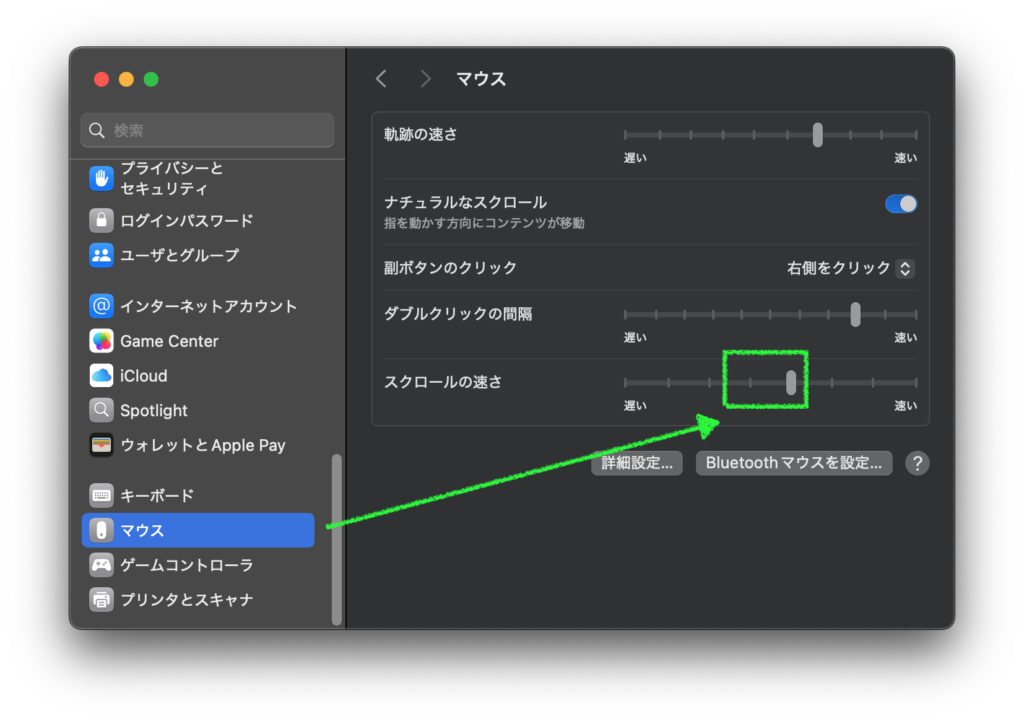
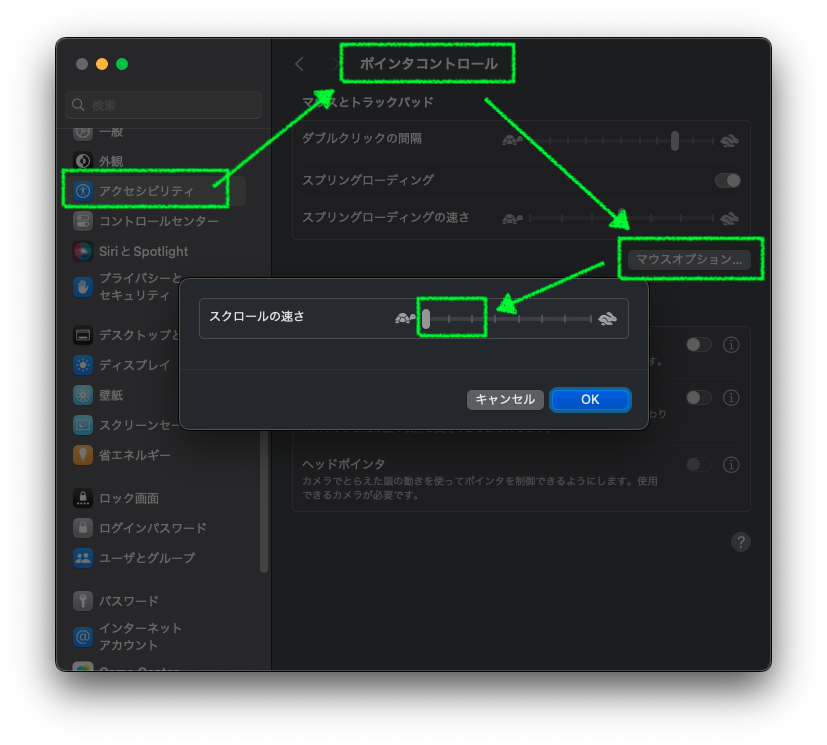
ボクの場合、一つのマウスを仕事用の Windows と Mac で使っていますが、Windows では全く発生したことが無かったことから、汚れ、ハードウェアの不具合、電池の消耗等は除外していました。ふと昔から Mac はマウスの解像度が高かったということを思いだし、ホイールのスクロールの速度を下げたことが功を奏しました。スクリーンショットの位置に変更した後、タイトルの不具合は一度も発生していません。もちろん Google 先生にも相談しましたが、役立つ情報はありませんでした。
API サーバは、仮想環境内から以下コマンドで実行できます。モデルとトークナイザの読み込みに時間がかかります。
python server_speech_fastapi.py
しばらく待って、こうなれば準備完了です。
10-12 19:06:26 | DEBUG | __init__.py:130 | pyopenjtalk worker server started
10-12 19:06:27 | INFO | bert_models.py:92 | Loaded the Languages.JP BERT model from /Users/handsome/Documents/Python/Style-Bert-VITS2-Mac/bert/deberta-v2-large-japanese-char-wwm
10-12 19:06:27 | INFO | bert_models.py:154 | Loaded the Languages.JP BERT tokenizer from /Users/handsome/Documents/Python/Style-Bert-VITS2-Mac/bert/deberta-v2-large-japanese-char-wwm
10-12 19:06:27 |WARNING | tts_model.py:397 | No model files found in model_assets/.cache, so skip it
10-12 19:06:27 | INFO | server_speech_fastapi.py:116 | Loading models...
10-12 19:06:27 | INFO | server_speech_fastapi.py:123 | The maximum length of the text is 20000. If you want to change it, modify config.yml. Set limit to -1 to remove the limit.
10-12 19:06:27 |WARNING | server_speech_fastapi.py:129 | CORS allow_origins=['*']. If you don't want, modify config.yml
10-12 19:06:27 | INFO | server_speech_fastapi.py:338 | server listen: http://127.0.0.1:5055
10-12 19:06:27 | INFO | server_speech_fastapi.py:339 | API docs: http://127.0.0.1:5055/docs
10-12 19:06:27 | INFO | server_speech_fastapi.py:340 | Input text length limit: 20000. You can change it in server.limit in config.yml
[rank0]: File "/Users/handsome/Documents/Python/Style-Bert-VITS2-Mac/.venv/lib/python3.11/site-packages/torch/autograd/graph.py", line 825, in _engine_run_backward
[rank0]: return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
[rank0]: ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
[rank0]: RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
というわけで Mac ユーザの皆さん、ボクが MPS 化を完成させるのを待つよりも、地道に CPU で学習させた方が速いですよ。
Web UI にいる女子キャラや日本語が得意ということから、日本人の女の子をいくつか描かせたのですが全くイメージと違い、manga 調で競争している女子を描かせても顔が破綻していて多方面から怒られそうだったので、アプローチを全く変えました。深い森からやっと抜け出せた喜びと今の季節感を盛り込んだ、情緒的なトップ絵です。
Date: 2024年10月4日 23:12:07
Model: realisticVision-v51VAE_original_768x512_cn
Size: 768 x 512
Include in Image: photo realistic beautiful nature in the late summer. fresh air and sunshine