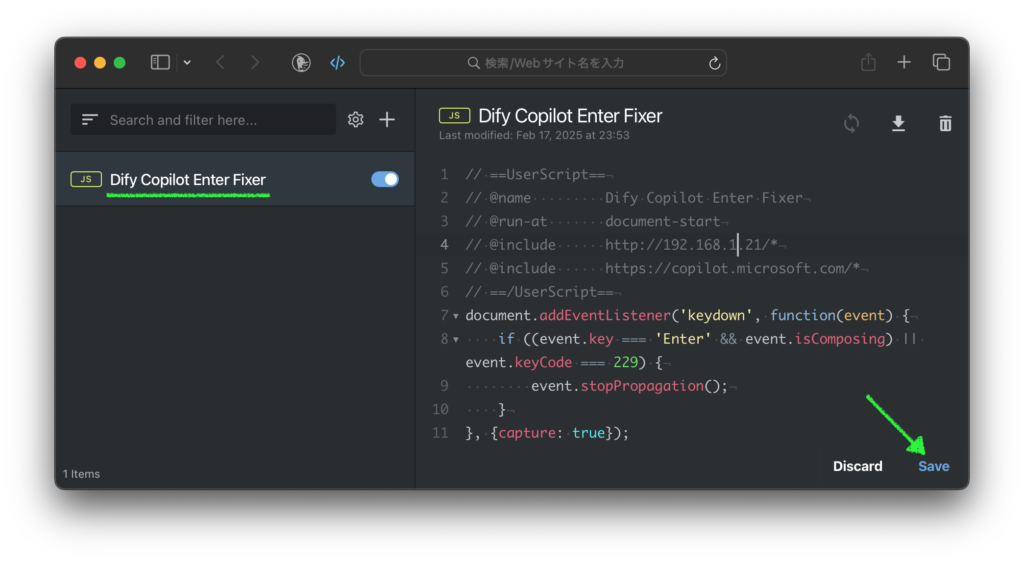
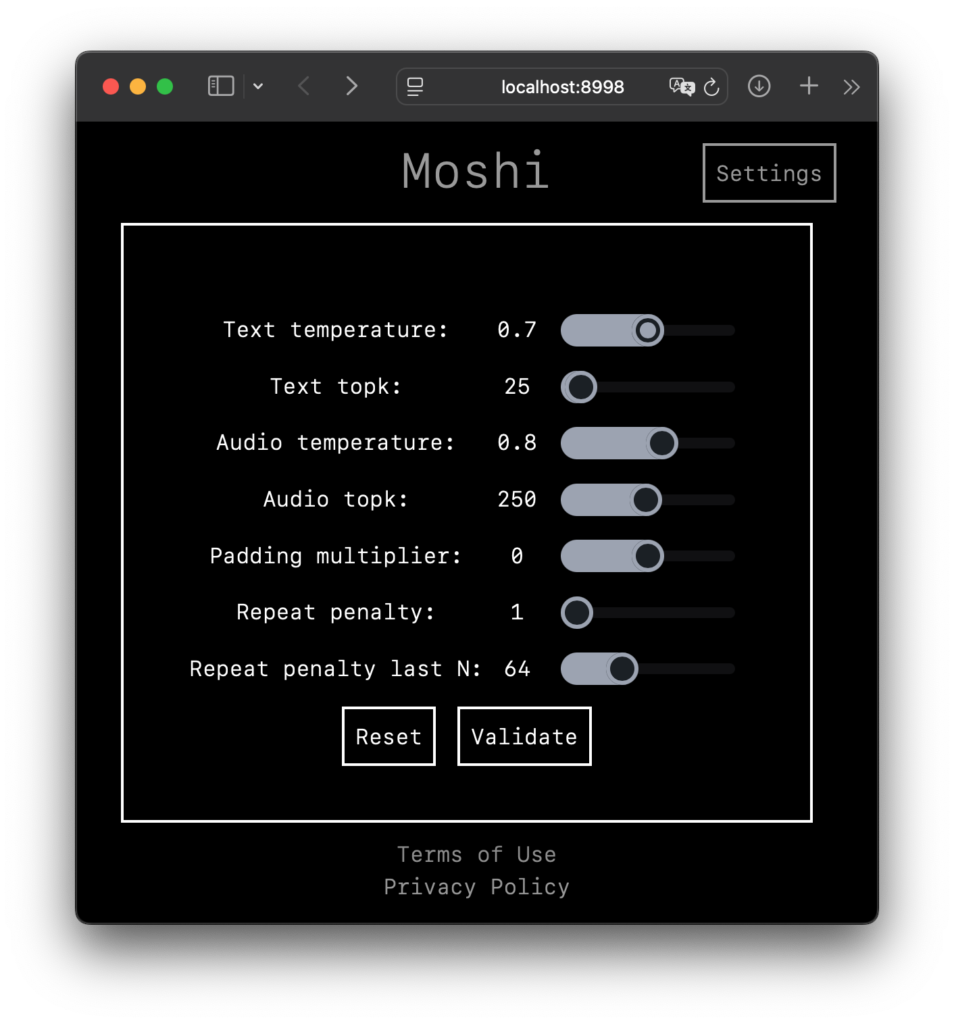
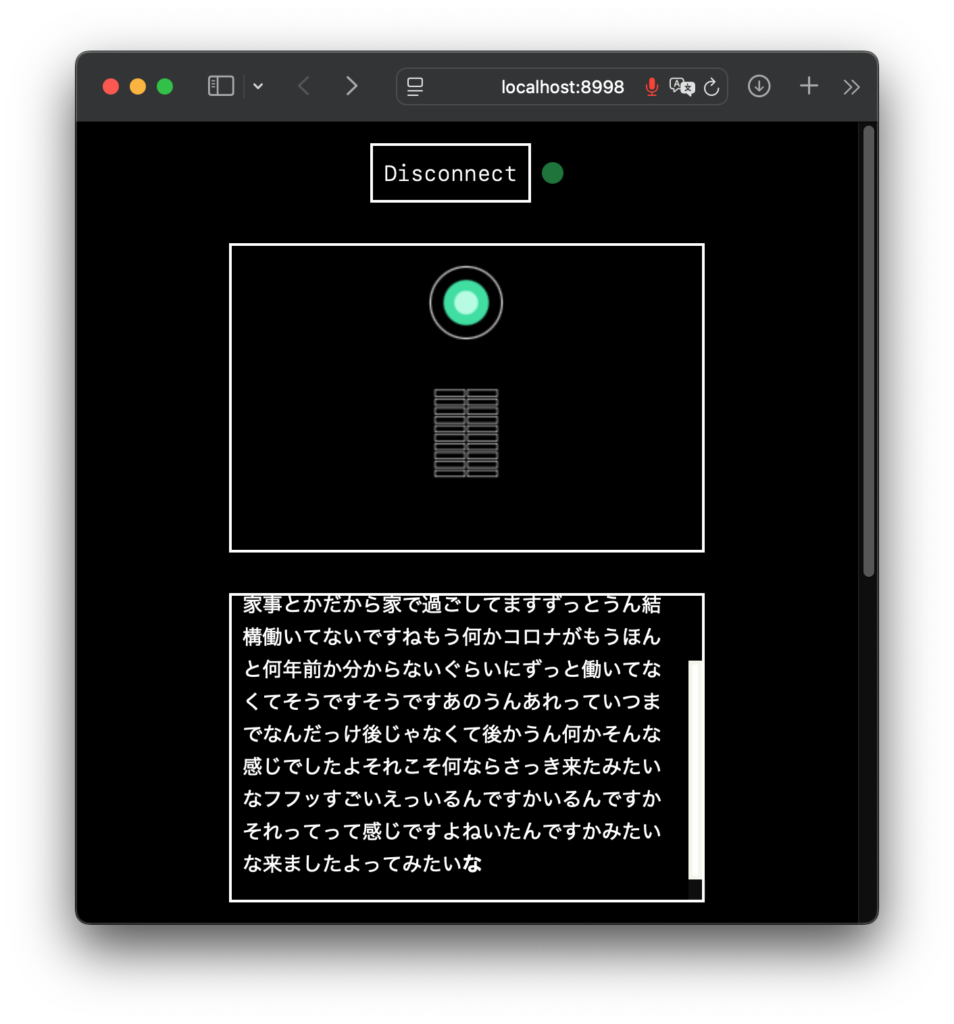
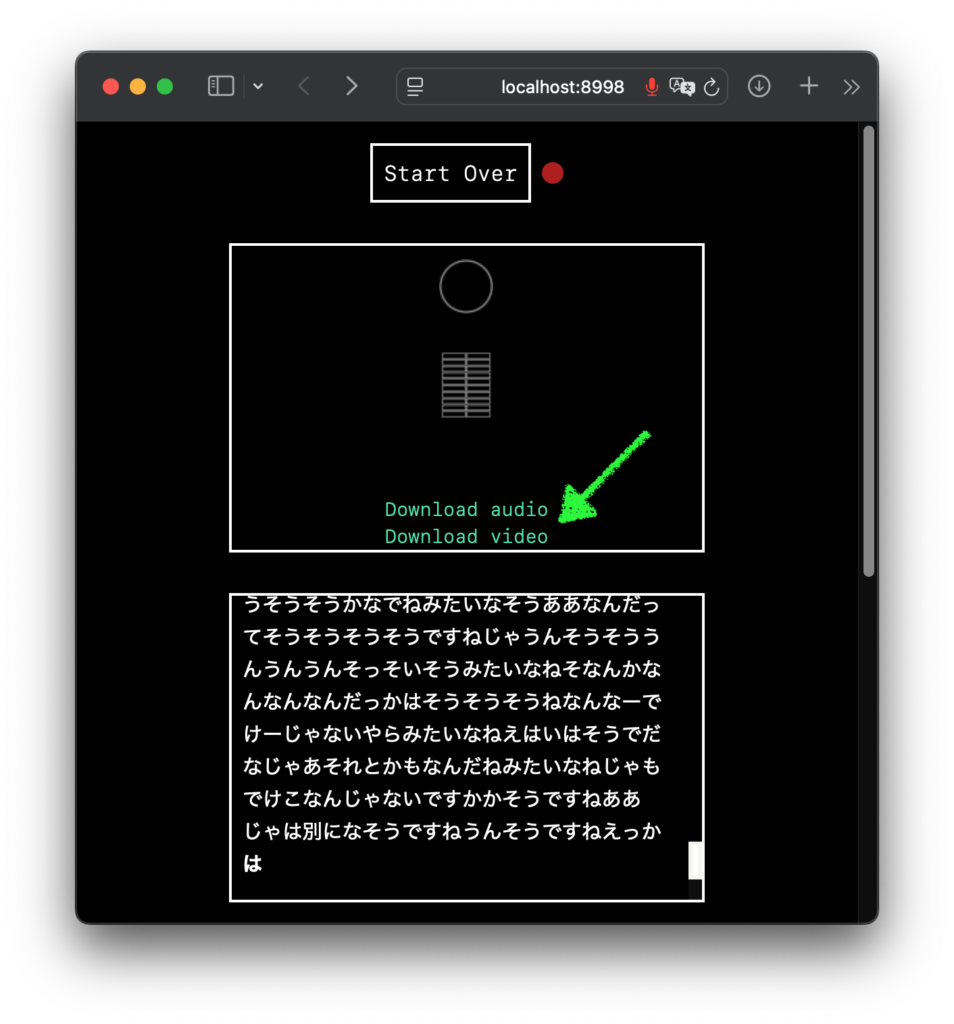
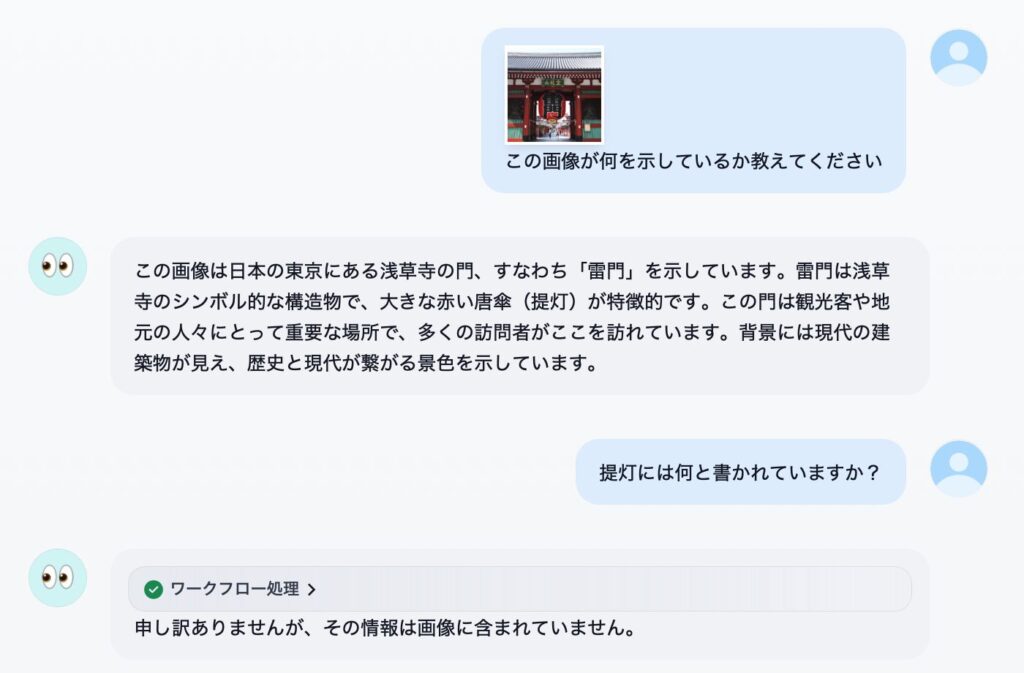
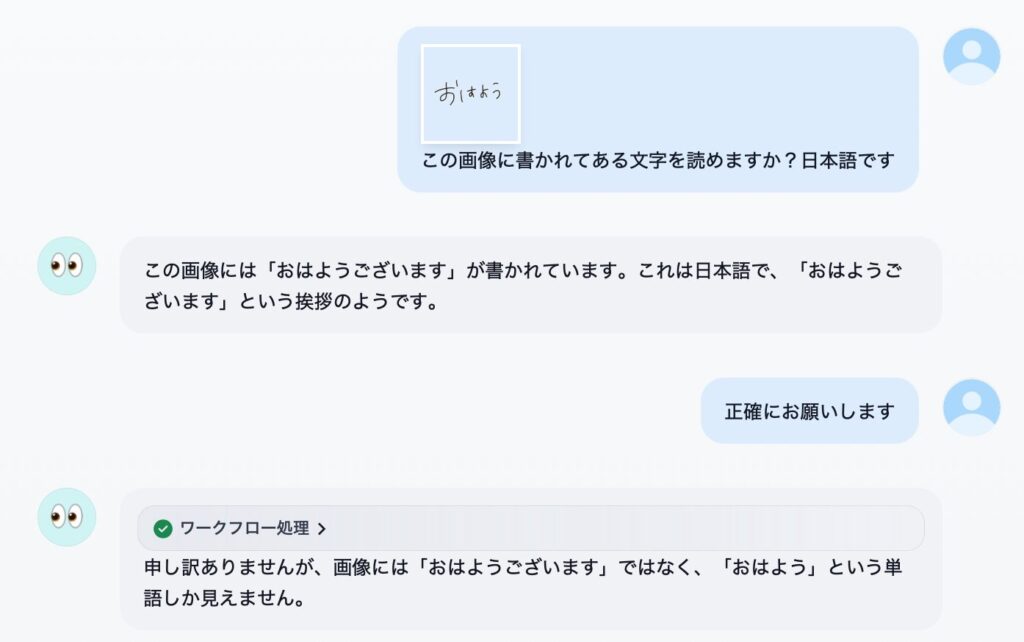
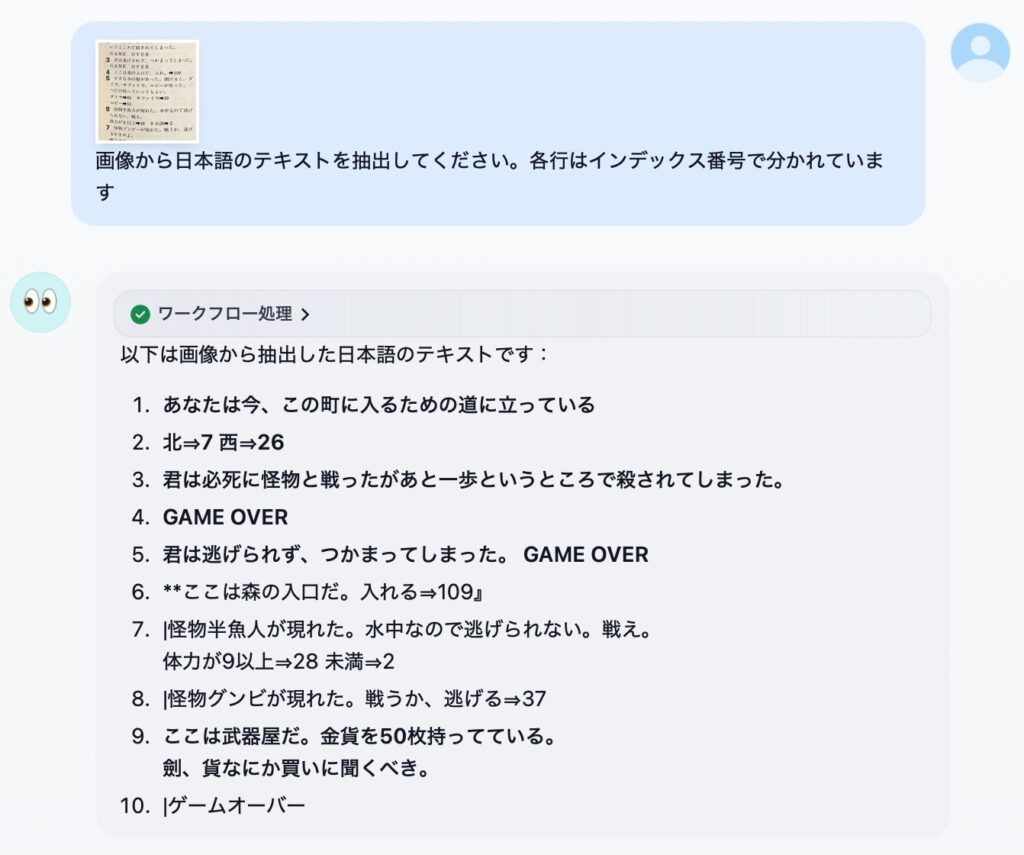
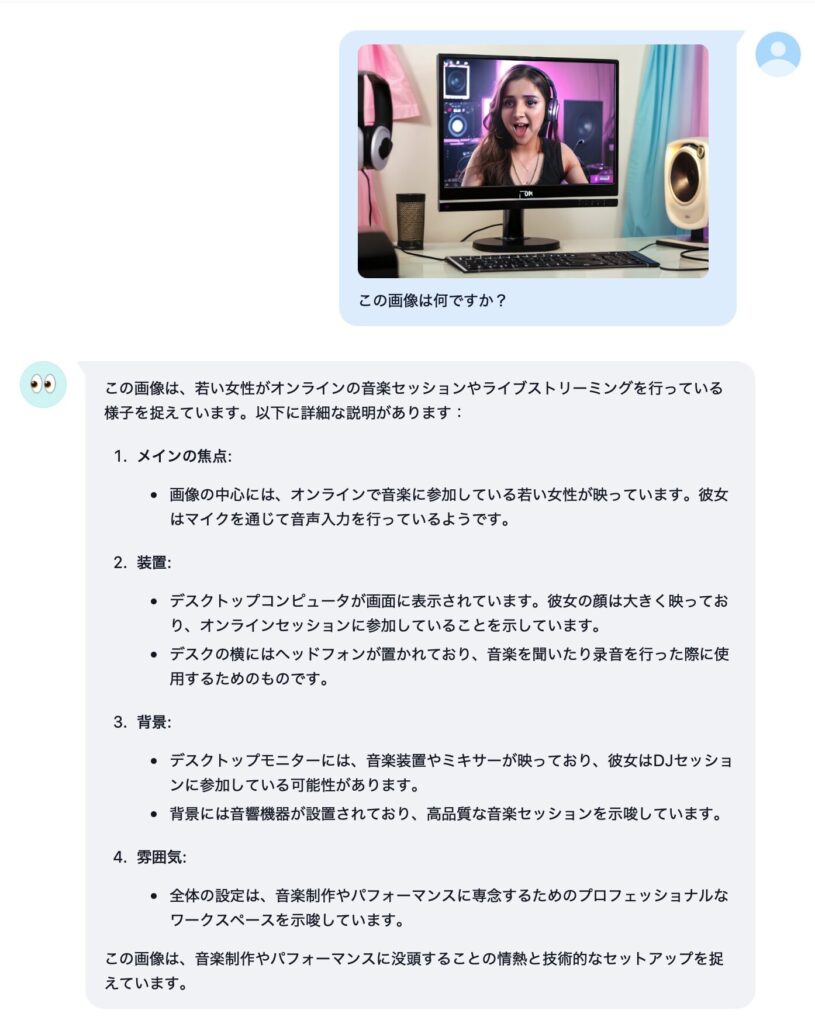
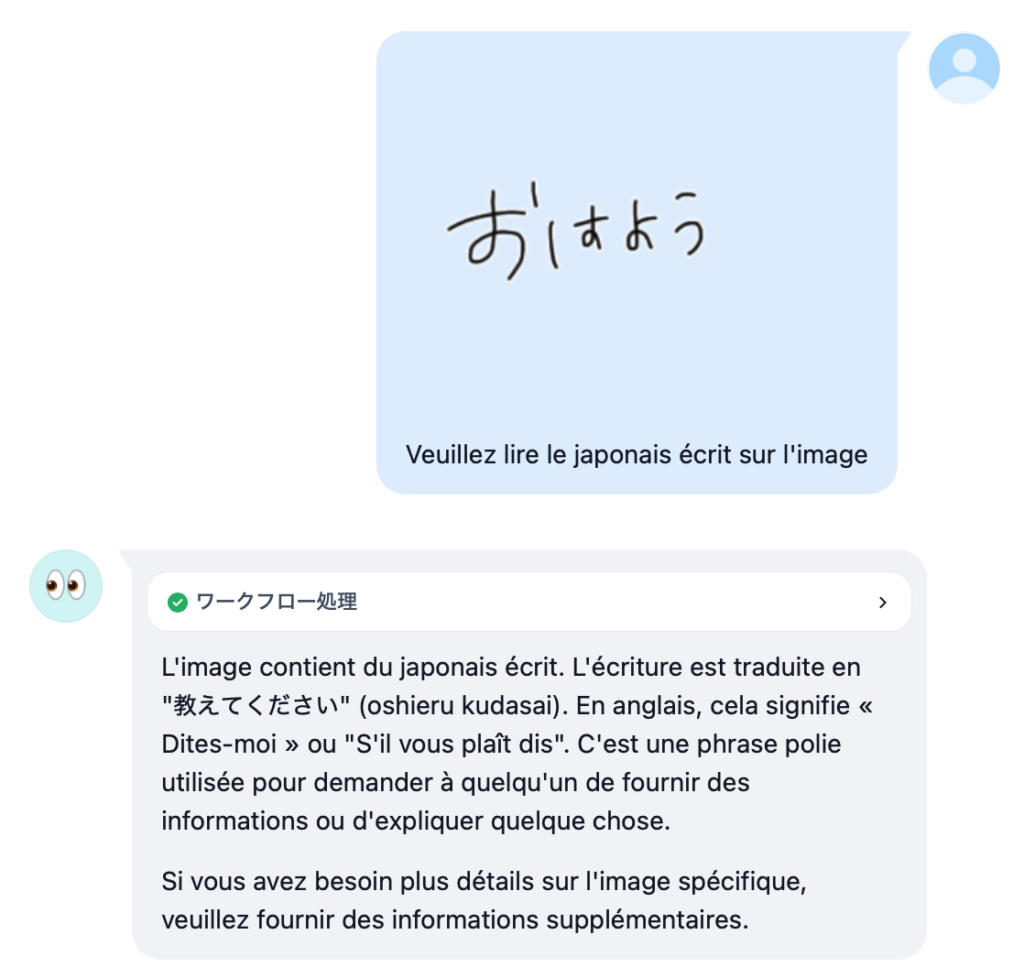
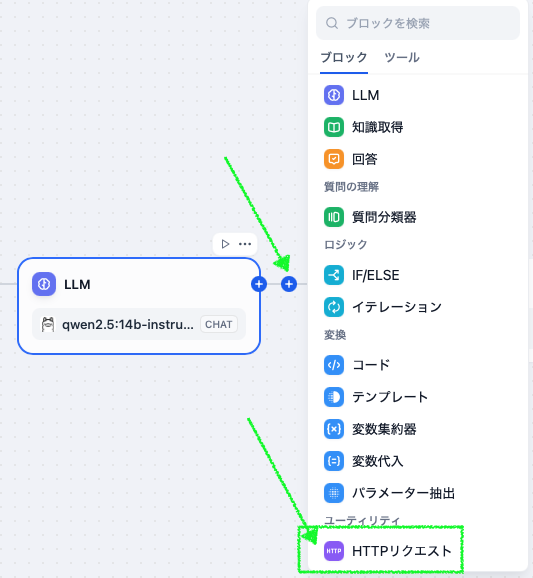
「絶対やって!」とかこれまで書かないようにしてきたんですが、これはムリ。すごすぎる。オモシロ楽しすぎる。というわけで、名古屋大学さんが真面目に作られた (日本語に改良された) Full-duplex音声対話システム、「J-Moshi」のご紹介と Mac ローカルでの使い方の解説です。まずは公式にアップされているサンプルをいくつか聞いてください。
ね?どうですかこの、テキトーに話を合わせて会話をする、まーまー年齢が上っぽい普通のお姉さん AI のコミュ力の高さ!ナチュラルさ!お互いのしゃべりが重なっても話し続ける体幹の強さ (全二重)!真面目に研究されたであろう最先端 AI による抜群のノリの軽さ!もう最高!これが自宅の Mac で実現できる!いやー、もう一度書いてしまう、絶対やって!
ボクが初めて生成 AI をいじった時って、使い方がわからないから「西野七瀬ちゃんが乃木坂を卒業した理由を教えて」とか聞いてみたんですね。すると「音楽性の不一致です。その後アーティストとして独立し、先日ファーストシングルを発表しました」とか言われて、なんだこりゃ生成 AI って使えねーじゃん、と思ってしまいました。で、その経験をふまえて音声で会話ができるこの J-Moshi はどうなのかと言うと、むしろ AI のテキトーさが楽しく、さらに音声品質の高さと相まって普通に受け入れてしまいました。っていうか、いっぺんに好きになっちゃいました!
少し話はそれますが、今日の日中は仕事で調べたいことがあったので、インストールしたもののあんまり使っていなかった DeepSeek-R1:32B に気まぐれで色々と Nginx 関連の相談してみました。その結果回答精度の高さに感心し、もはや Reasoning モデル以外のモデルは使えないと感じてしまいました。せっかく買った深津さんのプロンプト読本で書かれている、それまでは常識だった「生成 AI は、次に来そうな文章を確率で答えるマシン」を超えてしまっているんですね。ほんの数ヶ月しか経っていないのに。
で、同じ日の夜に試した J-Moshi ですが、改めて AI の進歩の速さに驚き、それまでの王道やスタンダード、ベストプラクティス、パラダイムその他もろもろが一瞬で過去のものになる感覚を体感しました。M1 Mac が登場した時にリアルタイムに世の中が変わるのを肌で感じた、あの感覚の再来です。
もうほんと、M シリーズの Mac をお持ちでしたら、ゼヒやってみてください。実質タダだ (電気代以外かからない) し、実用性はどうかわかりませんがとにかく楽しいですよ!(真面目に考えたら実用性も色々ありそうです)
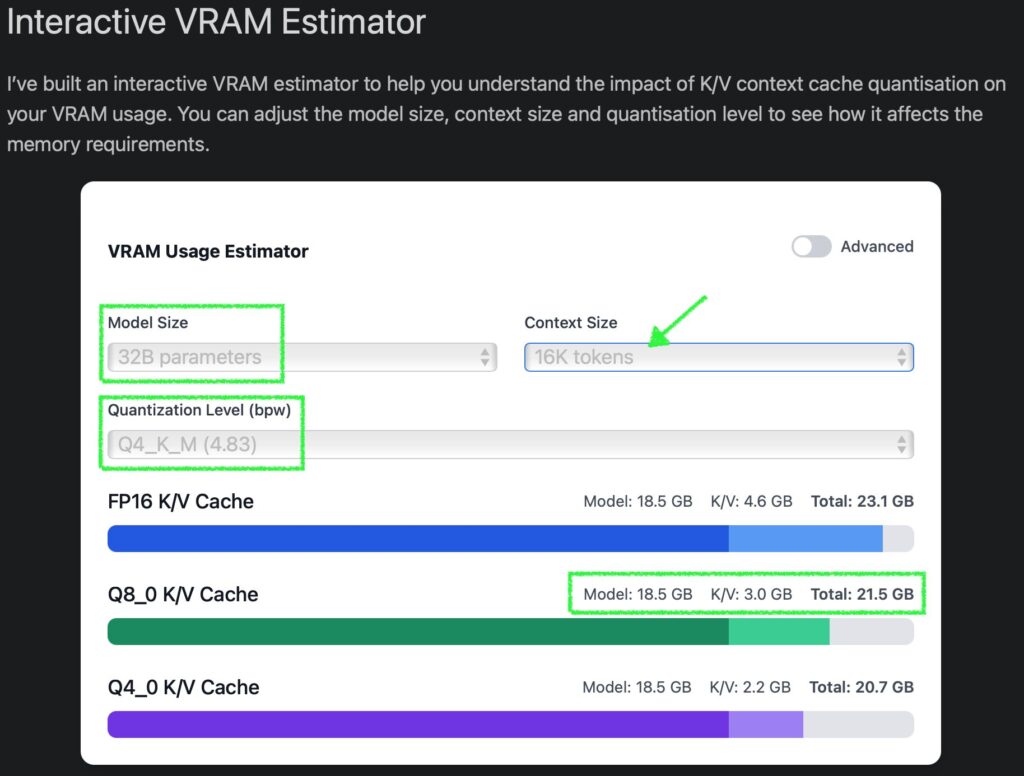
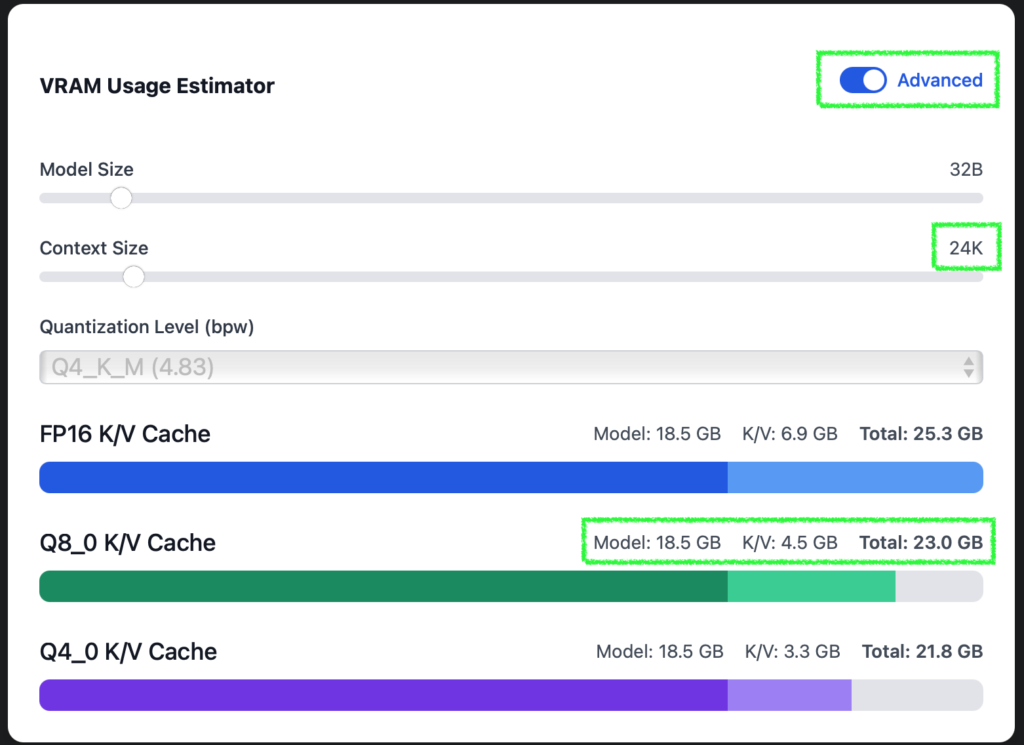
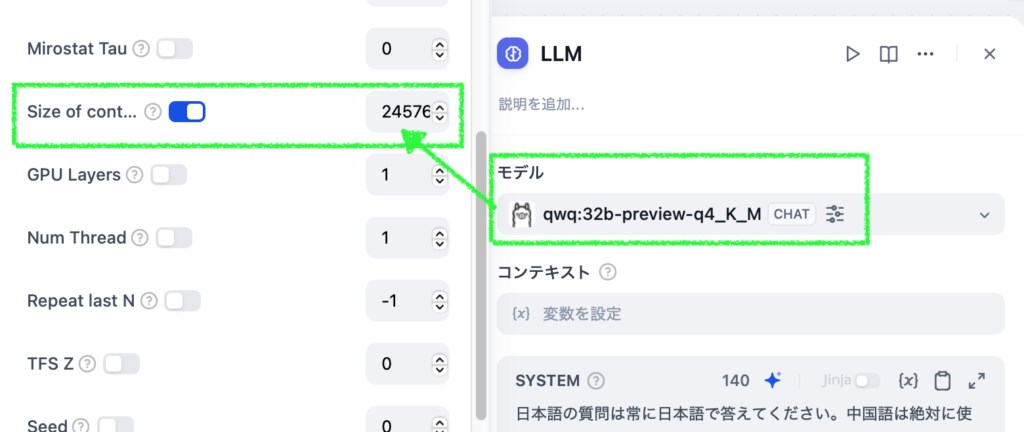
ローカル LLM を使用する際、基本的には Apple Silicon Mac に搭載されているユニファイドメモリの容量から、動かせるモデルのパラメータサイズと量子化サイズ、そして使えるコンテキスト長の組み合わせが決まってきます。この記事では少し深い設定によって「決まっている」制限を超え、ローカル LLM の処理速度と利用できるコンテキスト長を最適化する方法を共有します。お持ちの Mac に搭載されているユニファイドメモリのサイズが大きければ、複数の LLM を動かすとか、これまで実行がきびしかった大きめの (=性能が高い) モデルを動かすということも可能になります。
生成 AI モデルのファインチューニングは素人には手が出せませんが、「環境のファインチューニング」なので、簡単に試してしてすぐに結果が確認できます。基本的なところからカバーしますので、初心者の方も気になれば読んでみてください。
まずは自分の Mac で使えるモデルのサイズを知ろう
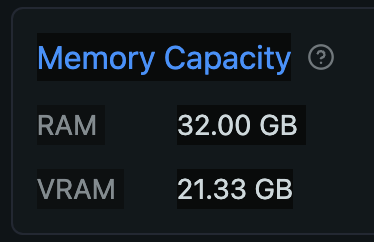
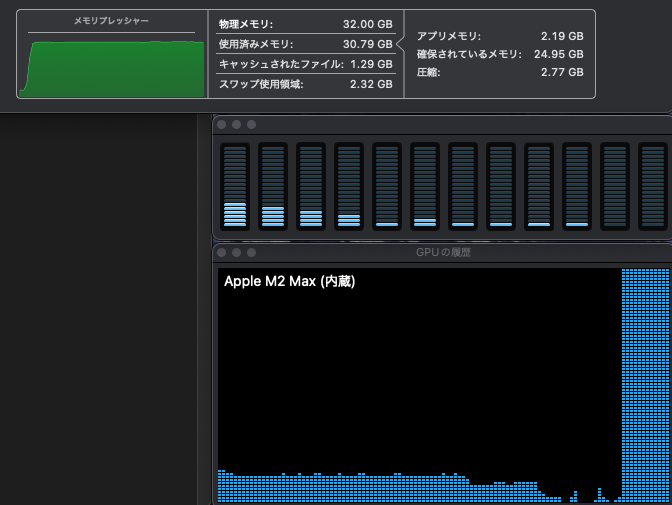
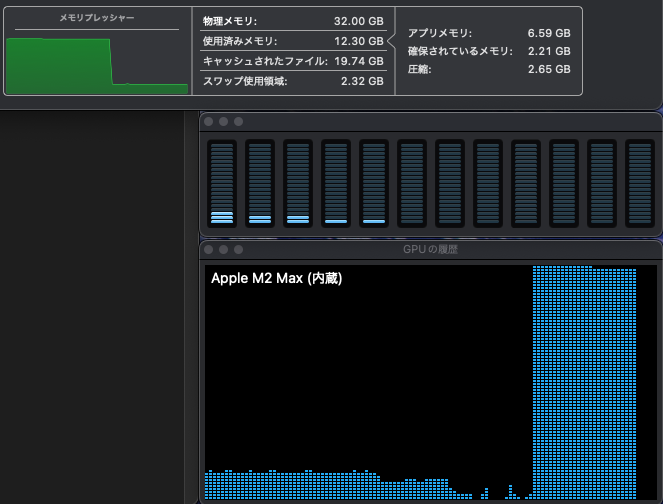
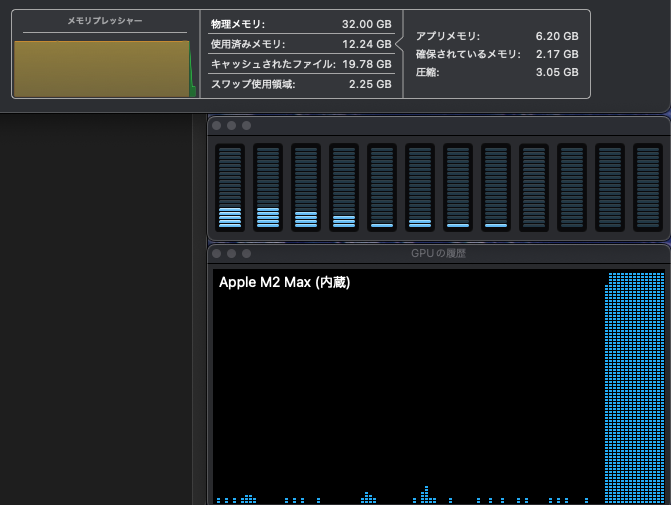
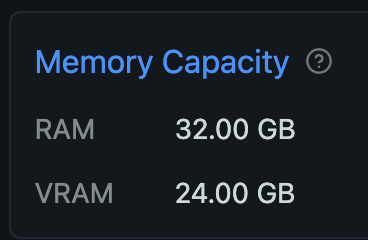
Mac のユニファイドメモリは CPU と GPU それぞれからアクセスできますが、GPU が使える割合は決まっています。海外の掲示板などの書き込みをいくつか見た限り、設定変更をしていなければ 64GB 以上のユニファイドメモリならその 3/4 (75%)、64GB 未満なら 2/3 (約 66%) までは GPU から利用できるようです (以降、ユニファイドメモリを RAM と表記します)。ボクの Mac は 32GB RAM を搭載しているので、21.33GB までを GPU が利用できる計算です。LM Studio がインストールされていれば、ハードウェアリソースの確認画面 (Command + Shift + H) で、VRAM がこの値を示しているのがわかります。
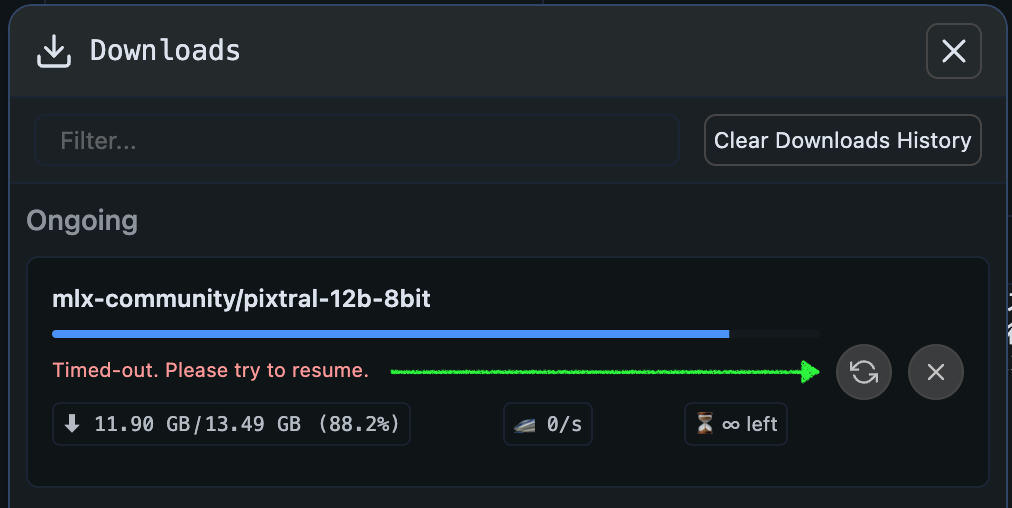
LM Studio でモデルをダウンロードするときに赤く Likely too large と書かれていれば、VRAM 容量に対してそのモデルが大きすぎることを教えてくれています。以下のスクショは、DeepSeek R1 のパラメータサイズ 70B、8bit 量子化 MLX 形式のモデルが 74.98GB なので、あなたの環境ではきびしいですよ、と教えてくれているわけです。
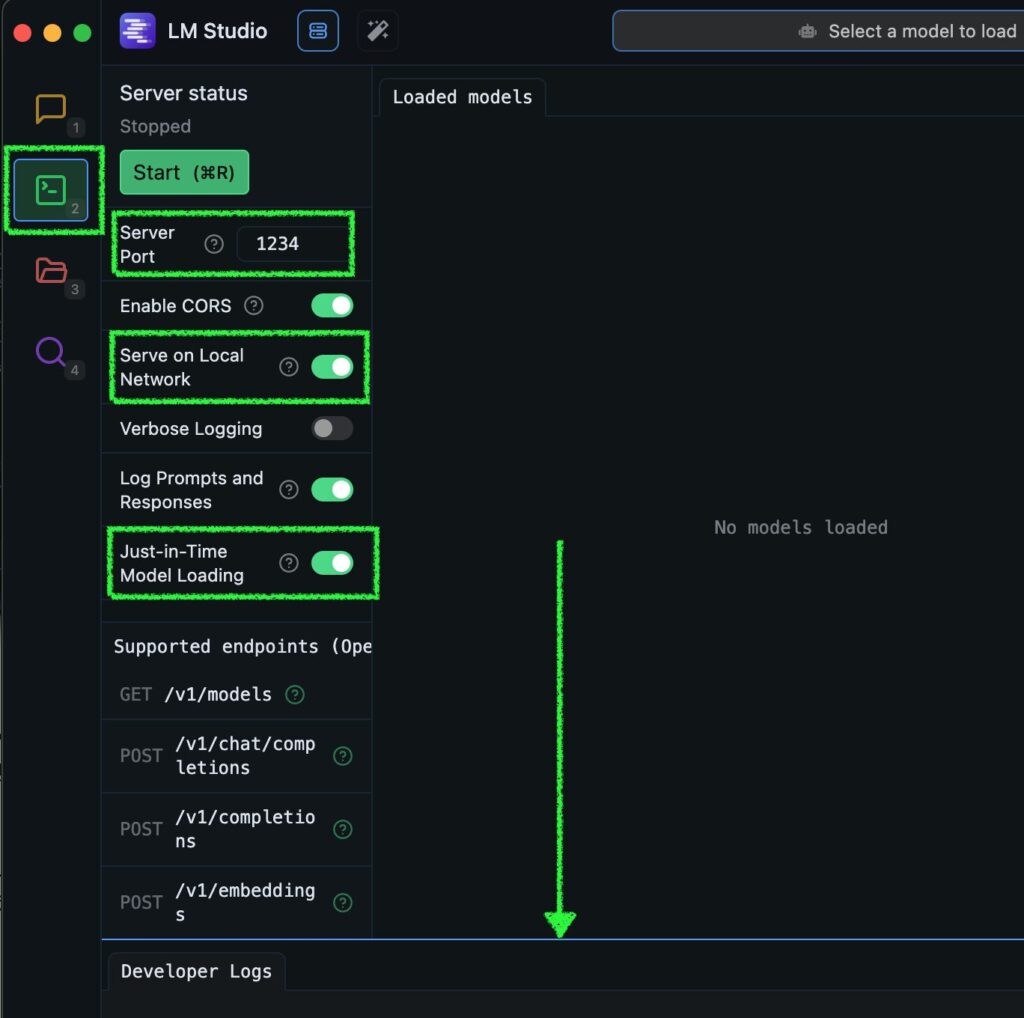
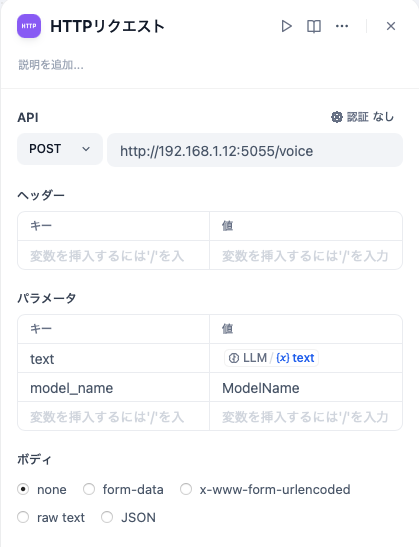
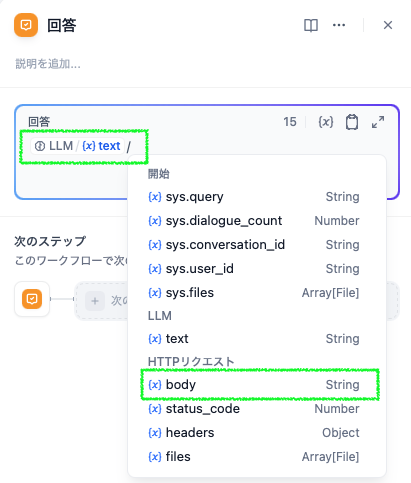
サーバを立てるにはmlx_lm.serverコマンドを使用します (実コマンドはインストール時のハイフンと違いアンダースコアなので注意)。Dify (や他の API クライアント) が別のホストで動いているとか、他のサーバがポートを使用している等という場合は、下の例のようにオプションを指定してあげます。ボクは Dify が別の Mac で動いていて、テキスト読み上げ (text-to-speech) サーバが動いていたりするので、それぞれを指定しています。オプションの詳細はmlx_lm --helpを見てください。--log-levelは付けなくても問題ありません。
mlx_lm.server --host 0.0.0.0 --port 8585 --log-level INFO
こんな表示が出れば動いているはずです。
% mlx_lm.server --host 0.0.0.0 --port 8585 --log-level INFO
/Users/handsome/Documents/Python/FastMLX/.venv/lib/python3.11/site-packages/mlx_lm/server.py:682: UserWarning: mlx_lm.server is not recommended for production as it only implements basic security checks.
warnings.warn(
2024-12-15 21:33:25,338 - INFO - Starting httpd at 0.0.0.0 on port 8585...
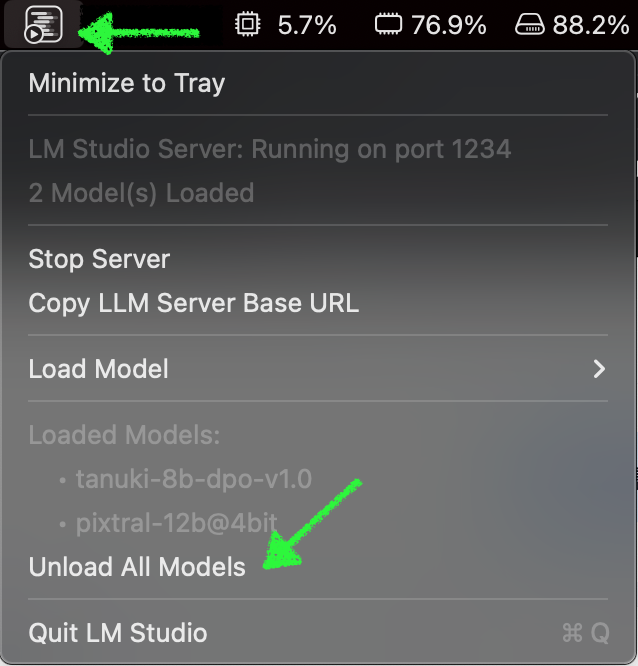
ダウンロードが完了したら Ctrl + C でサーバを一度終了します。あ、ちなみにこの方法でダウンロードしたモデルは、LM Studio からも読めますので、どちらも試す場合はコマンドで入れる方法が容量削減になります (ただしフォルダ名は人にきびしい)。
モデルを指定して API サーバを立ち上げる
モデルの保存場所は~/.cache/huggingface/hub/の中で、今回の例ではmodels--mlx-community--QwQ-32B-Preview-4bitというフォルダになります。サーバを立ち上げるコマンドに渡すパスはさらに深く、snapshotの中、config.jsonファイルが含まれるフォルダとなります。そちらを指定して API サーバを立ち上げるコマンドはこんな感じです:
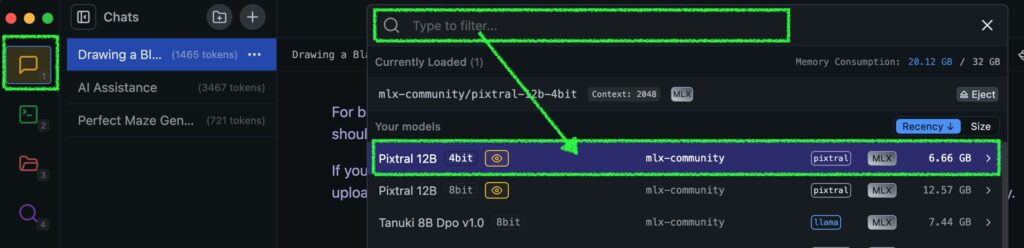
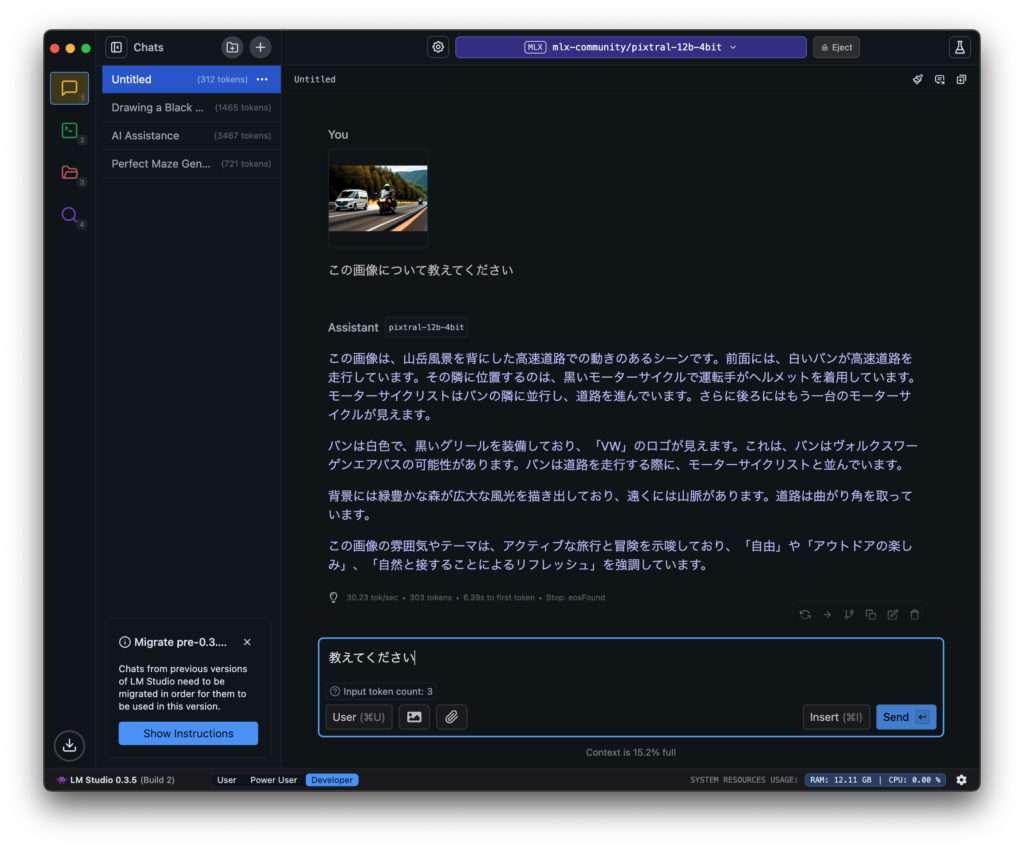
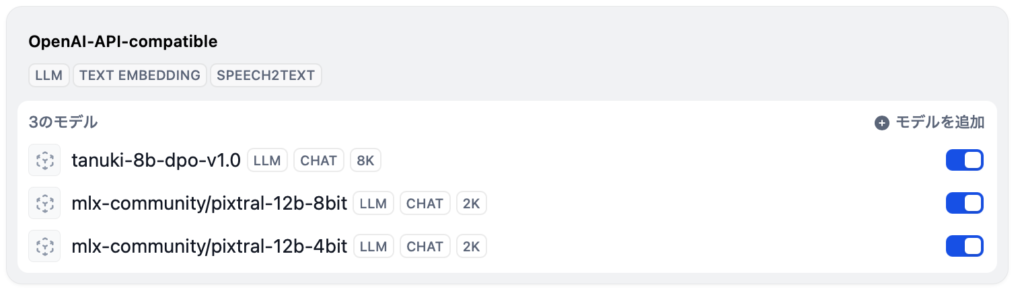
フランスの生成 AI 企業のトップである Mistral 社が、画像認識にも対応したマルチモーダル モデルの Pixtral 12B を Apache 2.0 ライセンスでリリースしています。画像を読み込ませると、何が映っているかを答えてくれるタイプの AI ですね。こちらを、ボク得意の Mac ローカルオンリー環境で実行した方法を共有します。今回使ったのは、LM Studio と Dify です。Pixtral を実行するだけなら LM Studio の 0.3.5 以上で OK ですが、Dify から API 経由で LM Studio を利用してみたので、後半にはその設定方法を紹介してます。
環境について
Mac
ボクの M2 Max Mac Studio には 32GB しか RAM が積まれていないので、Dify だけは別の M1 Mac Mini で動かしています。これから Mac (M4 搭載 Mac Mini とか MacBook Pro とかいいですな〜) を買う方でローカル LLM も試したいと考えている方は、頑張って 64GB 以上の RAM (ユニファイドメモリ) を搭載した機種を買いましょう。それより少ない RAM 容量で LLM を楽しむのはいろんな工夫や妥協が必要で苦労します。本ブログにはそんな切ない記事があふれています。
API サーバは、仮想環境内から以下コマンドで実行できます。モデルとトークナイザの読み込みに時間がかかります。
python server_speech_fastapi.py
しばらく待って、こうなれば準備完了です。
10-12 19:06:26 | DEBUG | __init__.py:130 | pyopenjtalk worker server started
10-12 19:06:27 | INFO | bert_models.py:92 | Loaded the Languages.JP BERT model from /Users/handsome/Documents/Python/Style-Bert-VITS2-Mac/bert/deberta-v2-large-japanese-char-wwm
10-12 19:06:27 | INFO | bert_models.py:154 | Loaded the Languages.JP BERT tokenizer from /Users/handsome/Documents/Python/Style-Bert-VITS2-Mac/bert/deberta-v2-large-japanese-char-wwm
10-12 19:06:27 |WARNING | tts_model.py:397 | No model files found in model_assets/.cache, so skip it
10-12 19:06:27 | INFO | server_speech_fastapi.py:116 | Loading models...
10-12 19:06:27 | INFO | server_speech_fastapi.py:123 | The maximum length of the text is 20000. If you want to change it, modify config.yml. Set limit to -1 to remove the limit.
10-12 19:06:27 |WARNING | server_speech_fastapi.py:129 | CORS allow_origins=['*']. If you don't want, modify config.yml
10-12 19:06:27 | INFO | server_speech_fastapi.py:338 | server listen: http://127.0.0.1:5055
10-12 19:06:27 | INFO | server_speech_fastapi.py:339 | API docs: http://127.0.0.1:5055/docs
10-12 19:06:27 | INFO | server_speech_fastapi.py:340 | Input text length limit: 20000. You can change it in server.limit in config.yml
[rank0]: File "/Users/handsome/Documents/Python/Style-Bert-VITS2-Mac/.venv/lib/python3.11/site-packages/torch/autograd/graph.py", line 825, in _engine_run_backward
[rank0]: return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
というわけで Mac ユーザの皆さん、ボクが MPS 化を完成させるのを待つよりも、地道に CPU で学習させた方が速いですよ。
Web UI にいる女子キャラや日本語が得意ということから、日本人の女の子をいくつか描かせたのですが全くイメージと違い、manga 調で競争している女子を描かせても顔が破綻していて多方面から怒られそうだったので、アプローチを全く変えました。深い森からやっと抜け出せた喜びと今の季節感を盛り込んだ、情緒的なトップ絵です。
Date: 2024年10月4日 23:12:07
Model: realisticVision-v51VAE_original_768x512_cn
Size: 768 x 512
Include in Image: photo realistic beautiful nature in the late summer. fresh air and sunshine
Mac で Dify と Ollama で作ったので、同環境でしかテストしていません。ただ、最適化バージョンと、見える化バージョンは、実質システムプロンプトのみなので、LM Studio 等の System Prompt を設定できる AI ツールを使っても簡単に利用できると思います。Ollama 単体でも template を書き換えるか、毎回質問するときに記入すれば同様のことは実現できるかもしれません。
app:
description: Llama3.1 が、質問を英訳し、推論し、日本語で返す、全てのプロセスを透明化したバージョン。冗長だが、英語の知識を使って回答していることがわかる。英語の勉強にもなるかも?
icon: two_men_holding_hands
icon_background: '#E4FBCC'
mode: advanced-chat
name: Llama3.1 英語で推論 (見える化バージョン)
use_icon_as_answer_icon: true
kind: app
version: 0.1.1
workflow:
conversation_variables: []
environment_variables: []
features:
file_upload:
image:
enabled: false
number_limits: 3
transfer_methods:
- local_file
- remote_url
opening_statement: ''
retriever_resource:
enabled: false
sensitive_word_avoidance:
enabled: false
speech_to_text:
enabled: false
suggested_questions: []
suggested_questions_after_answer:
enabled: true
text_to_speech:
enabled: false
language: ''
voice: ''
graph:
edges:
- data:
sourceType: start
targetType: llm
id: 1727270833994-llm
source: '1727270833994'
sourceHandle: source
target: llm
targetHandle: target
type: custom
- data:
sourceType: llm
targetType: answer
id: llm-answer
source: llm
sourceHandle: source
target: answer
targetHandle: target
type: custom
nodes:
- data:
desc: ''
selected: false
title: 開始
type: start
variables: []
height: 54
id: '1727270833994'
position:
x: 80
y: 282
positionAbsolute:
x: 80
y: 282
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
context:
enabled: false
variable_selector: []
desc: ''
memory:
role_prefix:
assistant: ''
user: ''
window:
enabled: false
size: 10
model:
completion_params:
keep_alive: 30m
num_ctx: 32768
temperature: 0.2
top_p: 0.2
mode: chat
name: llama3.1:8b-instruct-fp16
provider: ollama
prompt_template:
- id: 342e3642-d8b5-42c8-b003-7816a8ec7f3a
role: system
text: 'You are a skilled AI translator. Since your knowledge is best in
English, translate any question into English for inference and generate
answer. Follow the steps described below.
### Steps:
1. You translate {{#sys.query#}}directly into English. Try maintaining
the original format without omitting or adding any information.
2. Generate response in English.
3. Translate the response literary back into the language originally used
by the user and output.'
selected: true
title: LLM
type: llm
variables: []
vision:
enabled: false
height: 98
id: llm
position:
x: 381
y: 282
positionAbsolute:
x: 381
y: 282
selected: true
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
answer: '{{#llm.text#}}'
desc: ''
selected: false
title: 回答
type: answer
variables: []
height: 107
id: answer
position:
x: 680
y: 282
positionAbsolute:
x: 680
y: 282
sourcePosition: right
targetPosition: left
type: custom
width: 244
viewport:
x: -205
y: 134
zoom: 1
System prompt (LM Studio 等で使用する場合はこちらをどうぞ):
You are a skilled AI translator. Since your knowledge is best in English, translate any question into English for inference and generate answer. Follow the steps described below.
### Steps:
1. You translate the query directly into English. Try maintaining the original format without omitting or adding any information.
2. Generate response in English.
3. Translate the response literary back into the language originally used by the user and output.