

Ollama のこちらの issue に、MLX バックエンドのサポートをおねだりするコメントがたくさんあり、中には llama.cpp (GGUF) より 20~40% も高速という書き込みがあったのでお気に入りの QwQ-32B-Preview MLX 版を試してみました。OpenAI の o1 の様に試行錯誤を繰り返して回答の精度を高めるオープンなモデルです。結論から言うと、確かに少し速いです。該当のコメントを書き込んだ人は M3 ということなので、M4 を含んだ新しめチップ搭載 Mac ならもっと違いが実感できるのかもしれません。せっかくなのでやり方を残しておきます。
ところで、↓ これって Ollama 公式の X ポストなんですかね? Ollama で正式に MLX バックエンドがサポートされる匂わせとも取られています。
2025年6月22日追記: Ollama 0.9.2 でも MLX はサポートされていません。MLX と Ollama (GGUF) の簡単な比較を行った記事も書いたのでどうぞ:
MLX って?
ざっくり言うと、Apple 社純正の、Apple シリコン用機械学習フレームワークです。GPU だけではなく、CPU も使えるみたいです。性能は、100% というわけではなさそうなんですが、いろいろな実験をされた方々の記事を見てみると PyTorch で MPS を使用したときより速いというケースもあるらしいです。
MLX 公式 GitHub: https://ml-explore.github.io/mlx/build/html/index.html
詳細はブラウザの翻訳機能でも使って読んでください。Safari ならアドレスバーの右にあるこのアイコンで日本語に翻訳できます:
というわけで、「MLX 版 LLM」なんて呼んでいるのは、上記 MLX で動くように変換された、オープンな LLM のことです。
MLX-LM とは
MLX で動くように変換された LLM の実行環境です。言語モデルのみ対応しています。実行の他、Safetensor 形式 (HuggingFace にあるオリジナルのモデルはだいたいコレですね) を MLX 形式に変換したり、API サーバを実行する機能もあります。今回の記事では、API サーバとして利用する方法を紹介しています。
MLX-LM 公式 GitHub: https://github.com/ml-explore/mlx-examples/blob/main/llms/README.md
似たような実行環境に MLX-VLM というのもあり、こちらは Pixtral や Qwen2-VL 等のビジョンモデルに対応しています。
MLX-VLM 公式 GitHub: https://github.com/Blaizzy/mlx-vlm
上記二つの MLX-LM と MLX-VLM 両方の API サーバとして動作する FastMLX という Python パッケージもあり機能的には魅力的なのですが、ビジョンモデルは画像の URL かパスしか受け付けなかったり (Dify では使えない)、テキストのストリーミングがうまくいかず例外が出たりして結構工夫しないと使えなさそうなので、これまでのところくじけてます。興味がある方はどうぞ。
FastMLX 公式 GitHub: https://github.com/arcee-ai/fastmlx
LM Studio でも使えます
LM Studio は MLX モデルが使えるので、別に Dify 使わない・使っていないという方はこれ以上読み進めなくて大丈夫です。また、Dify には OpenAI API コンパチのモデルプロバイダとして LM Studio を登録して使うこともできますが、LLM からのレスポンスがなめらかにストリーミングされません。特に日本語の部分は結構な量がまとまって表示されるケースが多いです。なので、Dify から API で MLX の LLM を使うなら、MLX-ML のサーバ機能を利用するのが良いかと思います。
以下、内容はビジョンモデルですが、LM Studio の API を Dify から使う方法を別の記事にしてあるので参考にしてみてください。
MLX-LM で API サーバを立てる
インストール
MLX-LM を利用するには、まず仮想環境に MLX-LM をインストールしてください。今回使ったバージョンは、最新の0.20.4でした。
pip install mlx-lm一度サーバを立てる
サーバを立てるにはmlx_lm.serverコマンドを使用します (実コマンドはインストール時のハイフンと違いアンダースコアなので注意)。Dify (や他の API クライアント) が別のホストで動いているとか、他のサーバがポートを使用している等という場合は、下の例のようにオプションを指定してあげます。ボクは Dify が別の Mac で動いていて、テキスト読み上げ (text-to-speech) サーバが動いていたりするので、それぞれを指定しています。オプションの詳細はmlx_lm --helpを見てください。--log-levelは付けなくても問題ありません。
mlx_lm.server --host 0.0.0.0 --port 8585 --log-level INFOこんな表示が出れば動いているはずです。
% mlx_lm.server --host 0.0.0.0 --port 8585 --log-level INFO
/Users/handsome/Documents/Python/FastMLX/.venv/lib/python3.11/site-packages/mlx_lm/server.py:682: UserWarning: mlx_lm.server is not recommended for production as it only implements basic security checks.
warnings.warn(
2024-12-15 21:33:25,338 - INFO - Starting httpd at 0.0.0.0 on port 8585...モデルをダウンロードする
ボクの場合 32GB の RAM で動いてほしいので、4bit 量子化されたもの (18.44GB) を選んでいます。
HuggingFace: https://huggingface.co/mlx-community/QwQ-32B-Preview-4bit
MLX-LM サーバが動いている状態で別のターミナルウィンドウを開き、以下の様な簡単なスクリプト書いて保存し、Python で実行してモデルをダウンロードします。
import requests
url = "http://localhost:8585/v1/models"
params = {
"model_name": "mlx-community/QwQ-32B-Preview-4bit",
}
response = requests.post(url, params=params)
print(response.json())python add_models.pyダウンロードが完了したら Ctrl + C でサーバを一度終了します。あ、ちなみにこの方法でダウンロードしたモデルは、LM Studio からも読めますので、どちらも試す場合はコマンドで入れる方法が容量削減になります (ただしフォルダ名は人にきびしい)。
モデルを指定して API サーバを立ち上げる
モデルの保存場所は~/.cache/huggingface/hub/の中で、今回の例ではmodels--mlx-community--QwQ-32B-Preview-4bitというフォルダになります。サーバを立ち上げるコマンドに渡すパスはさらに深く、snapshotの中、config.jsonファイルが含まれるフォルダとなります。そちらを指定して API サーバを立ち上げるコマンドはこんな感じです:
mlx_lm.server --host 0.0.0.0 --port 8585 --model /Users/handsome/.cache/huggingface/hub/models--mlx-community--QwQ-32B-Preview-4bit/snapshots/e3bdc9322cb82a5f92c7277953f30764e8897f85無事にサーバが上がると、ブラウザからダウンロード済みモデルが確認できます: http://localhost:8585/v1/models
{"object": "list", "data": [{"id": "mlx-community/QwQ-32B-Preview-4bit", "object": "model", "created": 1734266953}, {"id": "mlx-community/Qwen2-VL-7B-Instruct-8bit", "object": "model", "created": 1734266953}]}
Dify に登録する
OpenAI-API コンパチブルのモデルとして登録
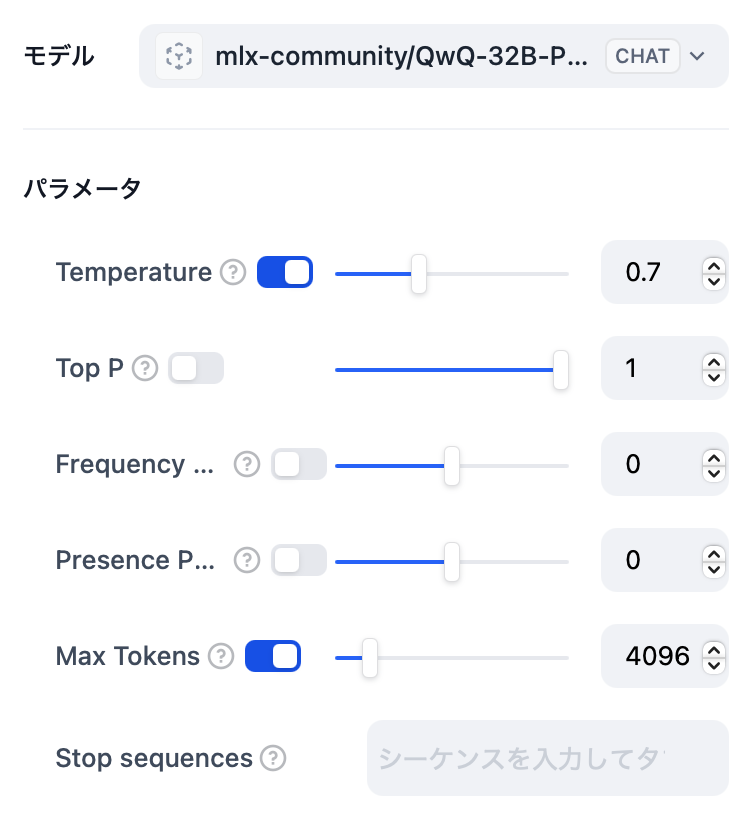
Dify へは、OpenAI-API-compatible の LLM モデルとして登録します。モデル名は上に度々登場しているもので、URL にはポートと /v1 が必要、Delimiter には適当に \n\n を入れるくらいで大丈夫だと思います。参考にスクリーンショットを貼っておきます。
Chatbot を作る
上記で登録したモデルを指定し、Max Tokens は 4096 あたりにします。この値であれば 32GB RAM でも 100% GPU で動きます。QwQ からの回答に中国語が混じるのを防ぐには、下の System プロンプトを使ってみてください。100% ではありませんが、効果はあります。
中国語は絶対に使わないでください。日本語の質問は常に日本語で答えてください。
While answering, never ever use Chinese. Always answer in Japanese or English based on language used.
さて、これで準備が整ったので、公開して実際に試してみましょう。
Dify では正確な数字での比較ができないが、体感は速い
さてこれで準備が整ったので、GGUF (ollama pull qwq:32b-preview-q4_K_M) と MLX を使った同じ条件のチャットボットを作り、同じ質問をいくつも投げて違いを見てみました。見た目は確かに MLX 版の方が文字の出力が速いです。ただ、Dify アプリのダッシュボードである「監視」での比較だと GGUF が 6トークン/秒くらいに対し、MLX が 18トークン/秒と 3倍速い結果になっていますが、実際にそこまでの違いはありません。個別のチャットのステータスが見れる「ログ&アナウンス」で確認できる経過時間とトークンの合計から算出すると、GGUF は大体 12トークン/秒くらいで、MLX は 35トークン/秒くらいとなるのですが、実際に出力されている文字数をざっと見比べてもそこまでの違いはありません。むしろ明らかに Ollama から多くの文字を受け取っているのに、MLX-LM から受け取ったトークン数の方が多くカウントされています。トークンの算出方法が違うのかもしれません。今回試しませんでしたが、英語でやると正確に調べられるかもしれません。また、単純に GGUF (llama.cpp) vs MLX-LM のガチンコ勝負をするなら、スクリプトを書いて比較するのが良いと思います。
追記: 本ブログの英訳記事を書く際に英語でテストを実施したところ、MLX の方が 30-50% 速い結果となりました。使ったプロンプトも載せてあります。
MLX-LM に乗り換えられるか?
QwQ や特定のモデル固定で構わないなら MLX-LM はアリだと思います。Mac の電源を切る習慣がある方は、別のブログ記事に書いたスクリプトエディタでアプリケーションを作る方法でログイン時に実行させれば勝手にモデルが使えるようにしてくれますし。でも、お手軽さと使いやすさでは Ollama の方が完全に上なので、複数のモデルをとっかえひっかえ使う方には向きません → MLX-LM でも LLM をとっかえひっかえできます (別記事「Alibaba 公式 MLX 版 Qwen3 を他の量子化版と比較」参照のこと)。上で触れた FastMLX はクライアント側からモデルの入れ替えができるようなので、本気で移行を考えるなら選択肢になり得るかと思います。ただ、Ollama 公式 X らしきポストを真に受けると、MLX 対応しそうな感じもあるので、どちらかと言えばそれ待ちですね。いずれにせよ、今回の GGUF vs MLX の趣旨とは外れますが、個人的に QwQ の出力速度はチャットベースであれば十分です。用途に応じて試してみてください。
Image by Stable Diffusion
「リンゴの上で走るロボット」をお願いしたのですが、big apple だと NYC になり、huge apple とすると、そんなものないとガン無視されました。というわけでこんな感じで手を打ちました。日本人の持つ「かわいいロボット」という感覚は西洋にはなさそうです
Date:
2024年12月16日 0:38:20
Model:
realisticVision-v51VAE_original_768x512_cn
Size:
768 x 512
Include in Image:
fancy illustration, comic style, smart robot running on a huge apple
Exclude from Image:
Seed:
2791567837
Steps:
26
Guidance Scale:
20.0
Scheduler:
DPM-Solver++
ML Compute Unit:
CPU & GPU