This article is mainly for Mac users. The mice in question are average or budget models that cost around $10~$40. The issue I was able to resolve pertains to USB dongle types.
Note: This is not about “how to reverse the direction of the mouse wheel rotation and the scroll direction on a Mac.” That setting can be easily found.
This article explains how to resolve an issue where the scroll direction momentarily reverses while using the mouse. Specifically, it addresses the problem where, after stopping the scroll and trying to scroll in the same direction again after a short pause, the scroll momentarily reverses, causing you to lose where you’re looking at. If this method does not solve your issue, please try other solutions available on the numerous other websites.
Resolution
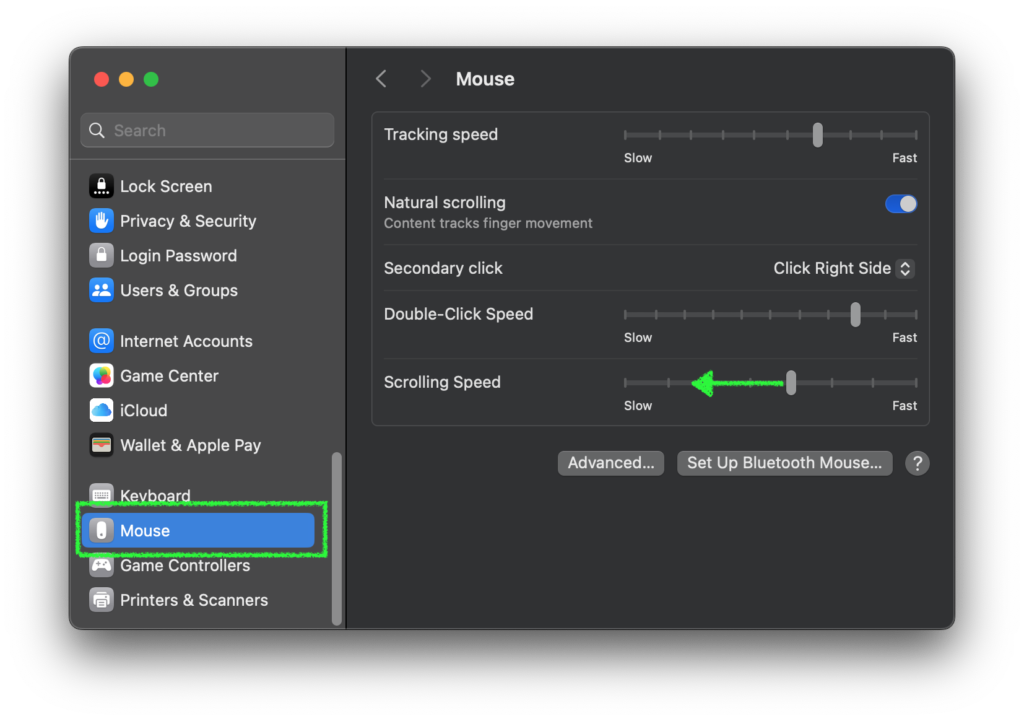
In the Mouse settings of System Settings under the Apple menu, lower the Scrolling Speed by about two notches. The optimal setting may vary, so adjust it to see what works best for you. This should resolve the issue mentioned above. I think you might not even notice a significant decrease in scroll speed even if you lower it by three or four notches. Nonetheless, this should solve the problem.
Why This Works – Here’s My Guess
If you’ve ever taken apart a mouse after hearing advice like “clean the wheel every few months,” you might know that most mouse wheels have many fine grooves on the inside. Light or laser is emitted from one side and detected by a sensor on the other side to read the wheel’s rotation. With cheaper mice, when Mac increases the sensitivity (or scroll speed), the mouse may not be able to keep up with the reading speed required, resulting in an incorrect detection of reverse rotation. By slowing down the scroll speed, you allow the Mac to read the wheel’s movements more accurately and consistently, which should result in the correct behavior. That’s my guess, anyway.
Test Results and the Mouse I’m Using
In my case, I use the same mouse with Windows for work and Mac for personal use and have never experienced this issue on Windows. This led me to rule out issues such as dirt, hardware malfunction, or battery depletion.
One day, I recalled that old Mac OS had a higher resolution/read frequency than Windows for sensitive controls of mice even with balls inside decades ago. Based on this, I tried lowering the scrolling speed, and voila! It worked! Since making this change, the issue has barely occurred at all. None of web pages Google suggested had this information, so I hope this article will help you mitigate the annoying mouse wheel issue.
For reference, the mouse I am using is a Logitech M220 (laser, silent type, comes with a USB dongle) which costs only about $10. I really like the appropriate resistance of the wheel and the ease of clicking, so it’s great that this solution worked.
Image by Stable Diffusion (Mochi Diffusion)
For the top image, when I tried to create an illustration of the mouse hero defeating a mad scientist, I ended up with only fake images resembling famous mice characters. Since none of those looked fine to use, I ultimately went with a strange character that no one would complain about.
Date: 2024-10-18 0:29:23
Model: realisticVision-v51VAE_original_768x512_cn
Size: 768 x 512
Include in Image: comicbook cover, the super hero mouse-man versus a mad doctor
Recently, the performance of open-source and open-weight LLMs has been amazing, and for coding assistance, DeepSeek Coder V2 Lite Instruct (16B) is sufficient, while for Japanese and English chat or translation, Llama 3.1 Instruct (8B) is enough. When running Ollama from the Terminal app and chatting, the generated text and response speed are truly surprising, making it feel like you can live without the internet for a while.
However, when using the same model through Dify or Visual Studio Code’s LLM extension Continue, you may notice the response speed becomes extremely slow. In this post, I will introduce a solution to this problem. Your problem may be caused by something else, but since it is easy to check and fix, I recommend checking the Conclusion section of this post.
Mac with 32GB RAM is capable of running them on memory.
Conclusion
Check the context length and lower it.
By setting “Size of context window” in Dify or Continue to a sufficiently small value, you can solve this problem. Don’t set a number just because the model supports it or for future use; instead, use the default value (2048) or 4096 and test chatting with a small number of words. If you get a response as you expect, congrats, the issue is resolved.
Context size: It is also called "context window" or "context length." It represents the total number of tokens that an LLM can process in one interaction. Token count is approximately equal to word count in English and other supported languages. In the table above, Llama 3.1 has a context size of 131072, so it can handle approximately 65,536 words text as input and output.
Changing Context Length
Dify
Open the LLM block in the studio app and click on the model name to access detailed settings.
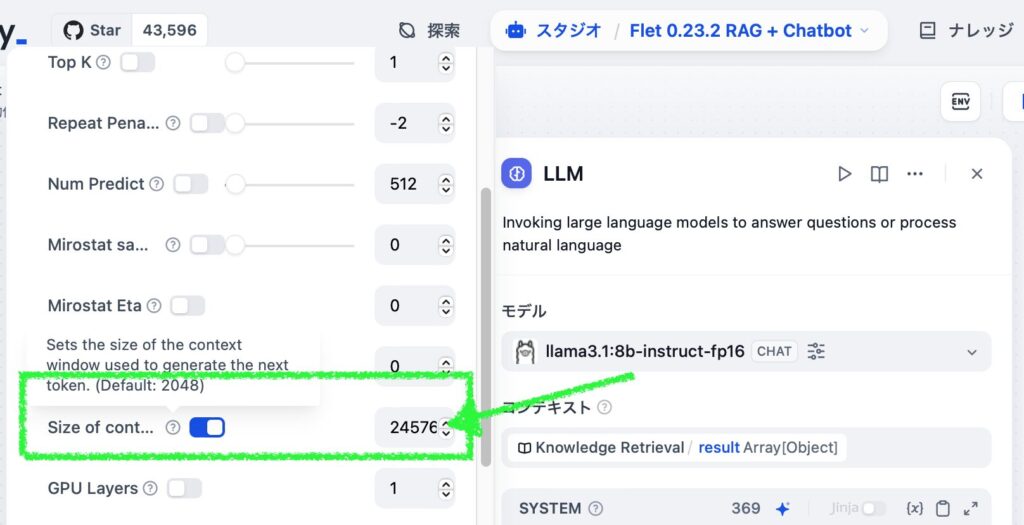
Scroll down to find “Size of cont…” (Size of content window) and uncheck it or enter 4096.
The default value is 2048 when unchecked.
Continue (VS Code LLM extension)
Open the config.json file in the Continue pane’s gear icon.
Change the contextLength and maxTokens values to 4096 and 2048, respectively. Note that maxTokens is the maximum number of tokens generated by the LLM, so we set it half.
The easiest way is to use the Ollama’s command ollama show <modelname> to display the context length. Example:
% ollama show llama3.1:8b-instruct-fp16
Model
arch llama
parameters 8.0B
quantization F16
context length 131072
embedding length 4096
Parameters
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024
Context Length in App Settings
Dify > Model Provider > Ollama
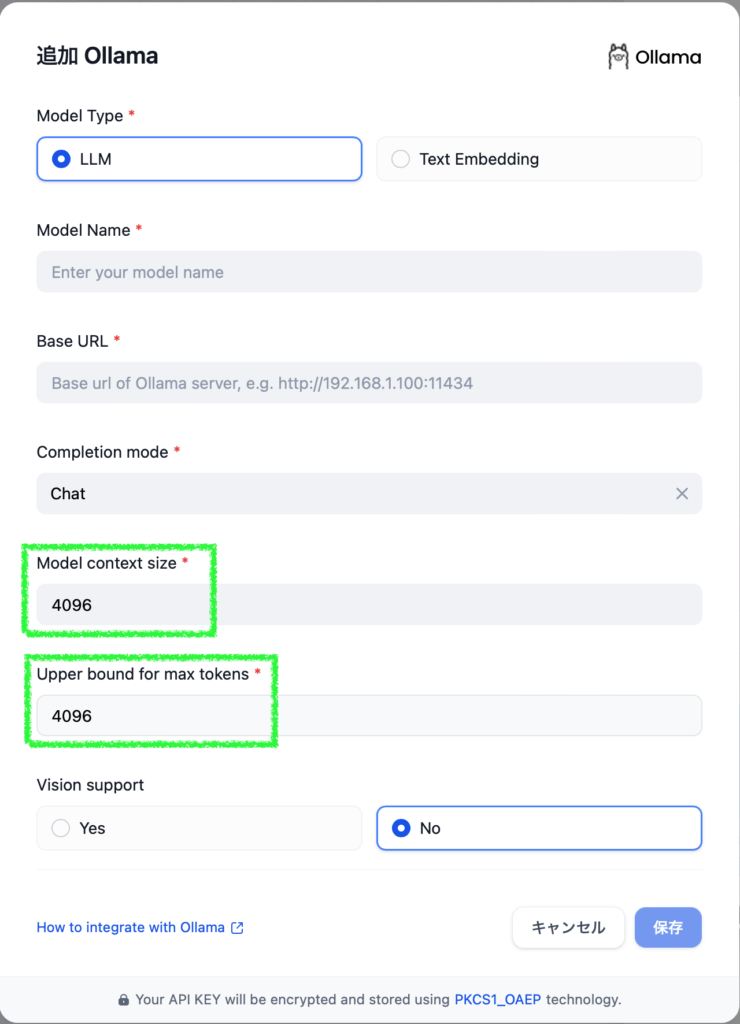
When adding an Ollama model to Dify, you can override the default value of 4096 for Model context length and Upper bound for max tokens. Since setting a upper limit may make debugging difficult if issues arise, it’s better to set both values to the model’s context length and adjust the Size of content window in individual AI apps.
Continue > “models”
In the “models” section of the config.json, you can add multiple settings for different context length by including a description like “Fastest Max Size” or “4096“. For example, I set the title to “Chat: llama3.1:8b-instruct-fp16 (Fastest Max Size)” and changed the contextLength value to 24576 and maxTokens value to 12288. This combination was the highest that I confirmed working perfectly on my Mac with 32 GB RAM.
What’s happening when LLM processing is slow (based on what I see)
When using ollama run, LLM runs quickly, but when using Ollama through Dify or Continue, it becomes slow due to large size of context length. Let’s check the process with ollama ps. Below are examples – first one had the max context length 131072 and the second one had 24576:
% ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b-instruct-fp16 a8f4d8643bb2 49 GB 54%/46% CPU/GPU 59 minutes from now
% ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b-instruct-fp16 a8f4d8643bb2 17 GB 100% GPU 4 minutes from now
In the slow case, SIZE is much larger than the actual model size (16 GB), and processing occurs on CPU at 54% and GPU at 46%. It seems that Ollama processes LLM as a larger size model when a large size context length is passed via API regardless of the actual number of tokens being processed. This is only my assumption, but the above tells.
Finding a suitable size of context length
After understanding the situation, let’s take countermeasures. If you can live with 4096 tokens, it’s fine, but I want to process as many tokens as possible. Unfortunately, I couldn’t find Ollama’s specifications, so I tried adjusting the context length by hand and found that a value of 24576 (4096*6) works for Llama 3.1 8B F16 and DeepSeek-Coder-V2-Lite-Instruct Q6_K.
Note that using non-multiple-of-4096 values may cause character corruption, so be careful. Also, when using Dify, the SIZE value will be smaller than in Continue.
Ollama, I’m sorry (you can skip this)
I thought Ollama’s server processing was malfunctioning because LLM ran quickly when running on CLI but became slow when used through API. However, after trying an advice “Try setting context length to 4096” from an issue discussion about Windows + GPU, I found that it actually solved the problem.
Ollama, I’m sorry for doubting you!
Image by Stable Diffusion (Mochi Diffusion)
This time I wanted an image of a small bike overtaking a luxurious van or camper, but it wasn’t as easy as I thought somehow. Most of generated images had two bikes, a bike and a van on reversing lanes, a van cut off of the sight, etc. Only this one had a bike leading a van.
Date: 2024-9-1 2:57:00
Model: realisticVision-v51VAE_original_768x512_cn
Size: 768 x 512
Include in Image: A high-speed motorcycle overtaking a luxurious van
Not sure when it started, but Finder didn’t open ~/Documents and its subfolders directly. Somehow I managed to get it fixed. If you have the same issue, it can be fixed.
Decided to troubleshoot (finally).
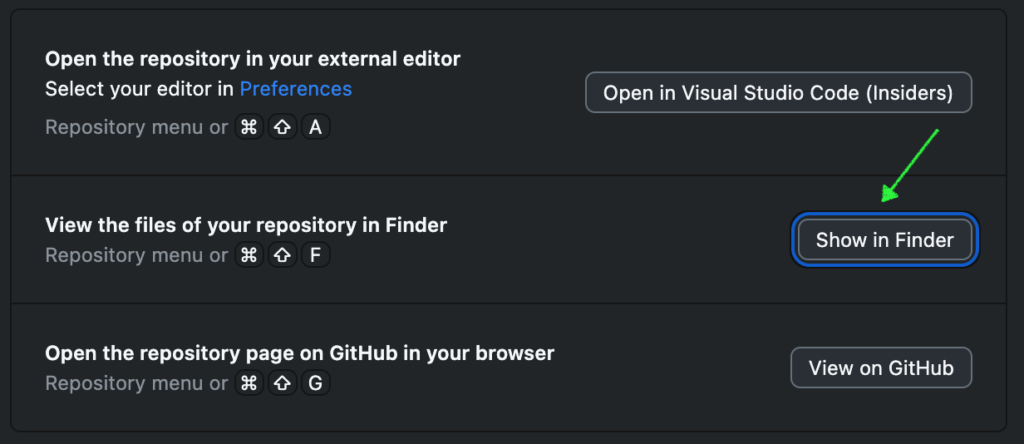
Current running macOS version is Sonoma 14.2.1. I might have first noticed this issue when the macOS version was Big Sur 11.0 — Finder didn’t open folder by executing open ~/Documents/Python/fuga in Terminal.app, but it was not a big deal at that time. Today, I was playing with GitHub Desktop app and once again noticed the issue — the Show in Finder button didn’t open the local repo but my home directory instead. Something was (still) wrong.
↑ this button opened the home directory ↓ instead of the local repo folder (my UI is Japanese.)Local repo located a couple folders under the Documents folder
Symptom
Open command in Terminal didn’t open any folder under ~/Documents in Finder. I was able to navigate to lower levels folders in the same Finder window, so I had the right permissions. Subfolders in ~/Music, ~/Downloads, etc. had no problem to be opend. Go menu > Recent Folders and right-click > Open in New Tab resulted the exact same issue. Only Documents and its subfolders didn’t open directly in Finder in any way.
How I fixed it.
I tried multiple things for a couple hours and nothing helped. Finally, changing the folder view to List from Column seemed to have worked. Little more details follow: Open the Documents folder in Finder then select List from the View icon or drop-down.
or List from drop-down
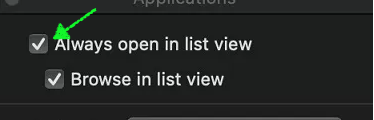
From the window’s action menu or Finder’s View menu, select Show View Options to open the settings window. Command + J shortcut does the same thing.
Check “Always open in list view” then click on “Use as Defaults” at the bottom and close the window. Now the Documents and its subfolders open in the list view directly by the open command in Terminal.
I won.
Finder still changes view of window somehow whether you like it or not. So, I moved around/opened new windows/changed views/closed windows several times to reproduce the issue, but it never happened again (so far). I don’t know if the above steps was the right way, but the issue is gone.
Things that I tried but didn’t work/help, just for your info.
Search in the internet — could not find the exact same issue.
Recently I started working on some small Python GUI programs. Last year on an Intel Mac I found tkinter was not good as it had some issues with Japanese input method so I gave up. It’s been more than a year and I have a M1 (arm) Mac so there might be some improvements with tkinter. Upgrading Python3 (and all programs) by brew was the first step I tried, then tkinter module was unable to be loaded any longer…
You always better read install log which gives you necessary info.
I didn’t really pay attention to the brew log when upgraded Python from 3.9.1 to 3.9.6 as it was successful and must be a minor update… Soon after the upgrade my Python scripts that import tkinter in a pipenv shell started giving me error “No module named '_tkinter'“. Lots of trials and errors referring to several web pages, tech threads, etc. didn’t help. Tried setting up pipenv from scratch, installed tcl-tk by brew, added PATH and some other tcl-tk variables to .zshrc to no avail. I finally decided to give up and went to bed – worst case scenario I need to uninstall and install all Python related things including brew… On the day-2, I was calmer than last night and started identifying the scope of the problem – ok, tkinter cannot be found even out of my pipenv. It’s really gone from macOS Big Sur at some point. Reviewed steps taken on the day-1 and it didn’t take much time to find the below:
% brew info python3
[email protected]: stable 3.9.6 (bottled)
Interpreted, interactive, object-oriented programming language
https://www.python.org/
...snip...
tkinter is no longer included with this formula, but it is available separately:
brew install [email protected]
...snip...
Aha! If I read the brew install log once completed, I didn’t need to waste 6 hours and would have a sweet dream. Anyways, if your tkinter is gone after upgrading Python by brew, just execute another command brew install [email protected] and install it as well. My scripts finally open tkinter GUI windows with no error.
Most of Python documents or webpages suggest you to try tkinter for GUI development as it’s installed by default, but it’s not true anymore especially for those of you who install Python by brew on Mac.
Example of the error in my case
% python3 -m tkinter
Traceback (most recent call last):
File "/opt/homebrew/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 188, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/homebrew/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 147, in _get_module_details
return _get_module_details(pkg_main_name, error)
File "/opt/homebrew/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 111, in _get_module_details
__import__(pkg_name)
File "/opt/homebrew/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/tkinter/__init__.py", line 37, in
import _tkinter # If this fails your Python may not be configured for Tk
ModuleNotFoundError: No module named '_tkinter'