

In this Ollama GitHub issue, there are many comments requesting support for the MLX backend, and some even write that it is 20-40% faster than llama.cpp (GGUF). Curious about these comments, I decided to try the MLX version of my favorite QwQ-32B-Preview – QwQ is Alibaba Qwen team’s open reasoning large language model (LLM) similar to OpenAI’s o1, which iteratively improves answer accuracy.
In conclusion, MLX version is indeed slightly faster. The person who wrote the comment mentioned using an M3 Mac, so the difference might be more noticeable on newer Mac models with M4 chips. Since I tried it out, I’ll leave the method here for reference, Dify with MLX-LM as a local LLM model provider.
By the way, is this an official Ollama X post? It could also be interpreted as hinting that Ollama will officially support the MLX backend.
Contents
What’s MLX?
To put it simply, MLX is Apple’s official machine learning framework for Apple Silicon. It can utilize both the GPU and CPU. Although it may not always achieve peak performance, some reports from various experiments show that it can be faster than using PyTorch with MPS in certain cases.
MLX official GitHub: https://ml-explore.github.io/mlx/build/html/index.html
So, when we refer to an “MLX version of LLM,” we are talking about an open large language model (LLM) that has been converted to run using the MLX framework.
What’s MLX-LM?
MLX-LM is an execution environment for large language models (LLMs) that have been converted to run using MLX. In addition to running the models, it also includes features such as converting models from Hugging Face into MLX format and running an API server. This article introduces how to use it as an API server.
MLX-LM official GitHub: https://github.com/ml-explore/mlx-examples/blob/main/llms/README.md
There is also a similar execution environment MLX-VLM, which supports vision models such as Pixtral and Qwen2-VL.
MLX-VLM official GitHub: https://github.com/Blaizzy/mlx-vlm
There is also a Python package FastMLX that can function as an API server for both MLX-LM and MLX-VLM. Functionally, it is quite appealing. However, the vision models only accept image URLs or paths (which makes them unusable with Dify), and text streaming often fails and throws exceptions. It requires a lot of effort to make it work properly, so I have given up for now. If you are interested, give it a try.
FastMLX official GitHub: https://github.com/arcee-ai/fastmlx
You can use LM Studio
LM Studio can use MLX models, so if you don’t need to use Dify or prefer not to, you can stop reading here. Additionally, you can register LM Studio as an OpenAI API-compatible model provider in Dify. However, with LM Studio, responses from the LLM may not stream smoothly. Therefore, if you plan to use MLX LLMs with Dify, it is better to utilize the API server functionality of MLX-LM.
Launch MLX-LM API Server
Install
To use MLX-LM install MLX-LM in your virtual environment. The version I confirmed was the latest, 0.20.4.
pip install mlx-lmStart API Server Once
To set up the server, use the mlx_lm.server command (note that the actual command uses an underscore instead of a dash as installed). If Dify or other API clients are running on different hosts or if other servers are using the port, you can specify options as shown in the example below. In my case, Dify is running on another Mac and there’s also a text-to-speech server running on my main Mac, so I specify each accordingly. For more details on the options, check mlx_lm --help. The --log-level option is optional.
mlx_lm.server --host 0.0.0.0 --port 8585 --log-level INFOThe server must be running when you see something like below:
% mlx_lm.server --host 0.0.0.0 --port 8585 --log-level INFO
/Users/handsome/Documents/Python/FastMLX/.venv/lib/python3.11/site-packages/mlx_lm/server.py:682: UserWarning: mlx_lm.server is not recommended for production as it only implements basic security checks.
warnings.warn(
2024-12-15 21:33:25,338 - INFO - Starting httpd at 0.0.0.0 on port 8585...Download LLM
I selected the 4-bit quantized model of QwQ (18.44GB) because it must fit in 32GB of RAM.
HuggingFace: https://huggingface.co/mlx-community/QwQ-32B-Preview-4bit
Open another terminal window while the MLX-LM server is running, write and save a simple script like the one below, and then run it with Python to download the model.
import requests
url = "http://localhost:8585/v1/models"
params = {
"model_name": "mlx-community/QwQ-32B-Preview-4bit",
}
response = requests.post(url, params=params)
print(response.json())python add_models.pyOnce the download is complete, you can stop the server by pressing Ctrl + C. By the way, the model downloaded using this method can also be loaded by LM Studio. If you want to try both applications, downloading via command line will help reduce storage space (although the folder names become non-human friendly in LM Studio).
Start API Server with a LLM
The model is saved in ~/.cache/huggingface/hub/, and for this example, it will be in the folder models--mlx-community--QwQ-32B-Preview-4bit. The path passed to the server command needs to go deeper into the snapshot directory where the config.json file is located.
The command to start the API server would look like this:
mlx_lm.server --host 0.0.0.0 --port 8585 --model /Users/handsome/.cache/huggingface/hub/models--mlx-community--QwQ-32B-Preview-4bit/snapshots/e3bdc9322cb82a5f92c7277953f30764e8897f85Once the server starts, you can confirm installed models by navigating to: http://localhost:8585/v1/models
{"object": "list", "data": [{"id": "mlx-community/QwQ-32B-Preview-4bit", "object": "model", "created": 1734266953}
Register in Dify
Add as an OpenAI-API Compatible Model
To register the model in Dify, you will add it as an OpenAI-API-compatible LLM model. The model name is the one mentioned frequently above. The URL needs to include the port number and /v1, and you can use something like \n\n for the Delimiter.
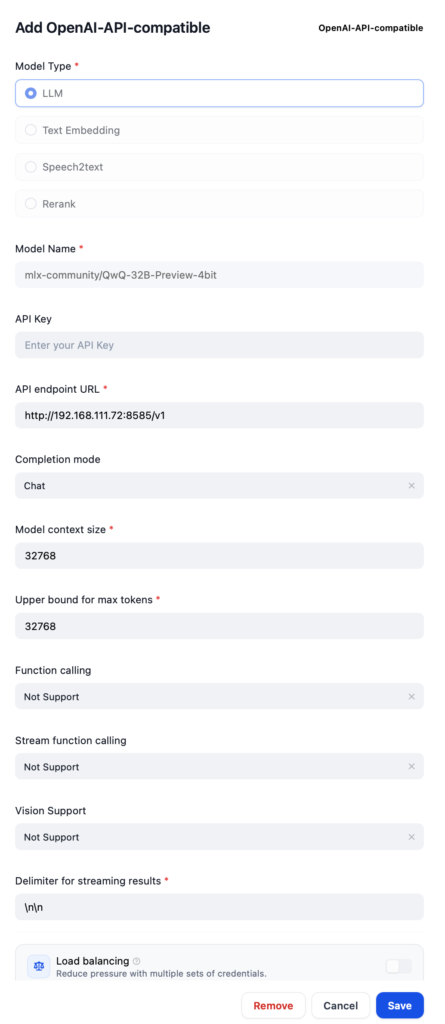
Create a Chatbot
When creating a Chatbot Chatflow, select the model you just added with 4096 for the Max Tokens. This size fits in 32GB RAM and runs 100% on GPU. To avoid getting answers in Chinese, try the sample System prompt below. QwQ may still use some Chinese sentences from time to time though.
Never ever use Chinese. Always answer in English or language used to ask.
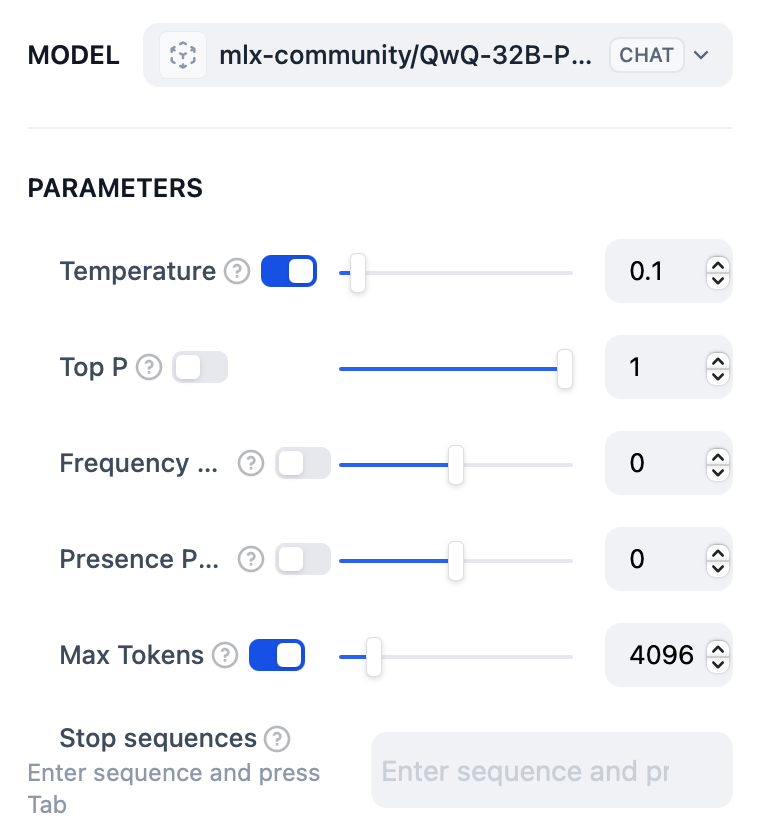
That’s about it. Enjoy the speed of MLX version of your LLM.
Dify judged MLX was the winner
Now that everything is set up, I created chatbots using the same conditions with both GGUF (ollama pull qwq:32b-preview-q4_K_M) and MLX. The settings were as follows: Temperature=0.1, Size of context window=4096, Keep Alive=30m, with all other settings at their default values. I asked seven different types of questions to see the differences.
Based on Dify’s Monitoring, it seems that the MLX version was 30-50% faster. However, in practical use, I didn’t really notice a significant difference; both seemed sufficiently fast to me. Additionally, the performance gap tended to be more noticeable with larger amounts of generated text. In this test, MLX produced more text before reaching an answer, which might have influenced the results positively for MLX. The nature of the QwQ model may also have contributed to these favorable outcomes.
Overall, it’s reasonable to say that MLX is about 30% faster than GGUF, without exaggeration. First image below is MLX and the next one is GGUF.
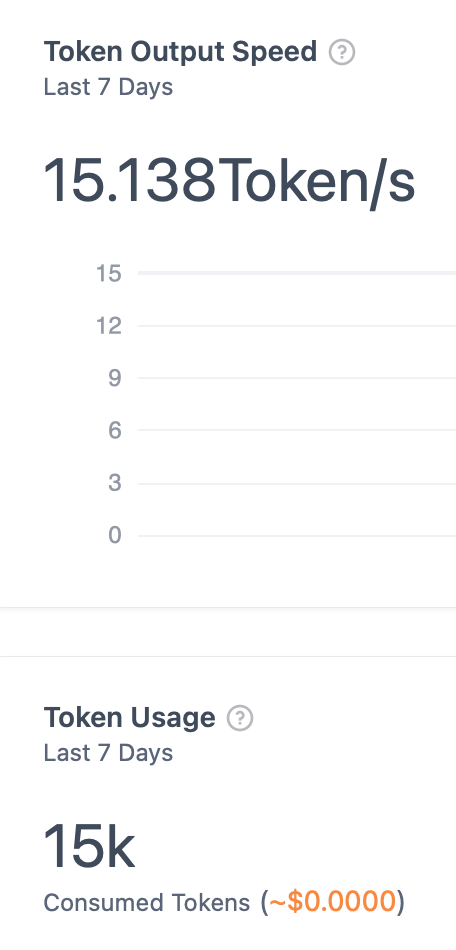
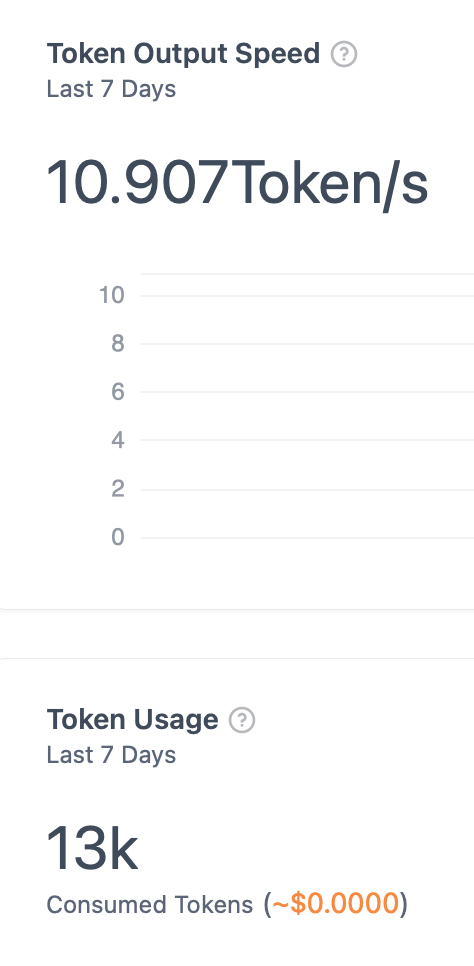
Prompts I used for performance testing:
(1) Math:
I would like to revisit and learn calculus (differential and integral) now that I am an adult. Could you teach me the basics?
(2) Finance and documentation:
I would like to create a clear explanation of a balance sheet. First, identify the key elements that need to be communicated. Next, consider the points where beginners might make mistakes. Then, create the explanation, and finally, review the weak points of the explanation to produce a final version.
(3) Quantum biology:
Explain photosynthesis in quantum biology using equations.
(4) Python scripting:
Please write a Python script to generate a perfect maze. Use "#" for walls and " " (space) for floors. Add an "S" at the top-left floor as the start and a "G" at the bottom-right floor as the goal. Surround the entire maze with walls.
(5) Knowledge:
Please output the accurate rules for the board game Othello (Reversi).
(6) Planning:
You are an excellent web campaign marketer. Please come up with a "Fall Reading Campaign" idea that will encourage people to share on social media.
### Constraints
- The campaign should be easy for everyone to participate in.
- Participants must post using a specific hashtag.
- The content should be engaging enough that when others read the posts, they want to mention or create their own posts.
- This should be an organic buzz campaign without paid advertising.
(7) Logic puzzle:
Among A to D, three are honest and one is a liar. Who is the liar?
A: D is lying.
B: I am not lying.
C: A is not lying.
D: B is lying.
Can MLX-LM Replace Ollama?
If you plan to stick with a single LLM, I think MLX-LM is fine. However, in terms of ease of use and convenience, Ollama is clearly superior, so it may not be ideal for those who frequently switch between multiple models. FastMLX, which was mentioned earlier, allows model switching from the client side, so it could be a viable option if you are seriously considering migrating. That said, based on what seems to be an official X post from Ollama, they might eventually support MLX, so I’m inclined to wait for that.
Regardless, this goes slightly off the original GGUF vs MLX comparison, but personally, I find QwQ’s output speed sufficient for chat-based applications. It’s smart as well (I prefer Qwen2.5 Coder for coding, though). Try it out if you haven’t.
Oh, by the way, most of this post was translated by QwQ from Japanese. Isn’t that great?
Image by Stable Diffusion (Mochi Diffusion)
When I asked images of “a robot running on a big apple”, most of them had robot in NYC. Yeah, sure. Simply ran several attempts and picked one looked the best. If the model learned from old school Japanese anime and manga, I could get something closer to my expectation.
Date:
2024-12-16 0:38:20
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
fancy illustration, comic style, smart robot running on a huge apple
Exclude from Image:
Seed:
2791567837
Steps:
26
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
CPU & GPU