-Player
pipenv --python 3.11
pipenv shell
pip install flet
pip install numpyアプリを実行
環境ができたら、以下コマンドで字幕極楽丸を実行できます。ダブルクリックで開くアプリをビルドする方法は別記事にしました。
python main.py音声ファイルを選択
起動後、Open Speech File ボタンをクリックして、MP3 や WAV 等の音声ファイルを選択します。macOS では初回に書類フォルダへのアクセス権を与えるか聞かれると思いますので、許可してあげてください。音声ファイルと同じフォルダに、同じファイル名で拡張子が .srt (もしくは .txt) となっているファイルがあると、自動的に読み込まれます (スクショで言うところの、kishida.m4a を開くと kishida.srt も読み込まれる)。音声ファイルを読み込んだ後ならば、手動で字幕ファイルを読み込むこともできます。
既知の不具合
クリティカルな問題は無いと思いますが、心配な方は SRT や TXT のバックアップを別の場所に保存した上でご利用ください。
- 字幕のボタンが多くなると、ウィンドウの移動やリサイズの際にカクつきます
flet build macos --include-packages flet_audio等としてアプリケーションとして書き出しても、実行時にクラッシュします (Flet version == 0.21.2)。オートスクロールが不要であれば、import numpy as npをコメントしてもらえれば、書き出した実行ファイルも動きます- Open や Export のボタンをクリックすると、ダイアログが開かず、アプリを閉じる以外できなくなることがあります (原因調査中)。セーブは頻繁に行ってください
- macOS で再生できる MP3 のサンプルレートは 44.1KHz までのようです。それより高いサンプルレートの場合は Audacity 等で変換してください
- SRT は本来、字幕部分が複数行あっても良いみたいですが、本アプリでは 2行以上あることを想定していません。Whisper で書き出した SRT ファイルは問題無いはずです
おまけ
細かいことは書きませんが、Youtube 等のオンライン動画を音声ファイルとしてダウンロードする方法と、Apple が Apple Sillicon 用に最適化した Whisper で音声ファイルを SRT に書き出す方法を貼っておきます。
オンラインの動画を m4a 音声ファイルとしてダウンロード
pip install yt_dlp
python -m yt_dlp -f 140 "動画ページのリンク"Whisper で音声ファイルを SRT に書き出す (文字起こしする) Python スクリプト
macOS であれば、MLX 版 Whisper が動く環境を作り、Hugging Face から whisper-large-v3-mlx (json と npz) をダウンロードして mlx_models フォルダに展開します。その後、mlx-examples/whisper フォルダに以下のファイル speech2srt.py を作ります。5-6行目のフォルダ名とファイル名はそれぞれ書き換えてください。日本語以外の場合は、音声の言語に合わせて language='ja', の部分を変更してください (日本語の音声を ‘en’ で指定すると英語訳した字幕が書き出され、英語音声を ‘ja’ 指定すると日本語訳されたものが書き出されます。が、残念ながら翻訳の精度は非常に低いのでやめた方が良いでしょう)。
import whisper
import time
import os
base_dir = "音声ファイルのあるフォルダ名"
speech_file_name = "読み込みたい音声ファイル名"
start_time = time.time()
speech_file = base_dir + speech_file_name
model = "mlx_models/whisper-large-v3-mlx"
result = whisper.transcribe(
speech_file,
language='ja',
#language='en',
path_or_hf_repo=model,
verbose=True,
#fp16=True,
word_timestamps=True,
condition_on_previous_text=False,
#response_format='srt',
append_punctuations="\"'.。,,!!??::”)]}、",
#append_punctuations="。!?、",
#initial_prompt='です。ます。した。',
temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
)
end_time = time.time()
elapsed_time = round(end_time - start_time, 1)
print('############################')
print(f"処理にかかった時間: {elapsed_time}秒")
print('############################')
def ms_to_srt_time(milliseconds):
seconds = int(milliseconds / 1000)
h = seconds // 3600
m = (seconds - h * 3600) // 60
s = seconds - h * 3600 - m * 60
n = round(milliseconds % 1000)
return f"{h:02}:{m:02}:{s:02},{n:03}"
subs = []
sub = []
for i in range(len(result["segments"])):
start_time = ms_to_srt_time(result["segments"][i]["start"]*1000)
end_time = ms_to_srt_time(result["segments"][i]["end"]*1000)
text = result["segments"][i]["text"]
sub = [str(i+1), start_time+' --> '+end_time, text+'\n']
subs.append(sub)
text_file = base_dir + os.path.splitext(os.path.basename(speech_file_name))[0] + ".srt"
# Overwrites file if exists.
with open(text_file, 'w') as txt:
for i in subs:
for j in range(len(i)):
txt.write('%s\n' % i[j])後は Python で実行すれば、音声ファイルと同じフォルダに SRT ファイルが作られます。同名ファイルがあると上書きするので注意してください。
python speech2srt.pyWhisper は GPU で動きます。参考まで、Mac Studio (M2 Max 30 コア GPU) だと、大体音声の長さの 1/6 位で書き出しが完了します。
Image by Stable Diffusion
文字起こしをするために音声に集中している女性達それぞれの表情の違いが良いですね。指が怖いですが、ステップ数をいじってもこれ以上良いバランスの絵は生成できませんでした。
Date:
2024年3月24日 23:45:42
Model:
realisticVision-v20_split-einsum
Size:
512 x 512
Include in Image:
realistic, masterpiece, best quality, retro future, office ladies transcribing audio from record player
Exclude from Image:
Seed:
2389164678
Steps:
20
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
CPU & Neural Engine