

音声クローン技術の OpenVoice を Mac にインストールして使ってみました。作業を始めてから実際に使えるようになるまで結構大変だったので、やり方をまとめます。また、OpenVoice V2 は日本語ネイティブ対応ということですが、TTS (Text-To-Speech) に使われている MeloTTS の日本語能力がよろしくないので、macOS に標準搭載されている say コマンドで生成した音声を元にクローン音声を生成するスクリプトを書きました。そちらはなかなかの成果が出たので、合わせて紹介します。
OpenVoice (オフィシャル GitHub): https://github.com/myshell-ai/OpenVoice/
Weel さんの紹介記事 (こちらで知りました): https://weel.co.jp/media/tech/openvoice
Contents
注意点
OpenVoice v2 は MIT ライセンスで公開されているので、ソースコードも生成された音声も商用利用可能です。ただし、クローン元となる音声を利用する権利を有していない場合は、商用か否かにかかわらず生成された音声を公開する権利はありません。現在の法律がどうであれ、AI の進歩と共に法整備も進んでいくはずです。声やしゃべりで生計を立てている方々もいる以上、許可無く誰かの音声を使用することは何らかの形で罰せられる可能性があります。そのことを理解した上で本記事を読み進めてください。また、ご自身の音声データを公開する場合においても、ライセンスの明記は行うようにしましょう。
免責事項:
このサイトで提供される情報や方法を使用して行われた行為については、私たちは一切の責任を負いません。特に、他人の無断使用または違法な手段によって得られた音声データを使用して音声クローンを作成し、公開することは完全に利用者の自己責任であり、その結果として生じるあらゆる問題やトラブルについても当方は何ら関知せず、一切の責任を負わないものとします。
法律により保護された著作権やパブリシティ権等が侵害される可能性のある行為を行う際には、利用者は事前に適切な法的措置を講じ、自己のリスクにおいて行動するものとし、当方はその結果生じる一切の損害について責任を負わないものとします。
なお、この免責事項は日本国の法律に基づいて解釈されるものとし、適用されるべき法域については当事者の本拠地が所在する国または地域の法律ではなく、日本国の法律を選択的に適用することに同意するものとします。
以上のご理解とご了承をいただきますようお願い申し上げます。
環境
動作確認ができた環境
macOS: 14.5
ffmpeg version 7.0.1
pip version 24.2環境構築手順
入っていなければ、ffmpeg をインストール (もちろん brew が必要です):
brew update
brew install ffmpegディレクトリを作って OpenVoice リポジトリをクローン。ディレクトリ名はお好きにどうぞ:
mkdir OpenVoice
cd OpenVoice
git clone https://github.com/myshell-ai/OpenVoice.git .仮想環境を構築して入る。ボクは得意のpipenvですが、これもお好きなのをお使いください。Python は 3.9 必須らしいです:
pipenv --python 3.9
pipenv shellpipを最新にし、torch、chardet、そして OpenVoice をインストール:
python -m pip install --upgrade pip
pip install torch chardet
pip install -e .OpenVoice V2 をダウンロードして展開:
※ チェックポイントの最新版 (unzip の対象) は、https://github.com/myshell-ai/OpenVoice/blob/main/docs/USAGE.md の Download the checkpoint from here and extract it to the checkpoints_v2 folder. で確認のこと!
wget https://myshell-public-repo-host.s3.amazonaws.com/openvoice/checkpoints_v2_0417.zip
unzip checkpoints_v2_0417.zip
rm checkpoints_v2_0417.zip以下に従ってファイル openvoice/se_extractor.py を編集 (22行目のcudaをcpuにし、float16をfloat32に変更):
[[[IMPORTANT]]] modify OpenVoice source for Apple Silicon Mac: https://github.com/reid-prismatic/OpenVoice-Scribe/commit/f681f5bcbc18df3f356953928a78ba6dcff9de99
def split_audio_whisper(audio_path, audio_name, target_dir='processed'):
global model
if model is None:
model = WhisperModel(model_size, device="cpu", compute_type="float32")
audio = AudioSegment.from_file(audio_path)
max_len = len(audio)(ここは必要な場合のみ) OpenVoice V2 オフィシャルでは、音声生成 (TTS、Text-To-Speech) に MeloTTS を使用しているため、別途インストールする手順が示されています。個人的に日本語の能力は不十分だと思いますが、気になる方、オフィシャルの方法でまずは進めたい方は以下も実施してください:
git clone https://github.com/myshell-ai/MeloTTS
cd MeloTTS
pip install -e .
python -m unidic download(MeloTTS のテストをしたい場合のみ) 以下にテスト用のサンプルコードを貼っておきます (★ MeloTTS テストコード ★をクリックするとコードが開きます)。python japanese.py で実行し、生成された jp.wav をファインダで QuickLook もしくは Terminal からafplay jp.wav で再生できます。テキストの文面は上で紹介した Weel さんの記事の一部ですが、アルファベット表記の “OpenVoice” がガン無視されたり、音引きが部分的にスルーされたり、読点で溜めが無かったり、なんとなく中国語っぽい癖があったり、という感じで、実用するにはきびしいです。ちなみに初回実行時はファイルのダウンロードが発生するので時間がかかります。
★ MeloTTS テストコード ★
from melo.api import TTS
import time
# Speed is adjustable
speed = 1.0
device = 'cpu' # 'mps' にしても動くが、速くはならない
start = time.time()
text = """
OpenVoiceは、正確なトーンカラーのクローニング、柔軟な声のスタイル制御、ゼロショット多言語クローニングを可能にする音声クローニング技術です。
OpenVoiceを使用すると、リファレンス スピーカーの音色を複製するだけでなく、感情、アクセント、リズム、ポーズ、イントネーションなどの音声スタイルをきめ細かく制御できます。
これを使用するとこのような音声が生成できます。
"""
model = TTS(language='JP', device=device)
speaker_ids = model.hps.data.spk2id
output_path = 'jp.wav'
model.tts_to_file(text, speaker_ids['JP'], output_path, speed=speed)
print(f'\nかかった時間: {round(time.time()-start, 2)} 秒\n')OpenVoice を使う
クローンしたい音声を準備
環境の準備ができたら、クローンしたい音声ファイルを準備します。なるべく高品質で、他の人の声や雑音、BGM 等が入っていない、10秒以上の音声がよさそうです。参考まで、ffmpegで MP4 の映像ファイルから MP3 の音声を書き出すなら、こんな感じで行えます:
ffmpeg -i input.mp4 -vn -acodec libmp3lame myvoice.mp3OpenVoice/resources フォルダに入れておきます (ファイル名 myvoice.mp3はサンプルコードで使用しているので、そのまま使いましょう):
cp myvoice.mp3 resourcesまずはオフィシャルのテストコードで試す (MeloTTS 必須)
オフィシャルのサンプルコード (demo_part3.ipynb GitHub で見るならこちら) を適当にいじって日本語だけ生成するようにし、かかった時間を表示するようにしたものがこちらです。上の手順で MeloTTS をダウンロードした場合はこれでクローンのテストが行えます。OpenVoice ディレクトリ直下においてpython test.pyで実行します:
import os
import torch
from openvoice import se_extractor
from openvoice.api import ToneColorConverter
from melo.api import TTS
import time
home_dir = './'
ckpt_converter = home_dir + 'checkpoints_v2/converter'
device = "cuda:0" if torch.cuda.is_available() else "cpu"
output_dir = 'outputs'
start = time.time()
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
os.makedirs(output_dir, exist_ok=True)
reference_speaker = home_dir + 'resources/myvoice.mp3' # This is the voice you want to clone
target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, vad=False)
texts = {
'JP': "彼は毎朝ジョギングをして体を健康に保っています。"
}
src_path = f'{output_dir}/tmp.wav'
# Speed is adjustable
speed = 1.0
for language, text in texts.items():
model = TTS(language=language, device=device)
speaker_ids = model.hps.data.spk2id
for speaker_key in speaker_ids.keys():
speaker_id = speaker_ids[speaker_key]
speaker_key = speaker_key.lower().replace('_', '-')
source_se = torch.load(f'checkpoints_v2/base_speakers/ses/{speaker_key}.pth', map_location=device)
model.tts_to_file(text, speaker_id, src_path, speed=speed)
save_path = f'{output_dir}/output_v2_{speaker_key}.wav'
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
print(f'\nかかった時間: {round(time.time()-start, 2)} 秒\n')生成された音声は outputs に保存されます。afplay outputs/output_v2_jp.wav で再生しましょう。サンプルの文章がちょうど良いのか悪くない感じがするものの、文章をいろいろ変えて試すと結構きびしいことがわかってきます。でもこれって、OpenVoice の問題じゃないんです。
OpenVoice はボイスチェンジャーである
outputs ディレクトリには output_v2_jp.wav 以外に、tmp.wav ファイルがあるのがわかります。実はこれは MeloTTS で作られた、ベースとなる音声ファイルです。OpenVoice はその音声を、ユーザが用意した音声の特徴で置き換える、つまり乱暴に言うとボイスチェンジャー的なことをしています。音楽で言えばピアノで弾いた曲の音色をギターに変えるようなことをしているので、ベースのアクセントを踏襲しますし、他の言語でもしゃべれてしまう、というわけです。
ええぃ、MeloTTS はキツい!Siri さん、お願いします!
我らが macOS にはいにしえ (Mac OS 9?) より音声合成技術が備わっております。Siri さんなんかは iPhone の普及も相まって、なかなかに鍛わっています。面倒なインストール作業も必要なく、ファイルへの書き出しにも対応しています。というわけでボクはあまり使えない MeloTTS を捨て、音声合成部分に macOS 標準搭載のsayコマンドを使用することにしました。簡単なオプションも追加したスクリプトを書いたので紹介します。名付けて clonesay (クローンせい!) です。やかましいですね。
python clonesay.py でとりあえず動きます (-hを付けると、利用できるオプションの一覧を表示します)。macOS で指定されている音声で、テスト用に入れているデフォルトのテキストを音声合成し、myvoice.mp3 の声色にクローンして outputs/output_jp.mp3 として書き出してくれます。実行中にはごちゃごちゃと英文が表示されますが、最終的に「かかった時間」が表示されればおそらく問題無いはずです。
import os
import torch
from openvoice import se_extractor
from openvoice.api import ToneColorConverter
import time
import subprocess
import argparse
# macOS の 'say' コマンドを使用して、ベースとなる音声ファイルを生成
def text_to_speech(text, output_file):
command = ['say', '-o', output_file, text]
subprocess.run(command)
# 引数を解析するための設定
parser = argparse.ArgumentParser(description='OpenVoice を利用して音声のクローニングを行います。事前にクローンしたい音声ファイルを resources/myvoice.mp3 \
として保存してから実行してください。macOS の "say" コマンドを利用しています。\
https://github.com/myshell-ai/OpenVoice/')
parser.add_argument('-i', '--input', type=str, required=False, help='しゃべらせたいテキストを直接入力します。例 -i "こんにちは、おげんきですか"')
parser.add_argument('-f', '--file', type=str, required=False, help='しゃべらせたいテキストが入力されたファイルを指定します。同時に指定した場合は -i が優先されます。')
parser.add_argument('-s', '--source', type=str, required=False, help='テキストから音声を生成せずに、指定した既存の音声ファイルを元にクローンを作成します。\
同時に指定した場合は -i、-f が優先されます。')
parser.add_argument('-o', '--output', type=str, required=False, help='出力するファイル名を指定します。利用できるフォーマット: mp3(デフォルト), aiff, wav.')
parser.add_argument('-r', '--reference', type=str, required=False, help='クローン元となる音声ファイルを指定します。\
初回指定時には必要なデータが processed ディレクトリに作成されます。')
parser.add_argument('-p', '--play', action='store_true', required=False, help='生成された音声を自動再生します。')
args = parser.parse_args()
home_dir = './'
device = 'cpu'
ckpt_converter = home_dir + 'checkpoints_v2/converter'
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
output_dir = 'outputs'
language = 'jp'
src_path = f'{output_dir}/tmp.aiff'
os.makedirs(output_dir, exist_ok=True)
start = time.time()
# クローン元となる音声ファイルの指定
if args.reference:
reference_speaker = args.reference
else:
reference_speaker = home_dir + 'resources/myvoice.mp3' # クローン元となる音声ファイル
target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, vad=False)
# 発声するテキストを指定もしくは、既存の音声ファイルを指定
if args.input:
input_text = args.input
#elif os.path.isfile(args.file) and os.path.getsize(args.file) > 0:
elif args.file and os.path.isfile(args.file):
with open(args.file, 'r', encoding='utf-8') as file:
input_text = file.read()
elif args.source:
src_path = args.source
input_text = ''
else:
input_text = """
しゃべらせたい文章を、ダッシュアイで指定してください。その他利用可能なオプションは、ダッシュエイチで確認できます。
"""
# 発声するテキストの元となる音声ファイルを生成
if input_text != '':
text_to_speech(input_text, src_path)
source_se = torch.load(f'checkpoints_v2/base_speakers/ses/{language}.pth', map_location=device)
save_path = f'{output_dir}/output_{language}.mp3' # デフォルトの出力ファイル
# 出力ファイル名の指定がある場合
if args.output:
output_extension = os.path.splitext(args.output)[1].lower()
if output_extension in {'.mp3', '.aiff', '.wav'}:
save_path = args.output
else:
save_path = os.path.splitext(args.output)[0] + '.aiff'
else:
save_path = f'{output_dir}/output_{language}.mp3'
# OpenVoice processing part
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
print(f'\nかかった時間: {round(time.time()-start, 2)} 秒\n')
# Play the generated MP3 file using the default media player
if args.play and os.path.isfile(save_path):
# Use afplay for macOS, which is a simple command-line audio player
print(f'ファイル: {save_path}')
if input_text !="":
print(input_text)
subprocess.run(['afplay', save_path])
else:
print("The output file does not exist.")
簡単にいろいろ試すなら、-iオプションでテキストを入力し、-pで生成後に再生するようにするのが良いと思います。例えばこんな感じ:
python clonesay.py -p -i "本日皆さんに集まっていただいたのは、\
新しいエーアイ活用の方法を議論するのが目的です。どうぞ、よろしくお願いします。"(“AI” は “エーアイ” にするなど、工夫は必要です)
macOS の音声を変えてみる
多分 macOS デフォルトの音声は Siri (声 2) ですが、さすがに男性の声に寄せるのはきびしいと思います。そのような場合には、システム設定で変更しましょう。コマンドでのやり方はみつかりませんでした (声の管理… から、追加もできるようです)。
システム設定… → アクセシビリティ → 読み上げコンテンツ → システムの声
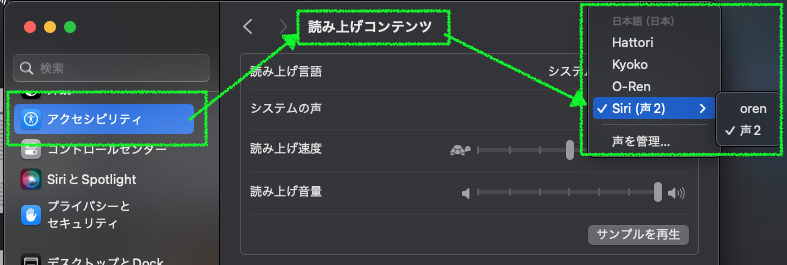
感想
AI による音声のクローニング手法はいくつかあるようで、以前 GPT-SoVITS というのをいじったときには結構衝撃的な結果でした。数秒の音声からかなり高い再現度だったからです。今回はたまたま Weel さんで見つけた OpenVoice を試したわけですが、正直クローニングのクオリティとしては劣っていると感じています。ベースの音声 (Siri さん) に寄りすぎだな、と。ただ、今後ベースの TTS (Text-To-Speech) の性能がとんでもなく高く、自分がクローンしたい声質に近いものが現れたときには TTS だけ乗り換えれば良いわけで、将来性はあるのかもしれない、とも思っています。また、OpenVoice は TTS に頼らない技術です。なので、ボクのサンプルスクリプトの-sオプションでリアルの人物がしゃべった音声ファイルをソースとして指定すれば、ナチュラルな結果が得られるでしょう。何か使い道はありそうですよね。mac ユーザの方は遊んでみてください。
Image by Stable Diffusion (Mochi Diffusion)
今回の画像は何のひねりも無いプロンプトで描いてもらいました。ステップ数が高ければキレイになったりリアルになったりするわけでも無いんですよね。ランダムでしばらく回し、めぼしい Seed 値が見つかった後は何度か Steps の増減を繰り返し、指と女性の顔が一番ブキミじゃなかった、マシだった、という一枚に決めました。
Date:
2024年9月23日 23:14:52
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
human voice clone technology
Exclude from Image:
Seed:
85304328
Steps:
25
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
All