Alibaba の Qwen チームが Mac 用に MLX 版の Qwen3 をリリースしたので Qwen/Qwen3-32B-MLX-4bit を使ってみました。他の記事でも書いているとおり Ollama では使えないので、MLX-LM をメインで使っています。また、MLX-LM、LM Studio、Ollama をバックエンドにしてそれぞれで使える Qwen3 の生成速度の違いも軽くテストしてみました。
海外の掲示板では、せっかく MLX 用に変換してくれたのに DWQ 量子化していないじゃないか、みたいなコメントも見ましたが、そのあたりの影響かな?と思えそうな結果になっています。
モデル情報元
公式 X:
https://twitter.com/Alibaba_Qwen/status/1934517774635991412
公式 Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
MLX に限らず、Qwen チームが量子化した Qwen3 全てのバージョンやベースモデルがあります。
試した環境
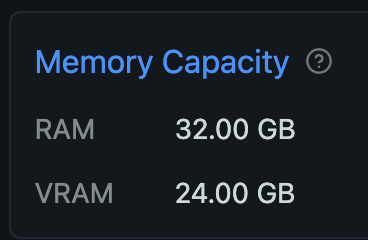
- Mac Studio M2 Max 32GB GPU (24,576 GB を VRAM に割り当て済み。やりかたはこちら)
- macOS: Sequoia 15.5
- Python 仮想環境: pipenv version 2025.0.3 (なぜ pipenv なのか、みたいな話はこちら)
- Python: 3.12.11 (特に意味は無し)
- MLX-LM: 0.25.2 (
pip install mlx-lmでインストール) - Open WebUI: 0.6.15 (
pip install open-webuiでインストール) - Ollama: 0.9.1 preview (新アプリのプレビュー版。詳しくはこちら)
- LM Studio: 0.3.16 (build 8)
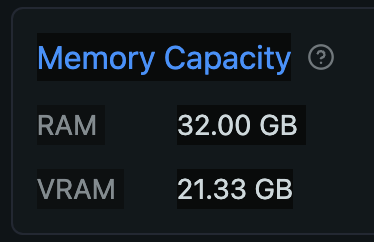
- LLM: Qwen/Qwen3-32B-MLX-4bit (17.42 GB / 今回のメイン)
- LLM: mlx-community/Qwen3-32B-4bit-DWQ (18.54 GB / 比較用)
- LLM: qwen3:32b-q4_K_M (20 GB / Ollama のモデル、比較用)
インストール方法や各アプリケーションの使い方などはリンク先や他のウェブサイトを参照してください。少なくとも何らかの Python 仮想環境を作り、MLX-LM か LM Studio のインストールがしてあれば使えます。
モデルのダウンロード
色々方法を試した結果、MLX-LM で Hugging Face にアップされているモデルを使うのはこの方法がよさそうかと。MLX-LM 用にでも作った仮想環境に入り、Hugging Face 関連パッケージをインストールしてコマンドからインストールを行います。
モデルは自分の GPU (割り当て VRAM サイズ) に 100% 乗る、Qwen/Qwen3-32B-MLX-4bit にしていますので、お好みのものに変更してください。
pip install -U huggingface_hub hf_transfer
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download Qwen/Qwen3-32B-MLX-4bitダウンロードが終わると、~/.cache/huggingface/hub/models--Qwen--Qwen3-32B-MLX-4bitに保存されます。mlx-community のモデルのようにmlx_lm.manage --scanでは表示されませんが、名前を指定すれば使えますので安心してください。
動作確認
MLX のチャット (CLI) でさっくり試せます。質問によっては思考 (<think>~</think>) だけでトークンを使い切ってしまうので、--max-tokens 8192等として上限を増やして実行したほうが良いでしょう。
mlx_lm.chat --model Qwen/Qwen3-32B-MLX-4bit --max-tokens 8192実行結果のサンプル:
% mlx_lm.chat --model Qwen/Qwen3-32B-MLX-4bit --max-tokens 8192
Fetching 10 files: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:00<00:00, 145131.63it/s]
[INFO] Starting chat session with Qwen/Qwen3-32B-MLX-4bit.
The command list:
- 'q' to exit
- 'r' to reset the chat
- 'h' to display these commands
>> こんにちは。自己紹介してください
<think>
The message is in Japanese. The person is greeting me and asking me to introduce myself.
I should respond in Japanese since the message was in Japanese. I'll provide a brief introduction about myself as an AI assistant.
The message says: "Hello. Please introduce yourself"
My response will be in Japanese:
</think>
こんにちは!私は通義千問(つうぎせんもん)で、英語ではQwenと呼ばれます。私はアリババグループ傘下の通義実験室が独自に開発した大規模言語モデルです。質問への回答や、物語、公文書、メール、脚本など文章の作成に加えて、論理的推論やプログラミング、さらにゲームにも対応できます。また、多言語をサポートしており、さまざまなタスクを効果的に支援できます。どうぞよろしくお願いいたします!
>> q
MLX-LM の CLI チャットは Ollama ほどイケてないので、動くのが確認できたらさっさと次に進みましょう。
API サーバを立てる
MLX-LM でサーバを実行するだけで API サーバとして使えます。セキュリティ的に本番環境向けでは無いという警告が出ますが、とりあえず使う分には良いでしょう。
ボクは LAN 内の別の Mac で動く Dify から接続するのと Open WebUI がポート 8080 を使っているということもあり、--host 0.0.0.0と--port 8585を指定しています。--log-level DEBUGを付けると、トークンごと (?) の出力と、tokens-per-sec が表示されます。
またここで--model Qwen/Qwen3-32B-MLX-4bitとしてモデルを指定することもできますが、指定しなくてもクライアント側で指定したモデルがオンザフライで読み込まれるので気にしなくてよさそうです。
mlx_lm.server --host 0.0.0.0 --port 8585 --log-level DEBUGサーバが立ち上がったかどうかは、ブラウザで利用可能なモデル一覧を表示させることで確認できます。
http://localhost:8585/v1/models
実行例:
{"object": "list", "data": [{"id": "lmstudio-community/DeepSeek-R1-0528-Qwen3-8B-MLX-4bit", "object": "model", "created": 1750501460}, {"id": "mlx-community/QwQ-32b-4bit-DWQ", "object": "model", "created": 1750501460}, {"id": "Qwen/Qwen3-32B-MLX-4bit", "object": "model", "created": 1750501460}, {"id": "mlx-community/Qwen3-32B-4bit-DWQ", "object": "model", "created": 1750501460}]}
mlx_lm.manage --scanでは表示されないQwenやlmstudio-communityのモデルも見えますね。
Dify で作った超簡単チャットアプリで「こんにちは。自己紹介してください」と投げたときの token per sec (トークン数/秒) は以下となりました。悪くないですよね。個人的には 11 あればヨシと考えています。
2025-06-21 19:25:58,696 - DEBUG - Prompt: 39.744 tokens-per-sec
2025-06-21 19:25:58,697 - DEBUG - Generation: 17.347 tokens-per-sec
2025-06-21 19:25:58,697 - DEBUG - Peak memory: 17.575 GB
あとは Open WebUI なり Dify なりでモデルプロバイダとして登録し、使ってみるだけです (参考手順)。上記のコマンドでダウンロードしたモデルは、LM Studio でも使えるのでディスクスペースの有効活用になります。ただし、モデル名は読めません。下のスクリーンショットの一番上が Qwen/Qwen3-32B-MLX-4bit で、一番下は mlx-community/Qwen3-32B-4bit-DWQ です。なはは。
速度の違い (参考情報)
Dify を使って、いくつかの量子化バージョンと API サーバの組み合わせで Qwen3 32B を実行した結果が以下の表となります。
テスト内容としては、1ラウンドのプロンプトを 4回投げて「監視」画面でトークン出力速度の平均を見ました。
一つ失敗した点がありまして、設定した Size of context window: 25600 が Ollama には大きすぎたため GPU の使用率が 100% に行かず、10%/90% CPU/GPU という不利な結果となってしまいました (ollama psより)。よって、Ollama のみ最大トークン数を半分の 12800 に下げて 100% GPU で再テストしています。
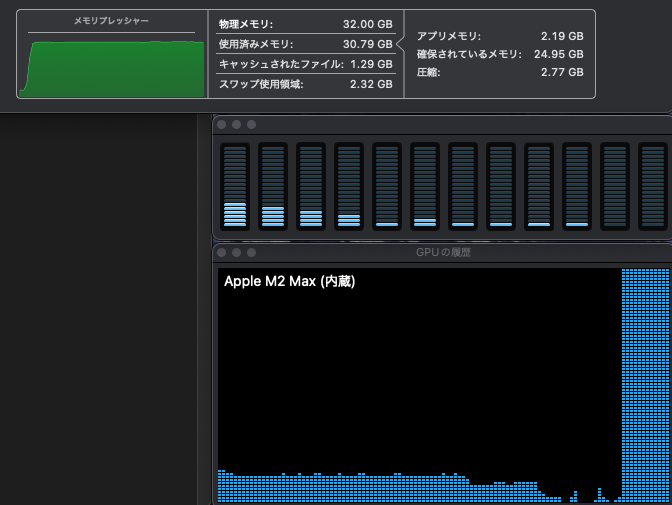
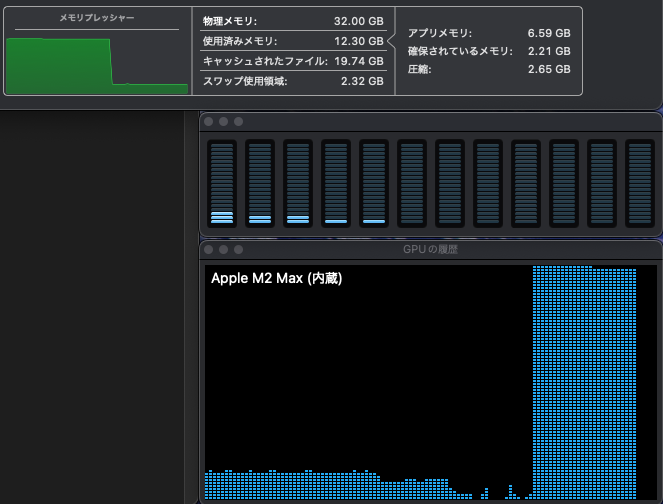
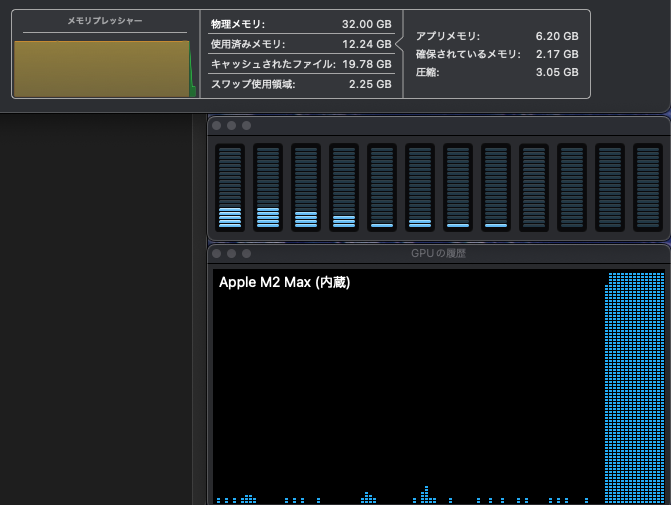
実行中のメモリプレッシャーに関しては、MLX モデルは全て 8割ほどで推移していました。LM Studio はモデルのロード後常にメモリ上にあるため、メモリの占有量はほぼ変化しない代わりに推論の開始が早いという特徴があります。チャット内容のサマリが生成されないのは、Dify のシステム推論モデルに設定している Ollama のモデルが動くだけのメモリ容量がないからかもしれません。
| モデル | モデルサイズ | API サーバ | 平均トークン/秒 | 特徴・メモリプレッシャー |
|---|---|---|---|---|
| Qwen/Qwen3-32B-MLX-4bit | 17.42 GB | MLX-LM | 19.302 | サマリ生成の後半分程に下がる |
| Qwen/Qwen3-32B-MLX-4bit | 17.42 GB | LM Studio | 23.19 | サマリが生成されない。メモリ使いっぱなし |
| mlx-community/Qwen3-32B-4bit-DWQ | 18.45 GB | MLX-LM | 21.058 | サマリ生成の後半分程に下がる |
| mlx-community/Qwen3-32B-4bit-DWQ | 18.45 GB | LM Studio | 24.503 | サマリが生成されない。メモリ使いっぱなし |
| qwen3:32b-q4_K_M | 20 GB | Ollama (max. 25600 tokens) | 9.511 | サマリ生成後はミニマム |
| qwen3:32b-q4_K_M | 20 GB | Ollama (max. 12600 tokens) | 12.146 | サマリ生成後はミニマム |
評価に使ったプロンプトは以下の 4つとなります。全て一往復で終わらせています。メモリプレッシャーが下がって安定し、GPU の使用量がゼロになったのを確認してから新しいチャットで次のプロンプトを実行しています。
こんにちは。自己紹介してください
ボードゲーム「オセロ」のルールを正確に教えてください
微分積分を再度勉強しようと思います。数式を交えてさわりの部分を教えてください
あなたはマーケティングのプロフェッショナルです。
日本では一部の自動販売機では、夏でもホットの缶コーヒーが売られています。それは、夏場のタクシー運転手は暑い中タクシーを利用する乗客のために社内の温度を低くしており、冷えた体を温めるために缶コーヒーを求めるからです。
同じような視線からでも別の視線からでも構いませんが、現在は冬場しか売られていないコンビニレジ横のおでんを通年で販売するためにはどのような方策があるか、提案してください
System prompt と LLM の設定は以下の内容で行いました (最近の Qwen の LLM は優れた多言語対応が進んでいますが、念のため)。
- System prompt:
日本語で質問されたら日本語で回答してください。
If asked in English, answer in English.
Never user Chinese
- Temperature: 0.1
- Max Tokens: 25600 (Ollama は Size of context window)
- Thinking mode: True (Ollama には該当項目無し)
- それ以外はデフォルト (未設定)
テストの結論
メモリに余裕があるなら、LM Studio + mlx-community/Qwen3-32B-4bit-DWQ の生成速度が最強ですね。トークン/秒の数字を鵜呑みにすれば、Ollama + Qwen3-32B-4Q_K_L の倍の速度が出ています。ただ、回答の中で「おでん」を「おでn」とか「オーデン」と書いていたので、この組み合わせだと何かが欠落するような要素があるのかもしれません。「オーデン」として夏に売り出すというのはアリかもしれませんけど。いや、どうか。
回答内容や日本語に安心感があったのは Qwen/Qwen3-32B-MLX-4bit でした。個人的には MLX-LM との組み合わせが使いやすいと感じています。
Qwen に限らず、今後 LLM の開発元が MLX 化と量子化までを行ってくれると搭載メモリの小さい Mac でも効果的に使える様になるはずなので、そんな未来に期待したいですね。
ただ今のところ MLX-LM の量子化については公式以外にあまり情報が無いのがつらいところです。
Image by Stable Diffusion (Mochi Diffusion)
「3人兄弟の徒競走」をイメージして描いてもらいましたが、やはり数字の指定には弱く、4人登場する画像が多かったです。顔の描写も人数が増えるほど破綻し、ステップ数を増やしても良くなるわけではないので後ろ向きのを採用しました。兄弟っぽいし、差も付いてるし。
Date:
2025年6月22日 1:01:01
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
footrace of three brothers on a track
Exclude from Image:
Seed:
309909096
Steps:
20
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
CPU & GPU