

Recently, the performance of open-source and open-weight LLMs has been amazing, and for coding assistance, DeepSeek Coder V2 Lite Instruct (16B) is sufficient, while for Japanese and English chat or translation, Llama 3.1 Instruct (8B) is enough. When running Ollama from the Terminal app and chatting, the generated text and response speed are truly surprising, making it feel like you can live without the internet for a while.
However, when using the same model through Dify or Visual Studio Code’s LLM extension Continue, you may notice the response speed becomes extremely slow. In this post, I will introduce a solution to this problem. Your problem may be caused by something else, but since it is easy to check and fix, I recommend checking the Conclusion section of this post.
Confirmed Environment
OS and app versions:
macOS: 14.5
Ollama: 0.3.8
Dify: 0.6.15
Visual Studio Code - Insiders: 1.93.0-insider
Continue: 0.8.47LLM and size
| Model name | Model size | Context length | Ollama download command |
| llama3.1:8b-instruct-fp16 | 16 GB | 131072 | ollama pull llama3.1:8b-instruct-fp16 |
| deepseek-coder-v2:16b-lite-instruct-q8_0 | 16 GB | 163840 | ollama run deepseek-coder-v2:16b-lite-instruct-q8_0 |
| deepseek-coder-v2:16b-lite-instruct-q6_K | 14 GB | 163840 | ollama pull deepseek-coder-v2:16b-lite-instruct-q6_K |
Conclusion
Check the context length and lower it.
By setting “Size of context window” in Dify or Continue to a sufficiently small value, you can solve this problem. Don’t set a number just because the model supports it or for future use; instead, use the default value (2048) or 4096 and test chatting with a small number of words. If you get a response as you expect, congrats, the issue is resolved.
Context size: It is also called "context window" or "context length." It represents the total number of tokens that an LLM can process in one interaction. Token count is approximately equal to word count in English and other supported languages. In the table above, Llama 3.1 has a context size of 131072, so it can handle approximately 65,536 words text as input and output.
Changing Context Length
Dify
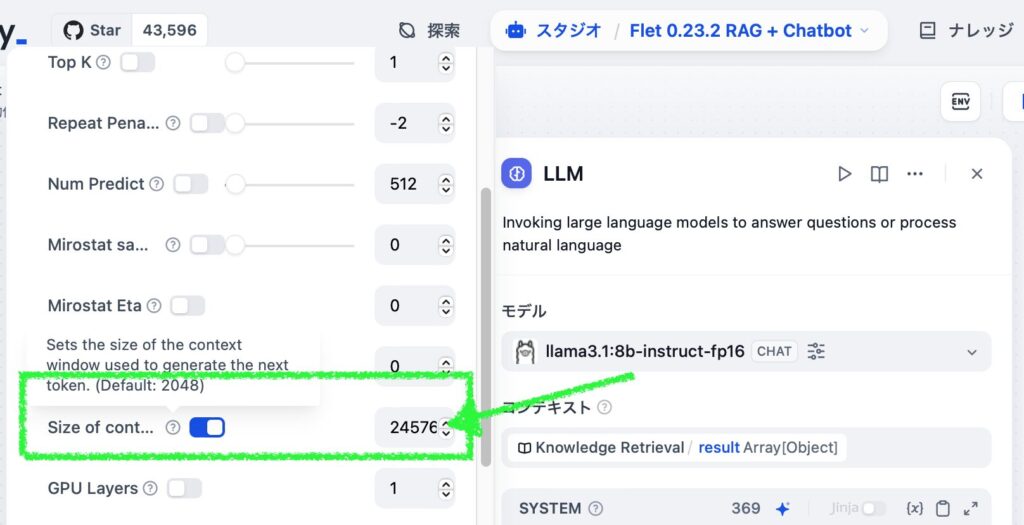
- Open the LLM block in the studio app and click on the model name to access detailed settings.
- Scroll down to find “Size of cont…” (Size of content window) and uncheck it or enter 4096.
- The default value is 2048 when unchecked.
Continue (VS Code LLM extension)
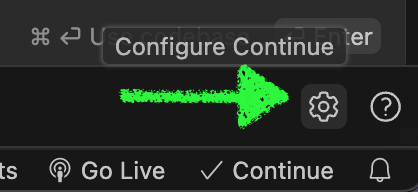
- Open the config.json file in the Continue pane’s gear icon.
- Change the
contextLengthandmaxTokensvalues to4096and2048, respectively. Note thatmaxTokensis the maximum number of tokens generated by the LLM, so we set it half.
{
"title": "Chat: llama3.1:8b-instruct-fp16",
"provider": "ollama",
"model": "llama3.1:8b-instruct-fp16",
"apiBase": "http://localhost:11434",
"contextLength": 4096,
"completionOptions": {
"temperature": 0.5,
"top_p": "0.5",
"top_k": "40",
"maxTokens": 2048,
"keepAlive": 3600
}
}Checking Context Length of LLM
The easiest way is to use the Ollama’s command ollama show <modelname> to display the context length. Example:
% ollama show llama3.1:8b-instruct-fp16
Model
arch llama
parameters 8.0B
quantization F16
context length 131072
embedding length 4096
Parameters
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024Context Length in App Settings
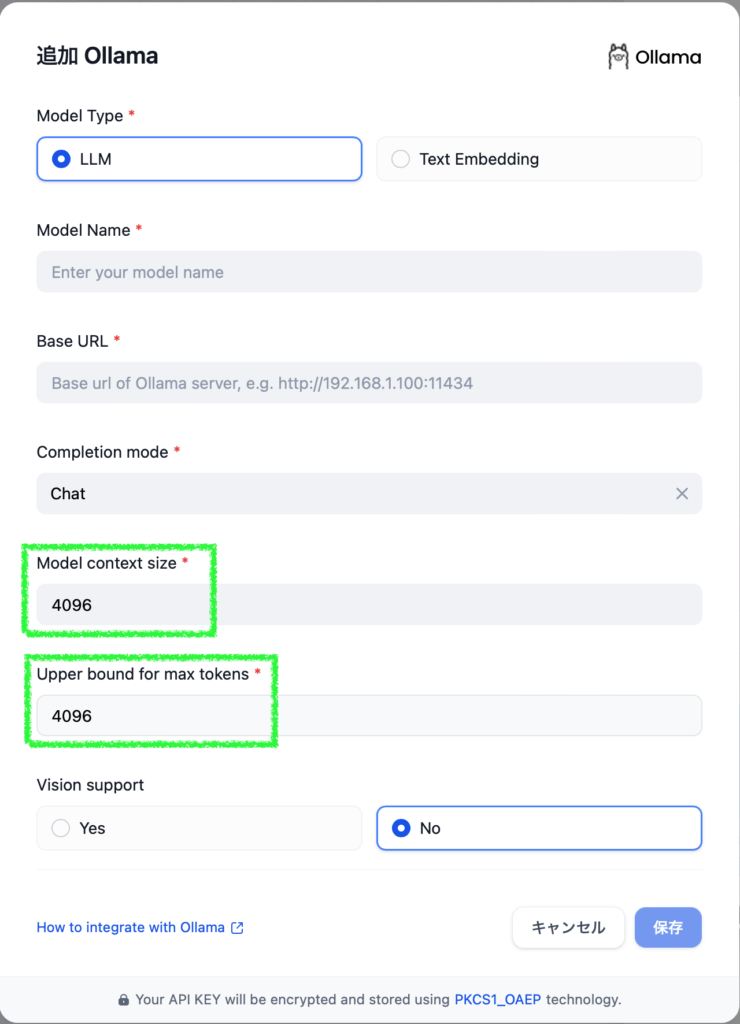
Dify > Model Provider > Ollama
When adding an Ollama model to Dify, you can override the default value of 4096 for Model context length and Upper bound for max tokens. Since setting a upper limit may make debugging difficult if issues arise, it’s better to set both values to the model’s context length and adjust the Size of content window in individual AI apps.
Continue > “models”
In the “models” section of the config.json, you can add multiple settings for different context length by including a description like “Fastest Max Size” or “4096“. For example, I set the title to “Chat: llama3.1:8b-instruct-fp16 (Fastest Max Size)” and changed the contextLength value to 24576 and maxTokens value to 12288. This combination was the highest that I confirmed working perfectly on my Mac with 32 GB RAM.
{
"title": "Chat: llama3.1:8b-instruct-fp16 (Fastest Max Size)",
"provider": "ollama",
"model": "llama3.1:8b-instruct-fp16",
"apiBase": "http://localhost:11434",
"contextLength": 24576,
"completionOptions": {
"temperature": 0.5,
"top_p": "0.5",
"top_k": "40",
"maxTokens": 12288,
"keepAlive": 3600
}
}What’s happening when LLM processing is slow (based on what I see)
When using ollama run, LLM runs quickly, but when using Ollama through Dify or Continue, it becomes slow due to large size of context length. Let’s check the process with ollama ps. Below are examples – first one had the max context length 131072 and the second one had 24576:
% ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b-instruct-fp16 a8f4d8643bb2 49 GB 54%/46% CPU/GPU 59 minutes from now
% ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b-instruct-fp16 a8f4d8643bb2 17 GB 100% GPU 4 minutes from nowIn the slow case, SIZE is much larger than the actual model size (16 GB), and processing occurs on CPU at 54% and GPU at 46%. It seems that Ollama processes LLM as a larger size model when a large size context length is passed via API regardless of the actual number of tokens being processed. This is only my assumption, but the above tells.
Finding a suitable size of context length
After understanding the situation, let’s take countermeasures. If you can live with 4096 tokens, it’s fine, but I want to process as many tokens as possible. Unfortunately, I couldn’t find Ollama’s specifications, so I tried adjusting the context length by hand and found that a value of 24576 (4096*6) works for Llama 3.1 8B F16 and DeepSeek-Coder-V2-Lite-Instruct Q6_K.
Note that using non-multiple-of-4096 values may cause character corruption, so be careful. Also, when using Dify, the SIZE value will be smaller than in Continue.
Ollama, I’m sorry (you can skip this)
I thought Ollama’s server processing was malfunctioning because LLM ran quickly when running on CLI but became slow when used through API. However, after trying an advice “Try setting context length to 4096” from an issue discussion about Windows + GPU, I found that it actually solved the problem.
Ollama, I’m sorry for doubting you!
Image by Stable Diffusion (Mochi Diffusion)
This time I wanted an image of a small bike overtaking a luxurious van or camper, but it wasn’t as easy as I thought somehow. Most of generated images had two bikes, a bike and a van on reversing lanes, a van cut off of the sight, etc. Only this one had a bike leading a van.
Date:
2024-9-1 2:57:00
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
A high-speed motorcycle overtaking a luxurious van
Exclude from Image:
Seed:
2448773039
Steps:
20
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
All