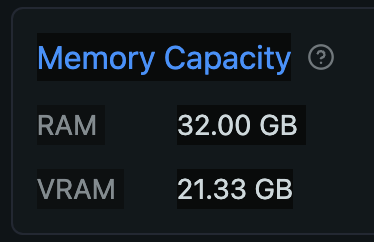
As of January 2025, there are settings for acceleration and VRAM optimization available for trial use in Ollama. It seems that both may become standard settings soon, but since the latest version 0.5.7 at the time of writing requires users to set them up themselves, I will share how to do so.
For those using local LLMs on Apple Silicon Mac (M series CPU), please also check out the previous article. It introduces how to allocate memory to the Mac’s GPU.
Environment
This is a setting for Ollama, so it should not depend on the OS, but I only touched on how to do this on macOS. Also, there seem to be ways to install it by building from source code, using brew, or running with Docker, but I don’t know how to set it up without using the app, so please look into that. Sorry.
- macOS: Sequoia 15.1.1
- Ollama: 0.5.7 (Ollama.app downloadable at the official website.)
Official sources of information
Ollama FAQ:
- How can I enable Flash Attention? (Flash Attention environment variable)
- How can I set the quantization type for the K/V cache? (K/V cache environment variable and notes)
The blog of the contributor who introduced K/V caching features to Ollama:
- Bringing K/V Context Quantisation to Ollama (Technical details. Very interesting.)
Fine-tuning (2) Reduce VRAM Usage and Increase Speed with Flash Attention
The method I wrote in my previous blog post above was (1), so here I will start from (2).
First, enable Flash Attention in Ollama. Flash Attention helps reduce VRAM usage and also increases the computation speed of LLMs. As it has been explained in various documents, there don’t seem to be any negative impacts from enabling this feature. While some claim that it triples the speed, even if it doesn’t quite do that, there’s no reason not to enable it if all effects are positive. It seems likely that Ollama will default to having this enabled in the future, but for now, you need to enable it yourself. If you’re using a Mac, run the following command in Terminal:
launchctl setenv OLLAMA_FLASH_ATTENTION 1To disable (revert), set the above value from 1 to 0. To check the current settings, run the getenv command. Below is an example of its execution when it is enabled, returning a 1.
% launchctl getenv OLLAMA_FLASH_ATTENTION
1
Fine-tuning (3) Reduce VRAM Usage by K/V Cache Quantization
K/V cache quantization seems to be a technique that improves computational efficiency by quantizing the context cache and reducing the required memory. It is also referred to as K/V context cache quantization at times. While fine-tuning (1) increased VRAM for loading LLMs to handle larger models or longer contexts, K/V cache achieves similar results by reducing the amount of memory used during model execution. While 8-bit quantization of the model itself causes only minor performance degradation and improves speed, it is expected that K/V cache quantization will have a similar effect on context cache size. When 8-bit quantization is applied to the K/V cache, the required memory amount becomes about half of what it would be without quantization, allowing for doubling the usable context length.
This feature is currently marked as Experimental in Ollama, and there is a possibility that performance may degrade when using embedding models, vision-multimodal models, or high-attention-head type models. Therefore, it seems that Ollama automatically disables this setting when an Embed model is detected. So, understanding that compatibility issues with the model could be a problem, you should try it out and if performance decreases, disable it. Unfortunately, there is no way to enable or disable this for each model at present.
Here are the settings: When it comes to quantization options, you can choose between 8-bit (q8_0) and 4-bit (q4_0), though by default there is no quantization (f16). If you opt for 4-bit, while memory reduction will be significant, performance will also decrease. Therefore, unless it’s a case where you need to use models that previously couldn’t run on GPU alone, choose 8-bit. Additionally, enabling Flash Attention is necessary as a prerequisite; please proceed after executing the fine-tuning (2) mentioned above. The command for Mac (in the case of 8-bit) would be as follows:
launchctl setenv OLLAMA_KV_CACHE_TYPE "q8_0"To reset to default, specify “f16” as the value. To check the current setting, run the getenv command. Example:
% launchctl getenv OLLAMA_KV_CACHE_TYPE
q8_0
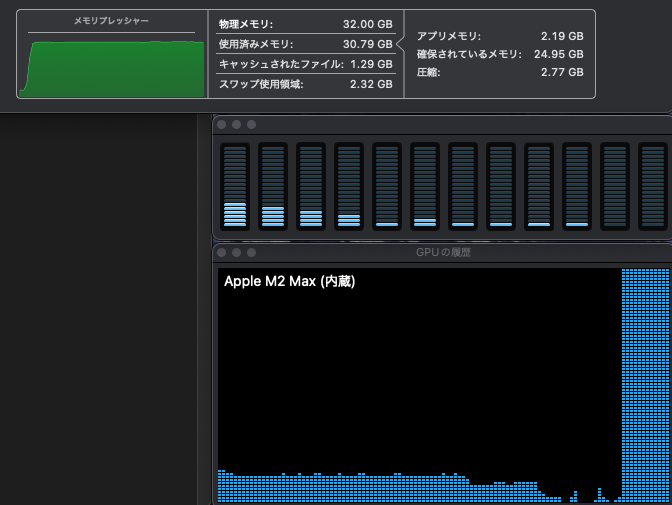
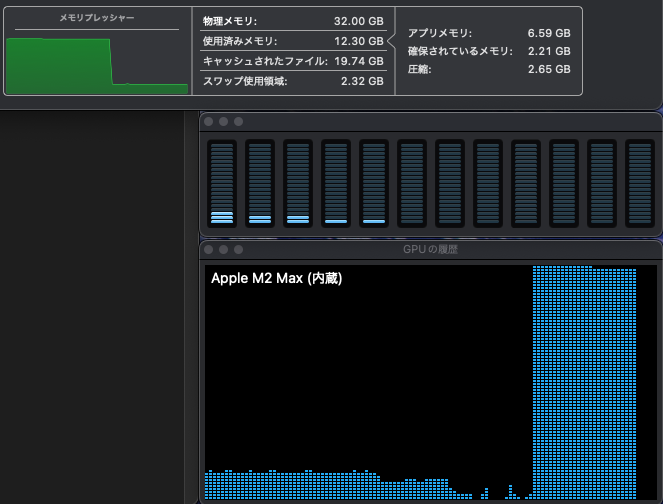
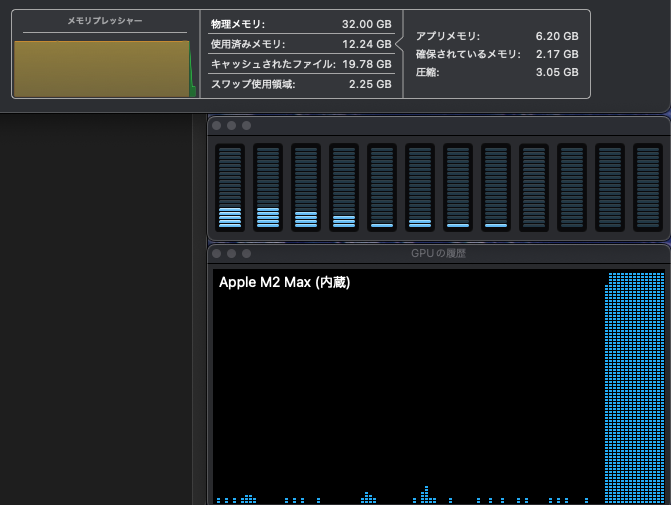
After setting up, you can run the model in Ollama and check the logs to see the quantization and cache size. In the following example, it is default f16 until halfway, and after the change, it becomes q8_0, showing that the overall size has decreased.
(Feb 16, 2025: corrected command.)
% grep "KV self size" ~/.ollama/logs/server2.log|tail
llama_new_context_with_model: KV self size = 1792.00 MiB, K (f16): 896.00 MiB, V (f16): 896.00 MiB
llama_new_context_with_model: KV self size = 1536.00 MiB, K (f16): 768.00 MiB, V (f16): 768.00 MiB
llama_new_context_with_model: KV self size = 512.00 MiB, K (f16): 256.00 MiB, V (f16): 256.00 MiB
llama_new_context_with_model: KV self size = 1792.00 MiB, K (f16): 896.00 MiB, V (f16): 896.00 MiB
llama_new_context_with_model: KV self size = 1792.00 MiB, K (f16): 896.00 MiB, V (f16): 896.00 MiB
llama_new_context_with_model: KV self size = 952.00 MiB, K (q8_0): 476.00 MiB, V (q8_0): 476.00 MiB
llama_new_context_with_model: KV self size = 952.00 MiB, K (q8_0): 476.00 MiB, V (q8_0): 476.00 MiB
llama_new_context_with_model: KV self size = 680.00 MiB, K (q8_0): 340.00 MiB, V (q8_0): 340.00 MiB
llama_new_context_with_model: KV self size = 816.00 MiB, K (q8_0): 408.00 MiB, V (q8_0): 408.00 MiB
llama_new_context_with_model: KV self size = 1224.00 MiB, K (q8_0): 612.00 MiB, V (q8_0): 612.00 MiBSet Variables Permanently
With the above two setup methods, the settings will be initialized after restarting the Mac. Below, I introduce a method to create a script that sets the environment variables and can be launched when you log in.
1. Launch Script Editor in Applications > Utilities.
2. Command + N to open a new window and copy-paste the below script. It simply sets environment variables then launch Ollama.
do shell script "launchctl setenv OLLAMA_HOST "0.0.0.0""
do shell script "launchctl setenv OLLAMA_FLASH_ATTENTION 1"
do shell script "launchctl setenv OLLAMA_KV_CACHE_TYPE "q8_0""
tell application "Ollama" to run3. File menu > Export As > set like below and Save:
- Export As: LaunchOllama.app
- Where: Application
- File Format: Application
4. Apple menu > Settings > General > Login items
5. If you already have Ollama.app, click on [ – ] button to remove it.
6. Click on [ + ] and select the app LaunchOllama.app you just created in the step #3.
7. Reboot your Mac, login, navigate to http://localhost:11434 and run command such as launchctl getenv OLLAMA_FLASH_ATTENTION to see 1 is returned.
Super Helpful Tool – Interactive VRAM Estimator
In the K/V cache feature contributor’s blog introduced earlier, there is a super useful tool called Interactive VRAM Estimator. You can find if a model you want to use will fit in your VRAM with this tool. A combination of the parameter size of the model, the context length, and the quantization level, it estimates the total size in VRAM per K/V Cache quantization level.
For example, in the case of DeepSeek-R1:32B_Q4_K_M, you would choose 32B and Q4_K_M. If you have set up the K/V cache for Q8_0 this time, while looking at the Total of the green bar, select the Context Size to estimate the VRAM size required to run with the combination.
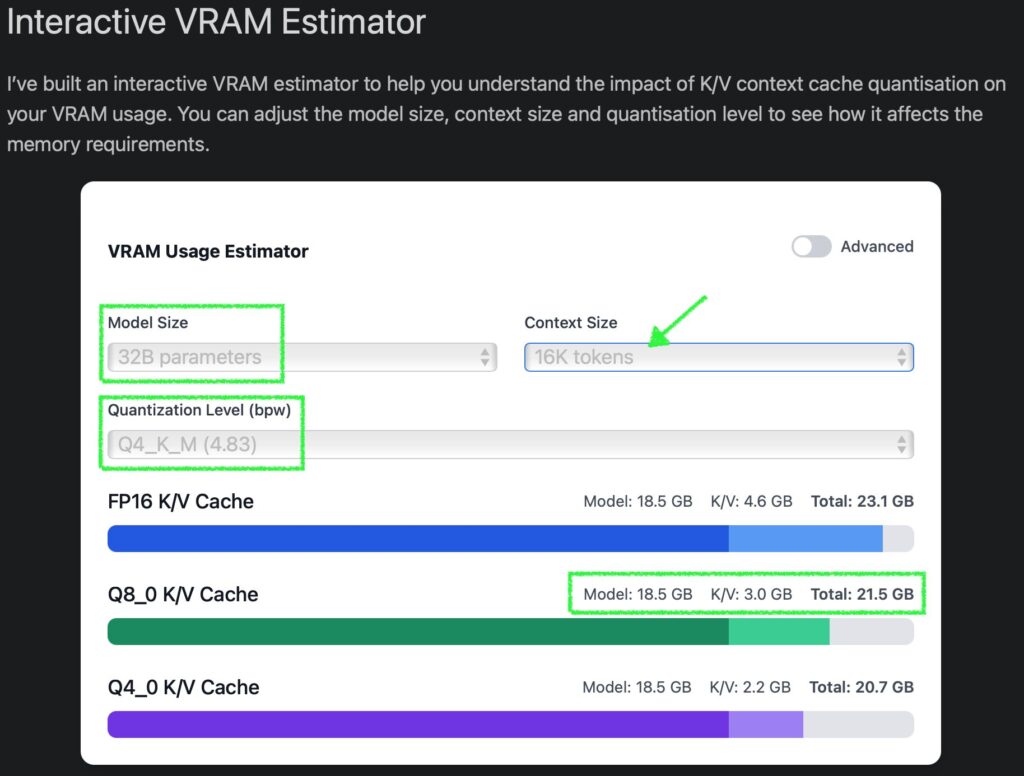
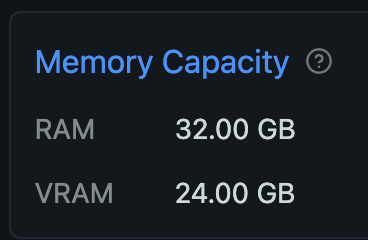
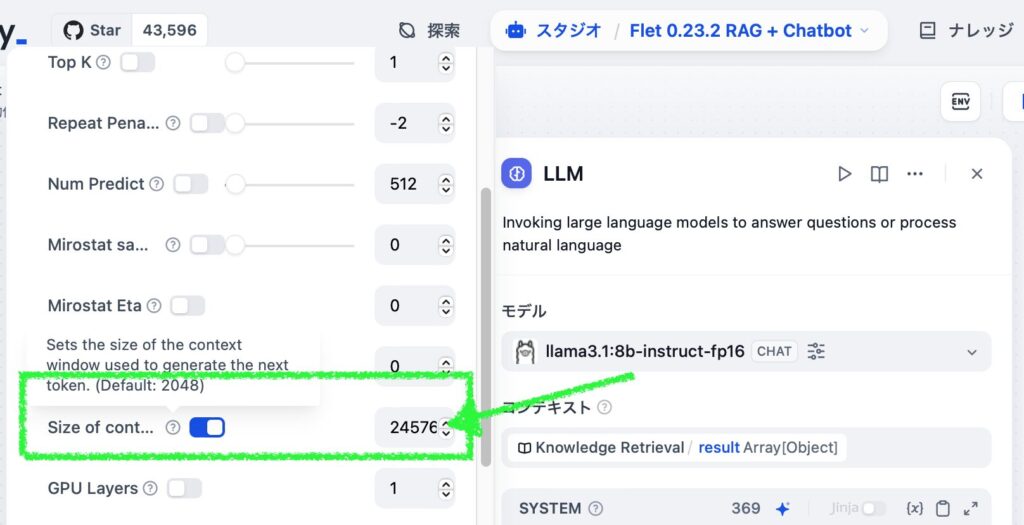
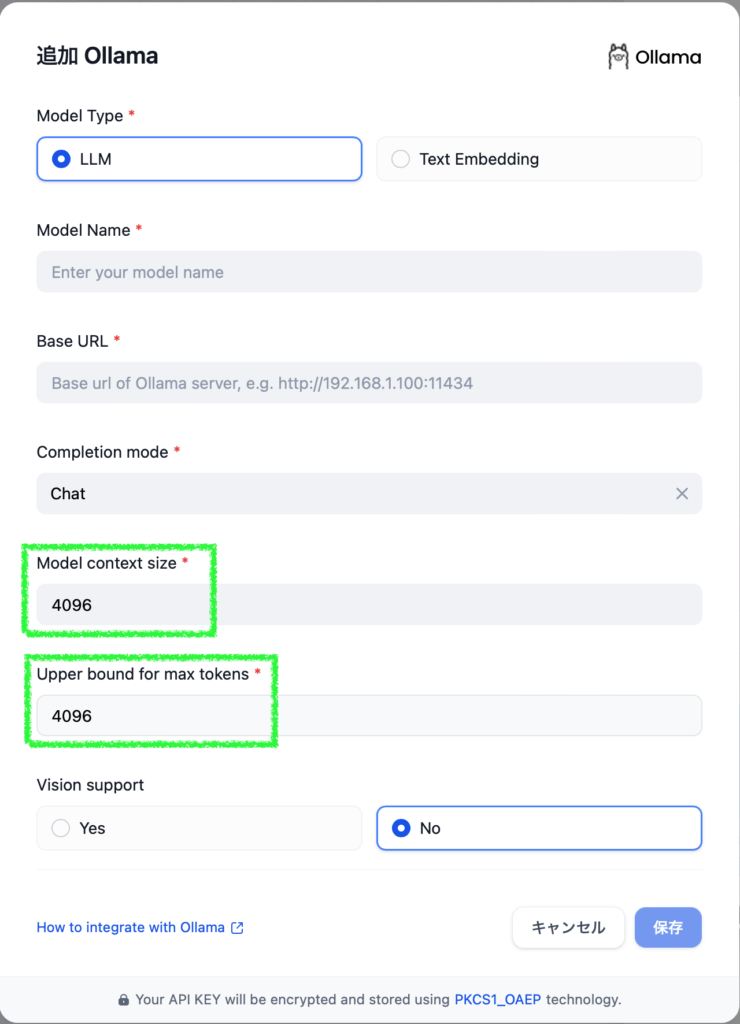
With 32K (= 32768) tokens見込み, it exceeds my Mac’s VRAM of 24GB, so I’ll enable the Advanced mode in the top right to come up with a more aggressive number. By tweaking the Context Size slider while keeping an eye on the Total of Q8_0, it seems that 24K (24 * 1024=24576) fits within 23GB RAM. Awesome, huh?
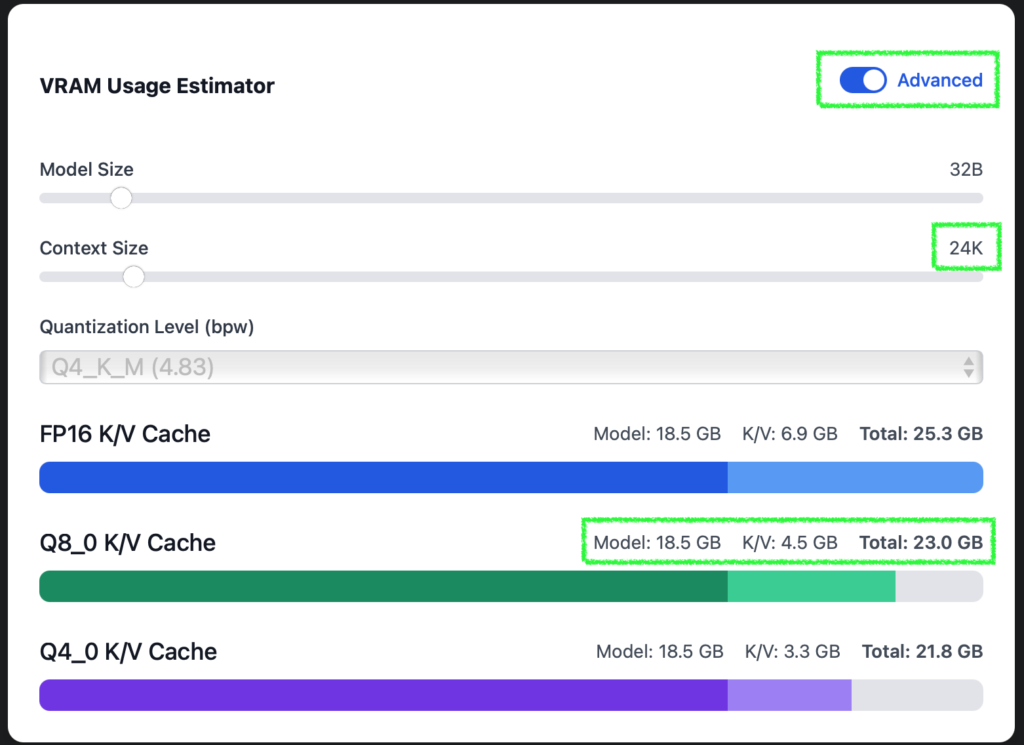
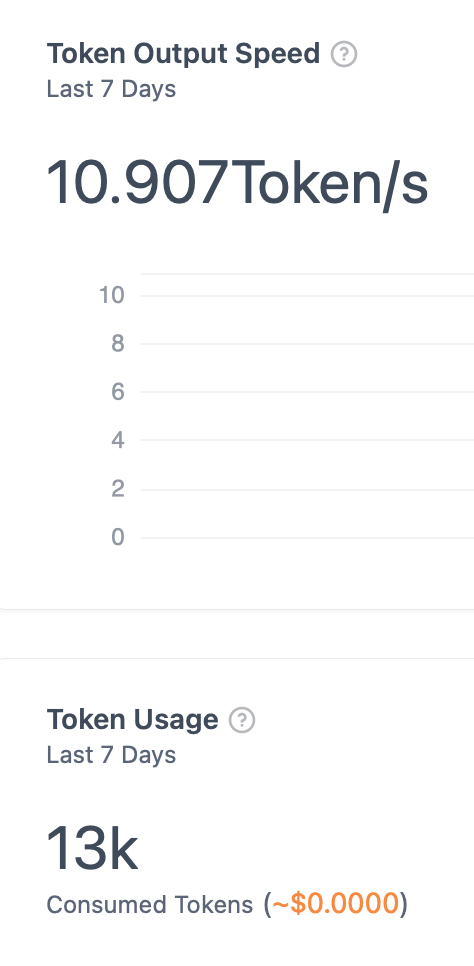
So, here’s the result of running ollama ps after putting 24576 in the Size of context window for the generative AI app I made with Dify. It’s processing at a neat 100% GPU usage. Victory!

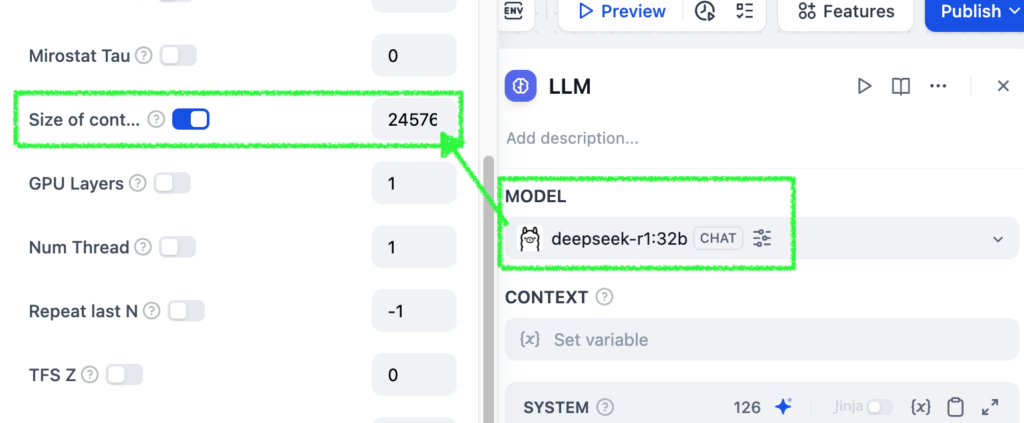
This is where you set the context length of your AI app in Dify:
Last Miscellaneous Notes
In the previous and this article, I introduced methods for fine-tuning the environment side to run LLMs effectively. Since I only have 32GB of unified memory, it’s been always challenging for me to use LLMs. Thanks to new technology, it has become easier to enjoy open-source LLMs more than before. I hope that even one more person can do so.
I have not conducted any investigations regarding execution speed, so please try it out yourself. At least, just by understanding and implementing the method to accommodate the memory required by LLMs or fit them into 100% VRAM, I think you will find that recent models can be quite enjoyable at a practical speed. 10 tokens per sec should be enough most cases.
To be honest, I think it’s tough to do all sorts of things with a local LLM on just 16GB. On the other hand, if you have 128GB, you could run locally LLMs in parallel.
Recently, while Chinese companies’ models have been highly praised for their performance, there are also discussions about prohibiting their use due to concerns over information leaks. Since you can run them locally, you don’t need to worry and can try them freely. Personally, I like the performance and quick response of the newly released French model mistral-small:24b. It’s also very nice that it doesn’t involve Chinese language or characters like Chinese-made models do (maybe I’m a bit sick of it). Does anyone know when the final (non-preview) version of QwQ will be available?
Image by Stable Diffusion (Mochi Diffusion)
Simply, I asked for an image of lots of goods loaded onto a llama. Initially, I had Mistral-Small 24B create prompts based on my image, but it was completely unsatisfactory. It seems that rather than writing all sorts of things, just listing essential words and repeating generation leads to something more fitting.
Date:
2025-2-2 1:55:30
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
A Llama with heavy load of luggage on it
Exclude from Image:
Seed:
2221886765
Steps:
20
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
CPU & GPU