

本気のローカル LLM 界隈では 32GB 程度の RAM (ユニファイドメモリ) はジョークです。全てを GPU に割り当てられないので、本当に大規模 (70B 以上) な LLM には 32GB では足りません。ボクは M2 Max 32GB RAM の Mac Studio を買ってから知りました。悔しいです。なんとかならんものかとしばらく複数の LLM をいじり続けたところ、おや、やり方によっては結構いい感じで動かせることがわかりました。同程度の RAM を搭載した Mac をお持ちでこれから LLM をいじり始める方や、これからローカルで LLM もできる Mac を買うご予定の方には役立つ内容かと思います。LLM 自体の深いところ、量子化やパラメータなどの詳細にはあまり触れていないので、あしからず。
Contents
ローカル LLM とは
ネットで「ローカル llm とは」と調べれば山ほど情報が出てきますが、簡単に言えば、自分のパソコンで動かせる ChatGPT 的な大規模言語モデル (Large Language Model) を指します。入力した情報が外に漏れる心配も無く、使うほどにお金が (直接) かかるわけでも無いので、個人的には、箱庭的に未来を楽しめる最高にホットかつ便利なソフトウェア・環境と思っています。はじめて Macintosh を手に入れた時やインターネットにつないだ時に近い、触ること自体が楽しいモノですね。
32GB RAM の限界
RAM 容量 32GB の M1, M2 Mac でいい感じに利用できるモデルの実サイズは、20GB ぐらいが限界です。実行時にごっそり RAM に乗っかるからです。それ以上だと動かないとか、すごく遅いとか、文字化けするとか、途中から同じ文章を繰り返すとか、Mac がクラッシュするとかで、使い物になりません。複数のモデルを試した感じ、量子化して実用に耐えるのは Q4_0 や Q4_K_M 位までです。よって、元の LLM は 33B あたりが限界ということになります。つまり、70B だったり 100B 以上の「ChatGPT 4 を超えた!?」みたいな騒がれ方をするヘビー級 LLM モデルの実行は、32GB RAM だとまず無理ですので諦めましょう。ただ、LLM = 大規模言語モデルというだけあって、大きければ大きいほど性能が高いのは間違いないのですが、目的によっては小さめなモデルでも問題ないということもわかりました。わりとよくある 13B 位のモデルであれば、8ビット量子化 (Q8_0) でキビキビ動くので、試す価値アリだと思います。
(2025/01/30 追記) 上の説明はほぼその通りですが、33B あたりの LLM モデルでもなるべく多くのコンテキスト長 (トークン数) を扱うための VRAM 最適化方法を別の記事にまとめました:
https://blog.peddals.com/fine-tune-vram-size-of-mac-for-llm
(2025/02/02 追記) ファインチューニング: 2 の記事 ↓ では、Ollama へ K/V Cache を導入した中心的コントリビュータのブログにある、超便利ツールの紹介もしています。自分の VRAM 容量に収まるモデルのパラメータ数、量子化レベル、コンテキスト長が確認できます:
https://blog.peddals.com/ollama-vram-fine-tune-with-kv-cache
マイベスト LLM
というわけで、2024年 5月中旬現在の、ボクの目的別ベスト LLM はこちらです:
| 目的 | モデルとサイズ | 量子化 | 主な理由 |
| コーディング補助 | Deepseek Coder 33B Instruct | Q4_K_M | 唯一正しい迷路生成のコードが書けた |
| 日本語の英訳 | Llama 3 8B Instruct | Q8_0 | 速く、ナチュラルな英語にしてくれる |
| 日本語チャット | Command-R 35B | Q4_0 | Elyza 等の、公開されている日本語特化 LLM より優秀 |
コーディング補助
ボクがローカル LLM に望む一番の能力は、Python コーディングの補助です。評判の良いモデルを 5つほど試したところ、DeepSeek Coder Instruct 33B の性能が一番でした。Copilot 無料版 (GPT-4 Turbo だとか?) よりも期待する回答をくれることが多いです。一度の質問 (ゼロショット) でズバリのコードが生成されることもありますし、エラーが出たり無限ループに陥った場合でも、その後の数回のやりとりで動くコードを生成できました。出力は簡単な Markdown で、見た目もコピーも楽です。応答速度の面でも、Copilot 無料版と同じか速いくらいです。中国の企業が作っているモデルだからか大手のサイトなどでは大きく取り上げられていない印象ですが、性能は高いです。33B は 32GB RAM には大きすぎるので量子化が必須です。速度や性能のバランスが良いとされる Q4_K_M は 19GB なので、サイズも問題なしです。
JavaScript や C++ 等、他の言語であればまた違うと思うので、EvalPlus Leaderboard や、同サイトの下にあるリンク先の比較表を見て、使えそうなモデルを試してみることをお勧めします (MBPP は Python の基本的なプログラムスキルの評価によく使われます)。ボクがテストに使っていたプロンプトはこんな感じです:
write a python code that generates a 13x13 perfect maze日本語の英訳
日本語の英訳は、ブログの英訳に使い始めました。実際にボクの超大作ブログの英語版を書く際には、オンライン・ローカルそれぞれの LLM をいくつか試してみました (テストついでに生成されたモノを使っているので、精度のばらつきがあるかもです)。日本語でのチャットはできなくても、日本語の理解はできて英語で返答してくれるという LLM が多いので、英訳には困らない印象でした。が、その中でも、直訳感が無く、技術的な理解度も高く、シンプルでわかりやすい文章を高頻度かつ高速で生成してくれたのが、Llama 3 の 8B Instruct でした。日本語であれ英語であれ、自分で読むことはできても読みやすい文章を書くのは難しいものです。まさに、AI の使いどころだと思います。ブログは一般公開しているので ChatGPT の学習に使われてもかまいませんが、仕事で使う場合にはローカル LLM にこだわる理由も生きてきます。ちなみに 8B モデルを使っているのは、その上は 70B だからですが、ボクには十分でした。
日本語チャット
LLM を日本語チャットに使うことはほぼありませんが、Elyza の 13B Instruct と比較した場合、Command-R 35B の方が内容が濃く、会話自体が楽しいです。ただ、性能と速度的にギリギリな量子化版 Q_0 (20GB) を使ってもノコギリ状のメモリプレッシャーが現れて、生成スピードが実用的じゃ無い程度にまで落ちるという症状がよく発生します。メモリプレッシャーがオレンジで高止まりしていると逆に安定して生成できるので、モデルの特性なのか、実行環境である llama.cpp や Ollama のバグなのか不明ですが、どうにか解決できると日本語メインの方には強力なモデルだと思います。

タイムリーな情報として今日 Dell の情報漏洩のニュースがあったので、適当に拾った英語の記事を和訳させてみました。Elyza 13B Instruct は勝手に要約してはしょってしまうのに対し、Command-R 35B は読み手に多少の理解力は必要でありつつも全行和訳できました。さらに続けて「以上の情報から私はどのような対応を取るべきでしょうか?」と聞いた答えはこちらです。すばらしい。
まずはDellからのメールに書かれている手順に従うことをお勧めします。 Dellは影響を受けたお客様向けに専用サポートセンターを設定しており、メールに電話番号が含まれています。 また、信用機関や金融機関にも連絡して状況を確認することをお勧めします。
現時点でパスワード変更も良い考えです。 特に最近になってから、再利用していない場合や、強固いパスワードをお勧めします。 パスワードマネージャーを使うと、すべてのオンラインアカウントでユニークなパスワードを使いやすくなります。 その上で、メールやオンラインアカウントの監視を強化することをおすすめします。 疑わしい活動を見つけたら、直ちに銀行やクレジットカード会社にお知らせください。
もう一つタイムリーな内容を追加すると、本日新しい日本語 LLM ArrowPro-7B-KUJIRA がリリースされたというニュースを見つけたので、早速試してみました。7B モデルなので、量子化せず f16 のままでも十分小さく速く、日本語の精度も高いです。チャットを楽しむ分には結構良い感じです。調子に乗って上記 Dell の英文ニュースの日本語訳も試してみました。結果は、まぁ悪くは無いです。ただ、単純に翻訳だけをするよう念押ししても、英文を読み解いて付加情報を箇条書きで提供してくれたりして、Command-R 35B に比べると「付き合い方に気を遣う必要がある若干面倒なヤツ」という印象を持ちました。もしかしたら System プロンプトなどの調整で良くなる可能性はあるかもしれません。他には Swallow も試しましたが、こちらは実用的なレベルではありませんでした。
実行環境
LLM の実行環境としてはこれらを使っています。上から使っている時間の長い順です。
| 目的 | アプリ名称 | タイプ | 理由、特徴 |
| チャット / API サーバ | Ollama | CLI, API サーバ | 一番メモリの負荷が小さく、動作も速い。日本語 LLM は表示がおかしくなる不具合があったが、Ollama 0.1.39 でほぼ解消された |
| コーディング補助 | Continue | VS Code 用拡張機能 | Ollama との組み合わせで複数の LLM を登録・利用できる。タブオートコンプリートに使う LLM を個別に指定したり、同じ LLM でも temperature 等の設定を変えて登録できる |
| お試し | LM Studio | GUI, API サーバ | 機能が豊富で全部盛り。自分の RAM で使えそうな LLM を探しやすい。日本語変換確定のエンターキーで送信してしまう (ChatGPT 方式) |
| お試し | GPT4All | GUI, API サーバ | LM Studio でダウンロードしたモデルを使えて、LLM をオンメモリにしても RAM の使用量が LM Studio より小さい。日本語モデルとの相性が良い気がする |
それぞれのアプリの使い方まで触れようと思っていたのですが、さすがにボリュームがすごいことになってしまうので、気が向いたら別の記事ににまとめようと思います。全て有名どころなので、探せば日本語での情報もたくさん見つかるでしょう。とりあえず全部インストールしていじってみることをお勧めします。それぞれに良いところがあり、全ての機能や特徴をカバーできているアプリはありません。今回は Ollama については触れておこうと思います。
Ollama で使えるモデルをダウンロードする方法
Ollama はターミナルでコマンドを実行して操作する CLI のチャットボットとしての使い方と、他のアプリからローカル LLM にアクセスさせる API サーバとしてとしての使い方が主な用途になります。Ollama で使えるモデルの入手は以下の方法があります:
- 対応済みモデルを Ollama のサイトで確認し、コマンドでダウンロード
- 未対応のモデルを Hugging Face から直接、もしくは LM Studio 等でダウンロードし、変換
どちらもコツや手順が必要なので、紹介しておきます。
Ollama のサイトで探す
上で紹介した Command-R 35B Q4_0 をダウンロードする手順です。サポート済みモデルが存在していれば、概ね同様の手順でダウンロードできます。ollamaコマンドを実行するので、事前に Ollama のインストールと実行をしておいてください。

(1) Ollama のサイトにアクセスし、上部の Search models にモデル名を入力して探す
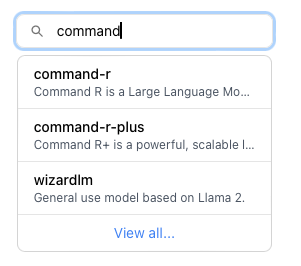
(2) ドロップダウンメニューの、View all tags をクリック
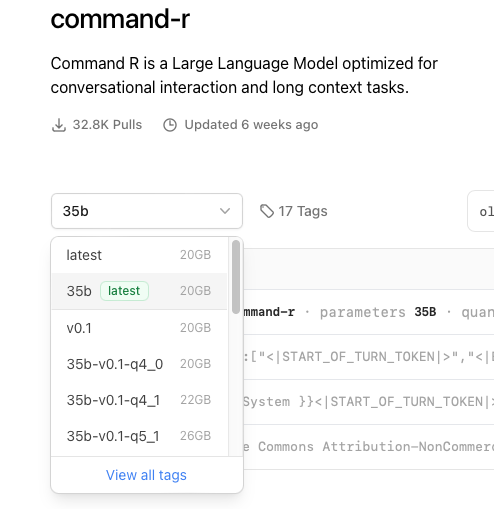
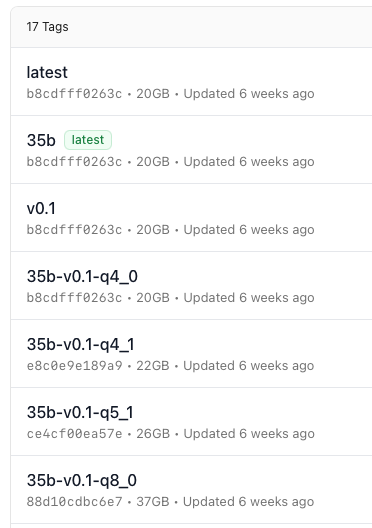
(3) 量子化とサイズのちょうどよさげなものに狙いを付けて、クリック
(4) 先ほどのドロップダウンの右にダウンロードコマンドが表示されるので、その右にあるアイコンをクリックしてコピー
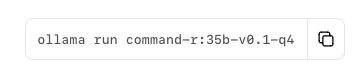
(5) ターミナルにペーストしてそのまま実行するか、runをpullに書き換えて実行 (runはダウンロード後チャットを開始し、pull はダウンロードのみ)
# ダウンロード後すぐチャットするなら:
ollama run command-r:35b-v0.1-q4_0
# ダウンロードだけしておくなら:
ollama pull command-r:35b-v0.1-q4_0Hugging Face からダウンロードして、変換・インストールする
ちょうど良いので、上で紹介した日本語 LLM ArrowPro-7B-KUJIRA での手順です。Ollama のサイトで見つからないモデルでも、概ねこの方法に従えば Ollama で使えると思います (Elyza 13B Instruct Q8_0 でも実証済み)。ざっくり、Transformer フォーマットを GGUF に変換し、モデルファイルを作って読み込ませる、という流れです。GGUF フォーマットのモデルが入手できるなら、手順 (7) の次、(オプション) 以降を実行してください。
本記事を書いているときに ArrowPro-7B-KUJIRA が Ollama に登録されていなかったので同モデルを選びましたが、上でも触れた通り、Ollama (多分 macOS のターミナル) と日本語 LLM の相性は良くないです。出力内容が途中で消えたり、(ハルシネーションではなく) 同じ文章が 2回表示されたりします。特に、改行がない長い文章の時に発生しがちです。デリートキーで文字を消すときも、どこまで消えたかよくわかりません。なので、日本語 LLM を使うときは、GPT4All をお勧めします。 (2024/05/30 更新) Ollama の日本語を含む全角文字の不具合は、0.1.39 でほぼ解決したようです (Discord)。ArrowPro-7B-KUJIRA で試した限り、打ち消した部分にあった不具合は発生していません。ただ、現在行末での改行時に1文字分消えてしまう様なので、Issue を報告しました。→ (2024/06/02) この不具合は Ollama 0.1.40 で修正されました。
(1) Hugging Face の開発元のカードを開く (この場合は DataPilot が本家)
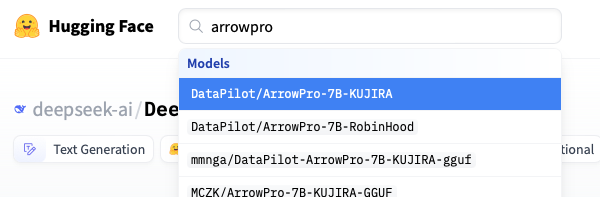
(2) 右の方の三点リーダから、Clone repository をクリック
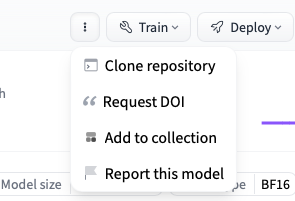
(3) git コマンドがインストール済みなら git clone の右のボタンクリックでコマンドをコピー (git が入ってなければ、まずは brew install git を実行してから)
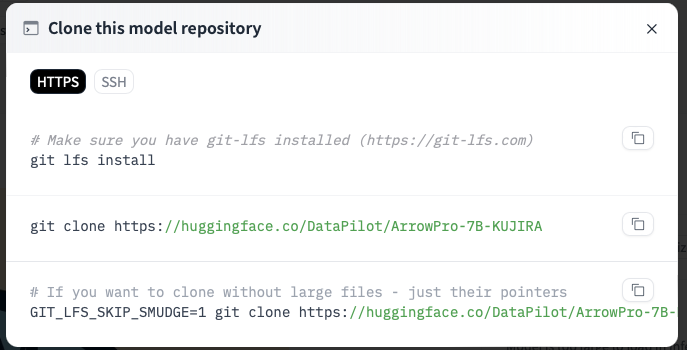
(4) 書類フォルダにLLMフォルダでも作り、その中でコピーしたgit cloneコマンドを実行し、モデルのダウンロード開始
mkdir ~/Documents/LLM
cd ~/Documents/LLM
git clone https://huggingface.co/DataPilot/ArrowPro-7B-KUJIRA(5) ダウンロードを待っている間に、こちら↓の npaka 様サイトの手順に従い、llama.cpp をインストール (1. Llama.cpp のインストールの、 (1)~(4) まで)
llama.cpp による transformersモデル の量子化
(6) Python の仮想環境を作り、必要なライブラリやモジュールのインストール (Pythonバージョン、仮想環境ツールはお使いのものでどうぞ)
pipenv --python 3.11
pipenv shell
pip install -r requirements.txt※ 以降は、モデルのダウンロードが終わってから実行してください。
(7) llama.cpp ができたフォルダから以下コマンドを実行し、transformer モデルを gguf モデルに変換 (M2 Max で、2分くらいで完成)
python convert.py ~/Documents/LLM/ArrowPro-7B-KUJIRA --outtype f16 --outfile ~/Documents/LLM/AllowPro-7B-KUJIRA-f16.gguf(オプション) このモデルは十分小さいので量子化は不要ですが、もっと大きなモデルの場合は同じフォルダ内で以下を叩けば量子化できます。また、gguf フォーマットは LM Studio や GPT4All で使えます。
# 8bit 量子化の場合:
./quantize ~/Documents/LLM/AllowPro-7B-KUJIRA-f16.gguf ~/Documents/LLM/AllowPro-7B-KUJIRA-f16-Q8_0.gguf Q8_0
# 4bit でもっとサイズを抑えつつ性能をある程度維持したい場合:
./quantize ~/Documents/LLM/AllowPro-7B-KUJIRA-f16.gguf ~/Documents/LLM/AllowPro-7B-KUJIRA-f16-Q8_0.gguf Q4_K_M(8) Ollama 用モデルファイルを作る
FROM には gguf 変換済みのファイルを指定します。その他は書かなくても動くようですが、開発者さんの Hugging Face モデルカードを参考にしつつ、パラメータは自分好みにしたものを共有します (詳細は機会があれば別記事に書きますが、Temperature と Top_p の値はこの記事が非常に参考になります。Ollama のモデルファイルで指定できる内容はこちらの公式に書かれています)。ArrowPro-7B-KUJIRA であれば結構良い感じだったので、まずはそのまま使っても良いと思います。
FROM ~/Documents/LLM/AllowPro-7B-KUJIRA-f16.gguf
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER top_k 10
SYSTEM """
あなたは日本語を話す優秀なアシスタントです。回答には必ず日本語で答えてください。
"""
TEMPLATE """[INST] <<SYS>>{{ .System }}<</SYS>>
{{ .Prompt }} [/INST]
"""(9) 以下コマンドで Ollama にインストール
create の次の文字列は、自分がわかる名前であれば何でもかまいません。-f の後には上で作ったモデルファイルを指定します。諸々問題無ければ、2分ほどで終わります。
ollama create ArrowPro-7B-KUJIRA-f16.gguf:converted -f ./KUJIRA-ModelFileOllama でのチャットの使い方 (ざっくり紹介)
モデルの一覧確認:
ollama list
# または
ollama ls
# 実行例
NAME ID SIZE MODIFIED
andrewcanis/command-r:q4_0 83ca7e336b1e 20 GB 7 days ago
andrewcanis/command-r:q4_K_M 2ed53f21ba32 21 GB 8 days ago
andrewcanis/command-r:q4_K_S 13357e820ff7 20 GB 29 hours ago
ArrowPro-7B-KUJIRA-f16:converted af58c44c6cf5 14 GB 53 minutes ago
ELYZA-japanese-Llama-2:13b-instruct.Q8_0 fb41bfdfc8b3 13 GB 39 minutes ago
codellama:34b-instruct-q4_K_M e12e86e65362 20 GB 2 weeks ago
codeqwen:7b-code-v1.5-q8_0 f076b41b0d2e 7.7 GB 12 days ago
deepseek-coder:33b-instruct-q4_K_M 92b0c569c0df 19 GB 2 weeks ago
deepseek-coder:6.7b-instruct-q8_0 54b58e32d587 7.2 GB 12 days ago
llama3:8b-instruct-q8_0 5a511385d20f 8.5 GB 2 weeks ago
pxlksr/opencodeinterpreter-ds:33b-Q4_K_M b201938d908f 19 GB 12 days ago 不要なモデルの削除:
ollama rm (モデル名)
# 実行例
ollama rm ELYZA-japanese-Llama-2:13b-instruct.Q8_0モデルを選択したチャットの実行:
ollama run (モデル名)
# 実行例
ollama run ArrowPro-7B-KUJIRA-f16.gguf:converted(チャット中) コマンド一覧:
/?
# 設定できる内容の表示
/? /set
(チャット中) 表示できる各種情報の一覧:
/show
# 実行例、パラメータの表示
/show parameters
Model defined parameters:
stop "<|END_OF_TURN_TOKEN|>"(チャット中) パラメータの設定:
/set parameter 項目 値
# 設定例
/set parameter top_p 0.8
Set parameter 'top_p' to '0.8'(チャット中) これまでのチャットの内容をリセットして新たな話題を始める:
/clear(チャット中) LLM のテキスト生成を止めるキーボードショートカット:
Control + C
(チャット中) チャットの終了:
/byeまとまらない
LLM 関連のニュースや記事をあさっていると様々な情報が毎日の様に飛び交っていて、パラメータ数の小さいものでも性能が高い LLM が登場したり、1bit 量子化で高い性能が発揮できる方法が見つかった (らしい) なんて話もあり、32GB の RAM で十分な世界がやってきそうな感じもあります。Apple は M4 チップをリリースし、来年には Mac にも乗っかってくるでしょう。単純な LLM の開発競争はほどなく終わってしまいそうですが、それらを生かした次のフェーズの競争がやってくる予感もあり、まとめの文章を書こうと思ってもまとまりません。なので、また何か書きます。
Image by Stable Diffusion
realisticVision の新しいモデルが出ていたので使ってみました。キレイですね。クジラがらみの LLM が 2つ登場したのもあり、今回はこんなイメージです。
Date:
2024年5月11日 4:24:52
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
realistic, whale in a swimming pool, swimming with kids
Exclude from Image:
Seed:
184094467
Steps:
35
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
All